“A brain can improve till it fits its environment”
William Ross Ashby

Preamble
The buzz around digital transformation may be belated as well as misguided. Belated because unbroken digitized business flows mean that the transformation is already a reality; misguided because what is at stake is not so much data as the embedding of enterprises into environments.
On that account, the aim of digital transformation should be to weave all enterprise processes around digital flows: data (environment’s facts), processed into information (systems’ symbolic representations), to be put to use as knowledge (enterprise behavior).
Symbolic Processing & Architectures Capabilities
The digital transformation of business environments bears out the Symbolic System modeling paradigm, bringing back a cybernetics perspective: to maintain a competitive edge enterprises have to keep a relevant, accurate, and up-to-date representation of their business context and concerns.
To that end digital transformations must be carried out across enterprise capabilities, from business intelligence and operations to knowledge management and strategic planning:
- First, a comprehensive and continuous capture, filter, and refining of business data flows at application level.
- Then, the transformation of these streams into information assets. That is to entail a transformations of systems functionalities.
- Finally, organization and business processes are to be transformed in order to reap the benefits of knowledge-oriented architectures.
Assuming that transformations are made on purpose, they should be traced to observed or expected changes in environments, business ones affecting organization and processes, and technology ones affecting applications and platforms.
For these transformations to pervade enterprise governance and improve performances, they should aim to the integration of systems and knowledge architectures; that can be epitomized by the Pagoda blueprint with its central pillar supporting platforms, systems, and organizational layers.
Like the spinal cord of enterprise nervous systems, the central pillar is to support:
- A clear distinction between the flows of raw data and information (previously known as data) models supporting the continuity and consistency of systems.
- The structural and semantic mapping of refined business data flows to information models and systems functions.
- The business driven integration of processes, organization and models in support of operational and strategic decision-making.
Knowledge architecture could then provide a conceptual frame common to enterprises and environments descriptions, paving the way to their in-depth transformation.
Data, Information, Knowledge
Taking a leaf from Stafford Beer’s view of enterprises as viable systems, the primary objective of digital transformation is to enable their continuous and timely adaptation to their environment, in other words to limit the entropy of enterprises embedded in digital environments. To that effect, transformations are to be carried out through architectures (system and knowledge) levels:
- Data associated with the perception of individuals objects or phenomena (technical architecture)).
- Information built by grouping instances into categories and associated reasoning (functional architecture).
- Knowledge acquired by putting information into use (organization).
Insofar as systems are concerned, it means a symbolic description of categories and representation of instances (maps), and their consistent and continuous anchoring to actual environments (territories):
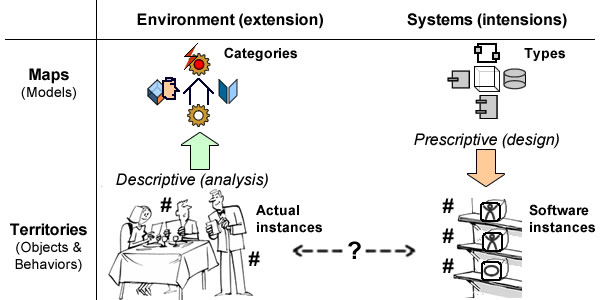
- Individuals: systems representations are to be anchored to their environment through identified (#) instances .
- Categories: individuals are characterized by features associated to the categories defined by models.
The first step of digital transformation is therefore to match the flows of heterogeneous data from territories with regard to systems maps (diagram below):
- Data that can be directly associated to identified business objects already managed, e.g: customers, products,… (a).
- Data that can be mapped to current models categories but not to identified individuals, e.g: anonymous reviews, aggregated sales, … (b).
- Data that cannot be mapped to predefined categories, e.g: search terms, musical tones (c).
At this point it must be stressed that the mapping of instances into categories implies a conceptual (and therefore architectural) distinction between data (instances) and information (categories), an often overlooked development of digital transformation.
That development takes its full significance when ontologies are used to frame data, information, and knowledge, providing a systematic account of what can be represented within domains of concern:
- Terms or labels: nothing is represented (no counterpart in business environments).
