As long as philosophy is concerned, ontologies are meant to distinguish between realms of knowledge and their description through languages.

And yet, most present-day ontologies overlook that distinction, and consequently confuse the nature of objects and phenomenons (concrete or symbolic) with the open-ended range of their representations by human minds.
Related readings
- Ontological Prisms for beginners
- Ontological Prisms & The Geometry of Knowledge
- Enterprise’s New Brains
- Knowledge Engineering with Ontological Prisms (KEOPS)
Preamble
Ontologies & Enterprises
Ontologies are vessels meant to organize knowledge. At enterprise level they can be developed from three sources: conceptual Models, databases schemas, or facts (observations, datasets), and documents.

Ontological prisms are designed to be pragmatic and agnostic. Pragmatic, in order to avoid definitional debates about the nature of ontologies and to focus on how they can be constructed and utilized. Agnostic, in that they support ontologies regardless of representations semantics and lifecycles.
Ontologies & Knowledge
From a functional perspective the kernel is to meet the principles of knowledge representation set by Davis, Shrobe, and Szolovits in their seminal article:
- Surrogate: KR provides a symbolic counterpart of actual objects, events and relationships.
- Ontological commitments: a KR is a set of statements about the categories of things that may exist in the domain under consideration.
- Fragmentary theory of intelligent reasoning: a KR is a model of what the things can do or can be done with.
- Medium for efficient computation: making knowledge understandable by computers is a necessary step for any learning curve.
- Medium for human expression: one the KR prerequisite is to improve the communication between specific domain experts on one hand, generic knowledge managers on the other hand.
Traditional models can support points 1, 4 and 5, but fall short of points 2 and 3. Ontologies are meant to generalize the representation of and reasoning about any number of realms, actual or virtual. The aim of the kernel is to bring under a common roof the whole of representations pertaining to enterprises governance.

Ontologies & Language
Language has always been the underlying subtext of artificial intelligence (AI), whether it’s for implementation (computer languages), communication (user interfaces), or truthfulness (knowledge representation). The comprehensive surge of generative language models (GenLMs) has created a new and powerful momentum that blends communication and representation. The confusion between language and knowledge is further reinforced by the ubiquity of knowledge graphs, which are viewed indiscriminately as both content and containers. Ontological prisms unfold the two roles of languages, communication and representation, allowing for the mapping of semantic layers with knowledge shapes.

Kernel Organization
Categories
Categories are first defined in line with established notions of objects, agents, activities, events, locations. They are further refined with regard to the nature of instances (actual or symbolic), and the source of their identification (internal or external). In line with established semantics, abstract categories (≈) are ones that cannot be instantiated on their own.
OWL 2 hierarchies (yellow lines) are used to organize entries on a conceptual basis while remaining neutral with regard to abstraction semantics. For example, systems are defined in terms of agent and artifacts without any assumption regarding inheritance.
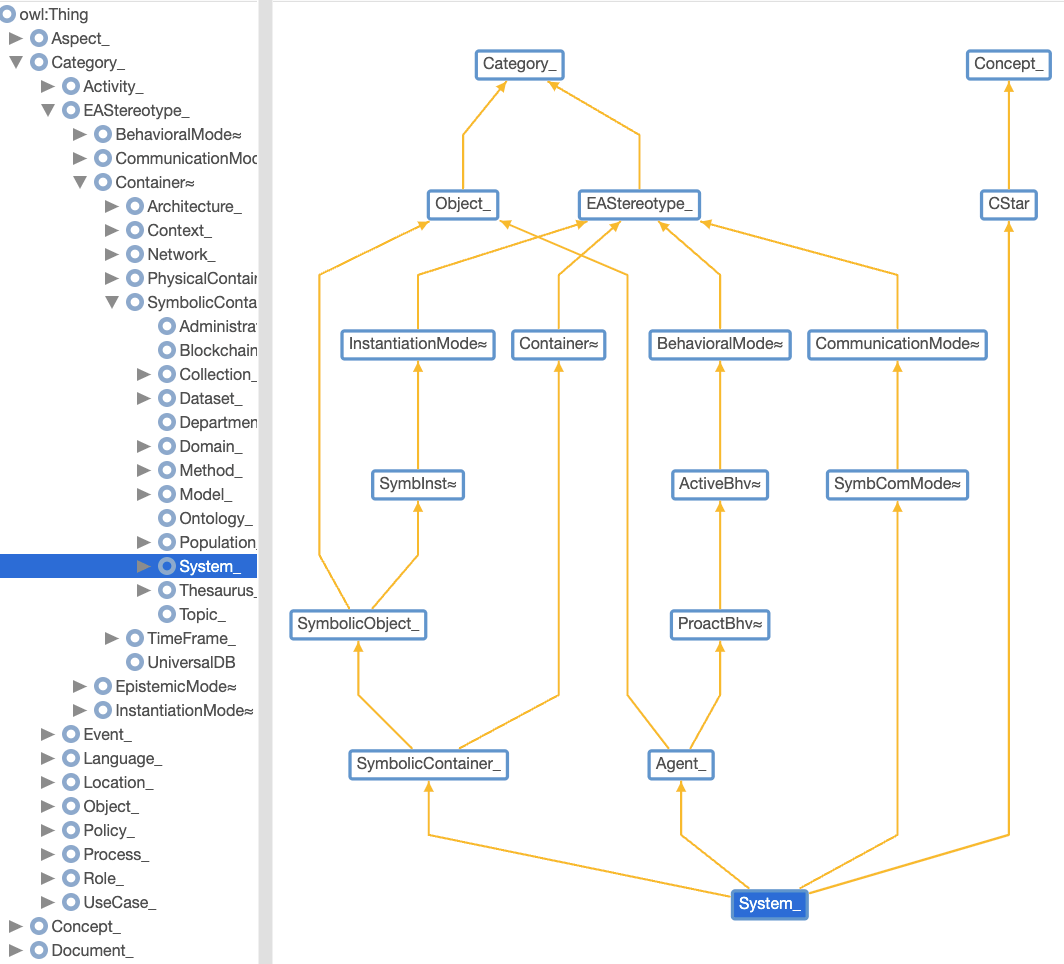
Aspects & Properties
Descriptions without external instances of their own: aspects cannot be directly instantiated (or identified) in environments; they can only exist as digital components in systems. Since they are not meant to directly represent individuals in domains, aspects can be defined in terms of standard generic of functional constructs, ensuring interoperability with modeling languages:
- Features (Properties and operations).
- Numeric and logic expressions.
- Abstract data types (collections, graphs, …)
- States (lifecycles)
With OWL 2, the kernel defines aspects in the Class hierarchy, but connectors are defined as object properties, and attributes as data properties.



