Even when code is directly developed from requirements, software engineering can be seen as a process of transformation from a source model (e.g requirements) to a target one (e.g program). More generally, there will be intermediate artifacts with development combining automated operations with tasks involving some decision-making. Given the importance of knowledge management in decision-making, it should also be considered as a primary factor for model transformation.
What has been transformed, added, abstracted ? (Velazquez-Picasso)
Clearing Taxonomy Thickets
Beside purpose, models transformation is often considered with regard to automation or abstraction level.
Classifying transformations with regard to automation is at best redundant, inconsistent and confusing otherwise: on one side of the argument, assuming a “manual transformation” entails some “intelligent design”, it ensues that it cannot be automated; but, on the other side of the argument, if manual operations can be automated, the distinction between manual and automated is pointless. And in any case a critical aspect has been ignored, namely what is the added value of a transformation.
Classifying transformations with regard to abstraction levels is also problematic because, as famously illustrated above, there are too many understandings of what those levels may be. Considering for instance analysis and design models; they are usually meant to deal respectively with system functionalities and implementation. But it doesn’t ensue that the former is more abstract than the latter because system functionalities may describe low-level physical devices and system designs may include high level abstract constructs.
A Taxonomy of Purposes
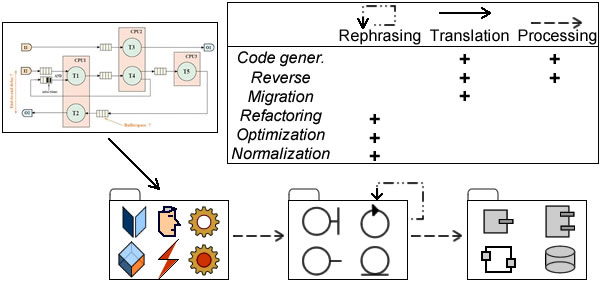
Depending on purpose, model transformation can be set in three main categories:
Translation: source and target models describe the same contents with different languages.
Rephrasing: improvement of the initial descriptions using the same language.
Processing: source and target models describe successive steps along the development process. While they may be expressed with different languages, the objective is to transform model contents.
Translation, Rephrasing, Processing.
Should those different purposes be achieved using common mechanisms, or should they be supported by specific ones ?
A Taxonomy of Knowledge
As already noted, automated transformation is taken as a working assumption and the whole process is meant to be governed by rules. And if purpose is used as primary determinant, those rules should be classified with regard of the knowledge to be considered:
Syntactic knowledge would be needed to rephrase words and constructs without any change in content or language.
Thesaurus and semantics would be employed to translate contents into another language.
Stereotypes, Patterns, and engineering practices would be used to process source models into target ones.
Knowledge with regard to transformation purposes
On that basis, the next step is to consider the functional architecture of transformation, in particular with regard to supporting knowledge.
Procedural vs Declarative KM
Assuming transformation processes devoid of any decision-making, all relevant knowledge can be documented either directly in rules (procedural approach) or indirectly in models (declarative approach).
To begin with, all approaches have to manage knowledge about languages principles (ML) and the modeling languages used for source (MLsrc) and target (MLtrg) models. Depending on language, linguistic knowledge can combine syntactic and semantic layers, or distinguish between them.
Meta-models can be structured along linguistic layers or combine syntax and semantics.
Given exponential growth of complexity, procedural approaches are better suited for the processing of unstructured knowledge, while declarative ones are the option of choice when knowledge is organized along layers.
When applied to model transformation, procedural solutions use tables (MLT) to document the mappings between language constructs, and programs to define and combine transformation rules. Such approaches work well enough for detailed rules targeting specific domains, but fall short when some kind of generalization is needed; moreover, in the absence of distinction at language level (see UML and users’ concerns), any contents differentiation in source models (Msrc) will be blurred in target ones (Mtrg) .
Transformation Policies: Procedural vs Declarative
And filtering out noise appears to be the main challenge of model processing, especially when even localized taints or ambiguities in source models may contaminate the whole of target ones; hence the benefit of setting apart layers of source models according their nature and reliability.
That can be achieved with the modularity of declarative solutions, with transformations carried out separately according the nature of knowledge: syntactic, semantic, or engineering. While declarative solutions also rely on rules, those rules can be managed according to:
Purpose: rephrasing, translation, or development.
Knowledge level: rules about facts, categories, or reasoning.
Robustness: how to deal with incomplete, noisy, or inconsistent models.
Modularity, reusability: how to customize, combine, or generalize transformations.
In principle declarative approaches are generally seen as superior to procedural ones due to the benefits of a clear-cut separation between the different domains of knowledge on one hand, and the programs performing the transformations on the other hand:
The complexity of transformations increases exponentially with the number of rules, independently of the corpus of knowledge.
The ensuing spaghetti syndrome rapidly downgrades transparency, traceability, and reliability of rules which, in procedural approaches, are the only gate to knowledge itself.
Adding specific rules in order to deal with incomplete or inconsistent models significantly degrades modularity and reusability, with the leveraging impact of new rules having to be added for every variant.
In practice the flaws of procedural approaches can be partially curbed providing that:
Rules apply to a closely controlled domain.
Models are built with complete, unambiguous and consistent languages.
Both conditions can be met with domain specific languages (DSLs) and document based ones (e.g XML) targeting design and program models within well-defined business domains.
Compared with the diversity and specificity of procedural solutions, the extent of declarative ones have been checked by their more theoretically demanding requirements, principally met by relational models. Yet, the Model Driven Architecture (MDA) distinction between computation independent (CIMs), platform independent (PIMs), and platform specific (PSMs) models could provide the basis for a generalization of knowledge-based model transformation.




Reblogged this on healthcare software solutions lava kafle kathmandu nepal.