- Ideas or concepts: interrelated sets of terms with definitions.
- Instances: representations (surrogates) of objects or phenomena identified in business environments.
- Categories: features shared by sets of instances.
- Documents: symbolic container of media.
That would enable the integration of data (terms and instances), information (categories), and knowledge (concepts and documents) across enterprise architectures.
Models, Ontologies & Knowledge Architecture
The immersion of enterprises into digital environments and the crumbling of organizational and technical fences imply some alignment of definitions between business, organization, and systems. But that alignment is to remain shallow if limited to data without minding the semantic discrepancies between the symbolic representations of environments, organization, and systems.
To begin with, the generalization of digitized business flows effectively induces a shift from physical to symbolic realms, meaning that whatever the forms and ways, transformations are to involve some kind of models:
- Conceptual models, targeting enterprises organization and business independently of supporting systems.
- Logical models, targeting the symbolic objects managed by supporting systems as surrogates of business objects and activities.
- Physical models, targeting the actual implementation of symbolic surrogates as binary objects.
- Analytical models, targeting real and putative subsets of environments’ objects and phenomena.
That brings to the front model based approaches to systems engineering (MBSE), as well as the factors curtailing their actual implementation.
With regard to software engineering, MBSE has been mainly applied to design and code generation using domain specific languages (DSL). On that account, the distinctions introduced above is to ensure the transparency and traceability of transformations between logical (systems functionalities) and physical (systems platforms) models; that is best exemplified by the mapping of logical specialization and generalization into programming languages semantics.
But at enterprise level, MBSE has been hampered by the semantic gap between conceptual (business and organization) and logical (systems
functionalities) models. As a result, a conceptual equivalent of technical debt has accumulated, embodied by logical models supporting software engineering without proper basis in business or organization models. That gap can only be bridged with the integration of information models and knowledge architecture.
Bridging the Gap: From Information To Knowledge
As expounded by Davis, Shrobe, and Szolovits in their pivotal article, knowledge representation is made of:
- Surrogates, used as symbolic counterparts of actual objects and phenomena.
- Ontological commitments defining the categories of things that may exist in the domain under consideration.
- Fragmentary theory of intelligent reasoning defining what things can do or can be done with.
- Medium making knowledge understandable by computers.
- Medium making knowledge understandable by humans.
Transformations associated with point 1 can be dealt with at data level, i.e when actual instances are mapped to surrogates; and point 5 (human interfaces) is not directly impacted. That leaves points 2-4 as the conceptual hub of digital transformation, where information models have to be integrated with knowledge architecture.
From a formal as well as a practical point of view, the difference between models and ontologies is best defined by their purpose: pragmatic outcomes for the former (e.g requirements analysis or systems design), speculative ones for the latter (e.g business intelligence). Since that distinction directly impacts points 2-4 above regarding commitments and reasoning, any integration of models into knowledge architecture (and their mingling with ontologies) should ensure a double distinction: (a) between truth-preserving operations (common to pragmatic and speculative purposes) and modal logic, statistics, or other heuristics (specific to speculative purposes); and (b) between explicit and implicit knowledge.
Assuming that sorting out operations is to be supported by knowledge representation languages, the endgame of digital transformation would be to integrate the distinction between explicit and implicit knowledge into enterprise knowledge architecture and decision-making processes:
Explicit knowledge: symbolic representation of contexts, concerns, objectives, and policies. With regard to enterprises integration in digital environments, the focus is to be put on:
- Facts, as reflected by data from business environments and operations.
- Categories, supporting business and engineering ontologies and models.
- Logic and statistical methods used to process these models.
Implicit knowledge: whatever can be used or learned without being directly available through symbolic representation:
- People’s skills and expertise.
- Observation of facts or phenomena (data mining).
- Heuristic methods.
Groundbreaking advances in machine learning (ML) now provide sound and effective pooling of symbolic representations and neural networks. Implemented in knowledge engines that provides for seamless integration and feedback between explicit and implicit knowledge, ensuring transparency of ends and traceability of means, with instant and unmediated learning and operational capabilities.
