
Preamble
As a cognitive process, abstraction is not a panacea but a modeling activity set in context and driven by concerns and purposes. As symbolic artifacts, abstractions are meant to describe relevant features and ignore noisy ones, picking all what is needed, and nothing more.
Abstraction & Architecture Layers
Applied to systems engineering, abstraction is often associated with three modeling layers which coincide with the ones set by the Model Driven Architecture:
- Requirements: symbolic description of the behavior of supporting systems (CIMs).
- Systems: abstract (consolidated) description of system functionalities (PIMs).
- Software: concrete description of symbolic artifacts (PSMs).

Yet, that apparent congruence between abstraction levels and architecture layers may cover the different semantics of abstraction when applied to requirements (partitions), functions (sub-types) and designs (inheritance).
Taxonomies & Partitions
Abstraction doesn’t deal with actual objects or phenomena but with their symbolic representations, and the term can be used to describe both the cognitive process and its symbolic outcome.

With the former understanding, abstractions are modeling steps, the problem being to chart the path from requirements variants (described with partitions) to their representation in software architecture (described through specialization). With the latter understanding, abstractions are symbolic artifacts, the problem being to characterize their role in models and identify patterns.
Beginning with the cognitive process, abstraction starts with the classification of objects or activities into subsets according to variants. That makes partitions the launch pad of the abstraction process:
- They can be applied to any kind of occurrences: objects or activities, static or dynamic.
- They can deal with every kind of variants.
- They are completely neutral with regard to the structure of symbolic representations.

With regard to variants:
- Exclusive partitions define non overlapping subsets, otherwise the same instances may belong to more than one subset.
- Mutable partitions deal with instances that can be moved across subsets during their life-cycle, otherwise the partition is bound to identities.

With regard to symbolic representations, partitions provide a consistent description of variants encompassing both objects and activities, putting the respective subsets under a common roof, and preparing the ground for the translation of requirements partitions into the types and sub-types of analysis models.

At this stage it must be reminded that abstractions come with models, which, if and when necessary, may serve very different purposes, in particular:
- Requirements analysis (descriptive models): partial and biased description of relevant contexts and objectives.
- Software design (prescriptive models): complete specification of symbolic artifacts.
- Data analysis (predictive models): tentative representation and simulation of business contexts.
Standing at the crossroad partitions provide the perfect conceptual hub between business requirements, data mining (through classifiers), and software engineering (through power-types).
How to Represent Partitions: Power-types
Power-types are artifacts representing partitions; their instances are symbolic objects whose features are shared by subsets of objects or phenomena. A power-type can be applied to different targets, the constraints being specified by the corresponding relationships: weight and individual status are exclusive but mutable for persons, occupations are mutable and overlapping, gender is exclusive, non mutable, and used to identify (#) persons.

Power-types play a pivotal role in the transition from requirements to models (and abstractions) by introducing an explicit reasoning between partitions and sub-types.
Finding Pies in the Skies: Abstraction in Models
Modeling is all too often a flight for abstraction when analysts should instead get their bearings and look for the proper level of representation, i.e the one best fitting their concerns and purposes. That pitfall can be avoided if requirements and models are put in their engineering perspective: requirements are meant to describe how systems support business processes, models describe software artifacts. While models can also be used for requirements, the polarity has to be maintained because the former are supposed to be rooted in concrete descriptions, while the latter aim at their symbolic counterpart.
On that basis, the mapping of requirements into models can be achieved by applying selectively the two faces of abstraction: first removing information from the description of actual contexts, then building symbolic representations according to business concerns.
Starting with requirements, data analysis techniques can be used to move up and down the abstraction ladder until one gets the right focus, providing a clear and sharp picture of business context and concerns. That can be achieved through three steps:
- Awareness of contexts: anchor models to clearly identified business objects and activities.
- Domains of concern: add features with unambiguous semantics.
- Abstractions: consolidate the descriptions of symbolic representations (aka surrogates).
It is worth to note that the first two levels deal respectively with instances and features of actual objects and activities, while the third deal with artifacts. As a corollary, abstraction at the first two levels should be understood in terms of partitions and subsets, before sub-types being introduced for symbolic representations.
Models Truth & Disproof
As noted above, abstractions are introduced when requirements are to be translated into models; the question is how to justify and validate those abstractions.
Checking models for internal consistency is arguably straightforward as verification can be based on the syntax and semantics of modeling languages. Things are more complicated for external consistency (i.e the mapping of abstractions to requirements) because any verification would have to rely on what is known of the business domains, and that knowledge is by nature partial and specific, if not hypothetical. Nonetheless, even if general proofs are out of reach, the truth of models can still be disproved by counter examples found among the instances under consideration.
As far as models make no use of abstractions (“flat” models), instances can be organized using basic set operators, and consistency checked with regard to existence, uniqueness, and change.
But flat models fall short when specific features are to be added to describe instances of partitions subsets; that’s when abstractions are to be introduced. Taking example from the Rent-a-Car case study, a flat Vehicle description (i.e one without sub-types) would be enough to fully cover all instances; but when sub-types are introduced for the specific features of trucks and cars, the base type is turned into a partial (hence abstract) description.