Contrary to categories, whose instances are to be checked for external consistency, aspects have only to be checked for internal consistency.
Kernel properties
Connectors being the glue of knowledge, their semantics is to make the difference. On that account, the primary objective should be to set apart thesaurus and modeling connectors from ontological ones. That can be achieved through linguistic layers.

Syntax Connectors
Syntactic connectors are set at the representation level independently of semantics and pragmatics. Generic ones coincide with established modeling standards for collections, aggregates, and compositions; they are meant to be executable and support truth-preserving operations independently of domain semantics.
Category Connectors
Category connectors apply to descriptions: categories, types, classes, etc.
- Structure connectors (include_) deal with composition
- Variant connectors deal with functional (extendedBy_, extensionOf_) and structural (subset_, subsetOf_) hierarchies
- Sorting connectors (sortedBy_) deal with partitions


Instance Connectors
Instance connectors apply to the representation of individuals, i.e., identified occurrences of objects (connectRefer_) or behavior (connectExec_) descriptions.

Semantic Connectors
Semantic connectors deal with the specifics of business domain and enterprise architecture. The kernel comes with a basic set of architecture and engineering connectors.
Architecture Connectors
Architecture connectors are meant to describe functional and technical capabilities and dependencies independently of business domains semantics:
- Interdependencies between capabilities at the enterprise level: roles, objects, activities, locations, events and processes.
- References between symbolic representations.
- Flows between activities: passive symbolic or actual content, or active requests.
- Dependencies between processes execution.
- Communication channels between objects or locations according to capabilities: physical, digital, or symbolic.
Engineering Connectors
Beside the representation of standard engineering flows (refObjective_, refResource_, refOutcome_), the kernel introduces ontological connectors to deal with the mapping of representations across epistemic levels:
- Between symbolic representations within organizations (realizeX_)
- Between symbolic or non-symbolic external objects or phenomena and their symbolic counterpart within organizations (mapTerritX_)
Ontology Connectors
Ontology connectors are meant to bring together the whole range of representations.
Axioms
To be ecumenical and ensure perennial conceptual interoperability across domains and organizations, definitions are built on a limited set of unambiguous and effective axioms:
- Limited: since axioms serve as roots to acyclic semantic graphs, there should be as few axioms as possible.
- Unambiguous: axioms are meant to be either accepted or rejected, which implies that their meaning should be clear and leave no wiggle room for misunderstanding.
- Effective: the axioms singled out are not meant to be the pillars of some absolute truth, but rather to serve as logical hubs for sound and effective EA categories. They should therefore only be judged on their effectiveness in supporting clear and concise EA definitions.
Taking exemple on music keys, and assuming standard logic, ten axiomatic definitions are introduced as modeling primitives:

Instances
Physical, digital, or symbolic occurrences of objects or phenomena (both accepted as postulates): The distinction between physical, digital, and symbolic instances is not exclusive (consider hybrids); additionally, fictional instances are instances (physical or symbolic) that are not meant to be realized. Instances are represented by individuals in OWL.
Attributes
Characteristics of instances that belong to them and make them recognisable.
Collection
Set of individuals managed uniformly, independently of their nature.
Identity
Unique value associated with individuals: External identities are defined independently of the organization or system under consideration. External identities can be biological, social, or designed; they are not exclusive (e.g., social security number and fingerprints). Internal identities are used to manage individuals within organizations or systems independently of environments.
Symbolic Representations
Borrowing from semiotics:
- A symbol is a sign pointing to something else (referent).
- A symbolic representation is a symbol pointing to a set of instances.
- A symbolic object is an object representing a referent; this means that symbolic objects can be physical, as they usually are.
Behavior
The ability of an instance to change the state of instances, including itself: Objects are either active (with behavior) or passive (without behavior), and the propriety is exclusive.
State
Named sets of values that characterize instances of objects (actual or symbolic), processes, or representations, between events. Stateful objects and activities come with a finite number of discrete states; stateless ones don’t have this limited array, and may indeed have an infinite number of discrete states.
Event
Change in the state of objects and phenomena: External events are changes triggered from outside the organization or system under consideration.
Thesaurus Connectors
Axioms serve as roots and firebreaks in acyclic semantic networks of definitions. Axiomatic definitions are not meant to be “true,” comprehensive, or exclusive; but rather, effective (to make a difference), as simple as possible (Occam’s razor), and open to refutation.
Basic ones (thesaurusBw_ and thesaurusFw_) put the focus on semantic dependencies, ensuring that there is no circular definitions. Semiotic ones deal mirror OWL2 references for synonyms, homonyms, and antonyms.

Combined with OWL 2 hierarchies, these semantic networks constitute the kernel of the thesaurus, which can then be fleshed out to build EA Knowledge graphs.
Given the layered organization (axioms and acyclic networks for semantics, and graphs for EA knowledge), consistency checks can be formal with regard to the kernel (e.g., no circular definitions), but pragmatic and customized with regard to EA definitions.
Inference Connectors
Inference connectors provide a basic set of logic operators, to be fully implemented through OWL 2 properties assertions:
- Universal (infUQuantifier_), existential (infEQuantifier_) and negative infNQuantifier_) quantifiers
- Forward and backward nondescript inferences
- Inferences from analogies (infAnalogy_ and contiguities (infContiguity_)
Combined with partitions and powertypes, inference connectors can be used at domain or category level.



Combined with composition and reference connectors inference ones can also be used to define business logic, e.g.:
- Constraints on bank accounts’ overdrafts
- Data-driven (pull) rule: If (overdraft) Do (notification)
- Event-driven (push) rule: When (forcible entry) Do (trigger alarm)



Annotations properties
Beside basic modeling annotations for interoperability, the kernel introduces ontological ones to characterize epistemic modalities:
- Temporal: Past, present, planned, expected
- Existential: Prohibited, impossible, permitted, possible, mandatory, necessary, exempted, elective
- Narrative: Actual, virtual, fictional
Kernel Integration
The primary aim of ontologies is to bring under a single roof three tiers of representations and to ensure both their autonomy and integrated usage:
- Thesauruses federate meanings across digital (observations) and business (analysis) environments
- Models deal with the integration of digital flows (environments) and symbolic representations (systems)
- Ontologies ensure the integration of enterprises’ data, information, and knowledge, enabling a long-term alignment of enterprises’ organization, systems, and business objectives
From a technical perspective the consistency and interoperability of those tiers can be achieved using graphical neural networks (GNN) and Resource description framework (RDF).

From a functional perspective ontologies must support the strategic alignment of enterprises’ business objectives and architectures materialized by operations and organization.

To provide a basis to user access the kernel comes with a number of generic filters:
- Negative filters operate on nodes and are used to mask root categories, e.g.: xActivities, xObjects
- Basic hierarchy filters (1,2,3) operate selectively on OWL subclass and instance properties
- Hierarchy4 filter operates on kernel variant properties, e.g.: subset_, extendedby_
- Association and composition filters operate selectively on structural (include_) and functional (connectRef_, connectExe_) kernel properties
- Thesauruses and inference connectors operate selectively on semiotic and reasoning kernel properties
These filters can be used to define integrated views according to perspective.