Set in the context of merged systems and knowledge architectures, the ability to combine explicit and implicit knowledge is to radically improve enterprises decision-making processes.
Decision-making & Homeostasis
Traditionally, enterprises transformations have been carried out through top-down planning. But the generalization of digital environments is radically changing the rules, with enterprises redefined as viable organisms trying to sustain their identity while adapting their ways and structures to changing environments. It ensues that transformations, planned or otherwise, have to be more timely and accurately steered by bottom-up information. Hence the importance of enterprises ability to learn from changing environment and to adapt their processes and architectures accordingly.
That ability, known as homeostasis in cybernetics parlance, is meant to counter entropy, i.e the decay in viable organisms’ information. With regard to enterprises embedded into digital environments, that is to be achieved through a double integration:
At application level the nervous system of octopuses offers a good example of integrated sensory and cognitive capabilities, each arm with a brain and neurons and so a touch and taste of knowledge and decision-making. For applications that can be achieved through the fusing of software with value chains.
At enterprise level, cognitive systems would have to integrate strategic and operational decision-making.

With a nervous system combining distributed sensory and cognitive abilities, and assuming restructured conceptual debts, enterprise brains could develop business intelligence weaving around the same threads operational and strategic loops of Observations, Orientation, Decision, and Actions (OODA).
Engineering Transformations
If digital transformations are to simultaneously pervade systems and knowledge architectures, enterprises engineering processes have to be organized with regard to the nature of changes:
- Operational changes target applications and resources and are meant to be set within processes time-frame (a).
- Architecture changes target assets; they may be justified by business or technology and affect the design of business processes and supporting platforms (b).
- Organization changes target roles and processes; they may be justified by business or systems architecture (c).
Changes can then be managed depending on the tied-ups between actual architectures and symbolic representations:
- Management: changes in actual configurations (a1) and symbolic representations (a2) that can be carried independently.
- Changes of organization and processes affecting functional architecture (b).
- Changes of organization and business processes not affecting conceptual models (c).
- Changes in business processes (d).
That would not be possible without a differentiated management of models and ontologies:
- A kernel (aka knowledge engine), for truth-preserving
transformations of all models and ontologies. - Models, seen as a special case of ontologies pertaining to the the analysis or design of systems.
- Ontologies, dealing with the semantics of profiles, and business domains.

Eventually, the generalization of digital flows and the fusing of actual and symbolic architectures could pave the way to a genetic understanding of digital transformation, namely using models as systems DNA.
From Digital Transformations To e-Merging Architectures
Interestingly, homeostasis combined with the double integration of architectures (systems and knowledge) and decision-making levels (operational and strategic) may open a back door for unplanned and e-merging transformations, directly induced by changes in the environments.
As for live organisms, digitally encoded mutations would induce structural and behavioral changes, bottom-up from data analytics, top-down from knowledge to information models and business intelligence.

As it happens, breakthroughs in deep learning capabilities already provide back doors through which implicit trends in business environments can be directly translated into knowledge that can be “refactored” into design models in some kind of reverse engineering.
Further Reading
- Data vs Information
- Redeeming Conceptual Debts
- Systems, Information, Knowledge
- Knowledge Architecture
- EA and the Pagoda Architecture Blueprint
- EA: Entropy Antidote
- Open Ontologies: From Silos to Architectures
- Ontologies & Enterprise Architecture,
- Ontologies & Models
- Enterprise Governance & Knowledge
- Data Mining & Requirements Analysis
- Ontologies as Productive Assets
- Caminao Ontological Kernel (Protégé/OWL 2)
- Abstractions & Emerging Architectures
- Models Transformation
- Knowledge Based Models Transformation
- The Cases for Reuse
- The Economics of Reuse
- Legacy & Modernization
External Links
- Beer Stafford, “Diagnosing the System for Organizations“, Wiley (1985)
- Beer Stafford, “Brain of the Firm”, 2nd Edition, Wiley (1995)