Thesauruses & Ontologies
Contrary to a naive understanding, there can be no universal attachment of words to reality, even for concrete objects; and business affairs are generally more symbolic than actual. For enterprises’ ontologies the primary objective is therefore to manage the various meanings associated with environments’ objects and phenomena whatever their nature (concrete or symbolic) and naming source (external or internal). That’s the role of thesauruses.
- From a business perpective, thesauruses are used to attach names to data taking into account the specificities of business domains and the heterogeneity of sources. The focus is put on the federation of data semantics across sources and business domains (data meshes).
- From a system perspective thesauruses are used to map named data to their employ by applications and functions. The focus is put on the consolidation of business domains’ semantics and shared resources, meta-data, and master data management (MDM).
The integration of thesauruses within ontologies can be achieved through their refactoring as semantic networks and the replacement of semantic connectors (aka connecting nodes) with syntactic ones, e.g.:

Removing semantics from connectors between thesauruses nodes has two consequences:
- Syntactic connectors can only be interpreted in business specific contexts
- They can be uniformly defined as to ensure syntactic interoperability across modeling languages
The benefits of such normalized thesauruses can be demonstrated by their integration with Entity-relationship (E/R) and Relational data models.
Models & Ontologies
Whereas thesauruses put the focus on meanings, i.e. the attachment of words to facts and ideas, the primary objective of models is to manage representations:
- From a business perspective, models are used to define processes and plan for changes in environments
- From a system perspective, they are used to define architectures and support engineering (MBSE).
But facts are not manna ready to be picked: to ensure a perennial and consistent representation of objects and phenomena observations must be structured and put into contexts; that is done by adding syntax (for structures) and semantics (for contexts and concerns). Models can then serve to align enterprises’ environments and objectives on the one hand, organization and supporting systems on the other hand.
Identities, Structures, Aspects
The distinction between thesauruses and models takes a particular importance for enterprises immersed in digital environments as it marks the limit between unregulated concerns (the meanings of words) and regulated ones (business objects), with models serving as gate keepers between observed data and managed information. To that effect models must extend thesauruses with identities and structures:
- Since representations are meant to associate concepts or categories (as defined in thesauruses) to sets of objects or phenomenas, some principle is required to identify relevant individuals.
- Then, a distinction must be maintained between intrinsic (or structural) features of individuals on the one hand, and functional or behavioural ones on the second hand.
- Finally, constraints must be added with regard to the structural and functional integrity of representations.
Leading modeling languages (E/R, Relational, and OO) come with the relevant syntactic constructs and the objective of the kernel connectors defined above is to provide a common unambiguous subset.


Assuming homogenous domains for identification and semantics, transitions from normalized thesauruses to models would be straightforward using ontological connectors. Not so for abstractions defined in thesauruses.
Semantics & Abstractions
As long as abstractions are about meanings they can be understood in terms of “kind of” or “is a” relationships without actual consequences. That’s the way abstractions are represented in OWL2 (yellow color). But that understanding falls short if abstractions are applied to representations, as they are supposed to be in models. In that cases semantics are meant to vary with the kind of abstraction:
- Conceptual, as defined in thesauruses (yellow color)
- Structural and functional, represented by subsets and extensions respectively (blue color)
Thesauruses should thus be extended as to take into account the semantics of structural and functional abstractions; that is done with the subset_ and extend_ connectors, respectively.



One step further, thesauruses could include explicit partitions (sortedBy_) that would directly translate as modeling powertypes, to be realized through instances (MusicInstr2Source) or subtypes (MusicInstr2Function).
That unified representation of abstractions in terms of subtypes and instances ensures a seamless integration of models within ontologies.
Ontologies & Knowledge
To get a competitive edge in digital environments, enterprises have to read through a massive and continuous flow of data and information, a task that involves three intertwined undertakings:
- Reducing uncertainty (observation): facts are not manna from heaven ready to be observed but have to be mined from qualified data.
- Determining causal chains (orientation): while predicate logic and statistical inference may suffice with single root causes, they may lose their way in causal mazes.
- Managing risks (decision): since business competition is by nature a time- dependent, nonzero-sum game, decision-making processes must weigh orientations with a dynamic assessment of risks, and balance business opportunities with the sustainability of architectural assets.
Sorting out these undertakings into manageable threads can be best achieved through iterations of the OODA loop backed by ontologies integrating forms (thesauruses, models, graphs), contents (data, information, knowledge), and functions (observation, reasoning, decision-making).

Observation: From Data to information:
The raison d’être of ontologies is to make explicit the relationship between languages and what they denote; for enterprises trying to make sense of continuous and massive flows of observations, using ontologies removes a double delusion:
- The implicit assumption that meanings can be extracted from raw data like gold nuggets from river beds independently of customary contexts and purposes
- The explicit assumption that concepts can be organized into final and universal hierarchies
Machine learning is used to make sense of unstructured observations obtained from environments (Data mining) and operations (Process mining). Put simply, the objective is to map data into hypothetical categories in combining three operations: identification of relevant items, definition of boxes, assessment and improvement of mappings. Optimized boxes can thus translate into meaningful categories used to build information models.


That twofold undertaking corresponds to the distinction between data analytics and data analysis, the former for marketing data (e.g. profiles of anonymous music listeners), the latter for managed information (e.g., ticket sales). It also corresponds to key governance distinctions:
- Between unregulated observations and regulated managed information
- Between the intrinsic uncertainties of observations and the necessary reliability of models
Knowledge graphs are introduced to manage the transitions, e.g. to explore opportunities or define strategies.
Orientation: From information to knowledge
Beside their role as backbone and glue, knowledge graphs add two key capabilities to thesauruses and models:
- Built-in epistemic levels of representation, e.g., actual, virtual, planned, expected, etc.
- Reasoning capabilities, in particular with regard with modal logic and traceability.
Epistemic Levels
Being limited to meanings, thesauruses can only deal with logical inferences, not with inferred realms. Similarly, while modeling domains can be used to manage different kinds of contexts, their integration must be done through programming, as illustrated by the Ubiquitous language (UL) of Domain driven design (DDD).
Hence the need to manage resources (data and information) according to their nature while ensuring the integration of truth-preserving and heuristic processing. That can be achieved by adding logic connectors and reasoning patterns to models, establishing a bridge between epistemic levels.
Taking the Parent/Children exemple, logic can deal with the fact that persons have parents, and models can represent corresponding individuals and relationships, e.g.:
- Entity Person_ with instance Mike,
- Role Parent() with standard connector (connectRef#_)
- Logical connector (infUQuantifier_) for universal constraint
But unidentified instances and associated relationships cannot be explicitly represented by models; to that end epistemic levels are needed, e.g.:
- Mike‘s deduced instance of Parent() with standard connector (connectRef_)
- Induced (not observed) instance JDoe of Person_
- Unidentified connector (connectRef?_) for Mike’s physical parent

That simple exemple illustrates the significance of epistemic levels with regard to the distinction between data (JDoe) and information (Mike), and its benefits with regard to the management of privacy regulations.
Reasoning Capabilities
In principle, reasoning with models can be achieved through computation (functions), deduction (dependencies), and induction (statistics). In practice the benefits are limited by the lack of epistemic levels
Decision: Collective Knowledge & Organization
If anything, the ultimate benefit of ontologies is to enable the weaving of individual knowledge threads into a collective fabric mixing systems and organizational capabilities.
That pivot from learning (individual and collective knowledge) to decision- making (individual accountability) is arguably a critical issue for organizations.
Further Reading
- Ontologies & Models
- Conceptual Models & Abstraction Scales
- Models & Meta-models
- Ontologies & Enterprise Architecture
- Ontologies as Productive Assets
- Modeling Paradigm
- Views, Models, & Architectures
- Abstraction Based Systems Engineering
- The Cases for Reuse
- The Economics of Reuse
- Focus: Requirements Reuse
- Projects as non-zero sum games
- Projects Have to Liaise
- Caminao & EACOE
- EA & MDA
- EA: The Matter of Layers
- EA: Maps & Territories
- EA: Work Units & Workflows
- Models Transformation & Agile Development
External Links
- Stanford Knowledge Systems Laboratory: “What is an Ontology ?”
- John F. Sowa, “Ontology“
- Davis, Shrobe, and Szolovits: “What is Knowledge Representation“
- OWL Overview
- gUFO: A Lightweight Implementation of the Unified Foundational Ontology (UFO)
- FacetOntology: Expressive Descriptions of Facets in the Semantic Web
- Zachman Framework As Enterprise Architecture Ontology – SlideShare
- Why the Zachman Framework is not an ontology – Inside Architecture
- Semantic Web Case Studies and Use Cases
- Ontotext
- FacetOntology Tetherless World Constellation (TWC)
- Vehicle Sales Ontology
- Ontology for Innovation
- Ontology for eCommerce
- W3C: Concepts and Abstract Syntax
- M. Galkin, Graph ML in 2022: Where are we now?
- Cross-industry semantic interoperability, part three: The role of a top-level ontology
- Zhamak Dehghani, Data Mesh Principles and Logical Architecture