Whereas that difference may seem academic, it has direct and practical consequences when validation is considered because consistency must then be checked for every level, concrete or abstract.
As it happens, the corresponding problem has been tackled by Barbara Liskov for software design: the so-called Liskov substitution principle (LSP) states that if S is a sub-type of T, then instances of T may be replaced with instances of S without altering any of the desirable properties of the program.
Translated to analysis models, the LSP would state that, given a targeted set of instances (left), the semantics of a model will be consistent if it maps its target independently of the level of abstraction. And that can be easily verified by tallying instances identified by concrete nodes at each level:
- (a) Inconsistent semantics: two concrete levels (cars and rental) sharing the same set of identified instances (cars) with different tallies.
- (b) Consistent semantics: a single concrete level (rentals) using a functional description (car).
- (c) Consistent semantics: two concrete levels sharing the same target (cars) with the same tally.

Assuming a model abides by the substitution principle, it would be possible to generalize from the external consistency of a detailed level whatever the level of abstraction. As a corollary, the substitution principle combined with objects/aspects distinction appears as the cornerstone of the abstraction process.
Objects & Aspects
The Liskov substitution principle (LSP) puts the light on the different semantics of structural and functional inheritance, the former bound to identities, the latter detached. That difference have direct implications for requirements analysis.
As noted above, identified units of analysis models must be consistently mapped to their business counterparts independently of the level of abstraction. Since that constraint excludes multiple inheritance it severely curbs the benefits of abstraction. Yet, if that constraint has only to be enforced for structural variants, factoring out functional ones will still make room for multiple inheritance.
On a broader perspective, a distinction between objects and attitudes (aka aspects) would not only be a prop for abstraction but, perhaps more importantly, it would point requirements analysis in the direction of architecture layers:
- Abstractions driven by variants of business objects and processes must be kept anchored to units identified at enterprise level.
- Abstractions based on aspects, roles, and activities, while defined at enterprise level, can be modeled on their own at functional level.

That congruence between structural and functional abstractions on one hand, architecture layers on the other hand, appears clearly with use cases describing how system functionalities support business processes:
- Objects structures : composition of features valued wholly for identified objects. Adding a structure is equivalent to specialization (a).
- Objects interfaces (aka aspects): aggregation of features describing their semantics independently of the units they describe (b).
- Use cases: composition of activities describing parts of processes supported by systems. Being rooted in processes, use cases are identified by their triggering events and associated contexts (c).
- Scenarii: aggregation of activities describing logical sequences of operations. Scenarii can be seen as variants glued together by extension points, or as aggregates of uses cases (d).

Moreover, the Object/Aspect distinction brings inheritance and composition under a common modeling roof:
- Variants of persistent or execution units bound to identities (#) are described by structural inheritance (black triangles) or composition (black diamond).
- Variants of persistent or execution units detached from external identities are described by functional inheritance (white triangles) or aggregation (white diamond).
Requirements analysis can then proceed seamlessly through specialization and generalization.
Processes & Abstraction
Abstractions, and corollary inheritance, are primarily understood with objects. Yet, since business processes are meant to focus on activities, semantics may have to be refined when abstraction and inheritance are directly used for behaviors.
As the primary purpose of abstractions is to tackle business variants with regard to supporting systems, their representation with use cases provides a good starting point, with <extend> and <include> the default candidates for the initial description of behaviors’ specialization and generalization:
- <include>: to be compared to composition semantics, with the included behaviors performed by instances identified (#) by the owner UC (a).
- <extend>: to be compared to aggregation semantics, with the extending behaviors performed by separate instances with reference to the owner ones (b).
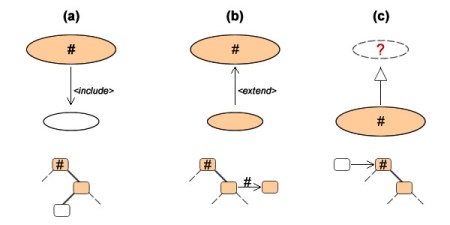
Notionally, abstract use cases (c) would represent behaviors never to be performed on their own. Compared to inclusion, used for variants of operations along execution paths, abstract use cases would describe the generic mechanisms to be applied to triggering events at UC inception independently of actual business operations carried out along execution paths.
Specialization vs Generalization
Abstraction as a modeling operation goes in two directions: specialization extends objects or activities, generalization factor out features or operations. As such, they meet different needs and are required in different modeling contexts:
- Specialization is needed when new features and behaviors are taken into account and therefore added to existing descriptions. As a consequence, specialization is not supposed to modify the semantics of existing artifacts.
- Generalization is justified when artifacts modeled separately are to be consolidated, which means that subsets of features and behaviors previously defined independently will be redefined with shared semantics. Hence, and contrary to specialization, generalization is meant to modify the semantics of existing artifacts.
While extension and consolidation can be used all along the engineering process, their justification is obviously not the same for requirements and implementations. And that is especially significant for model based software engineering.
Since specialization doesn’t affect the semantics of existing artifacts, changes in requirements can be directly mapped into their design counterparts. But that’s not the case with generalization because it affect upper levels of descriptions; as a consequence traceability has to be reconsidered for new as well as existing artifacts; for instance:
- Homing pigeons constitute an actual subset of pigeons. If new requirements introduce a functional subset for those used as carriers, its implementation can be designed without affecting existing classes, i.e traceability.
- Things are not so simple if carrier pigeons and human couriers are regrouped into a functional collection of carriers. In that case traceability between leaves will have to be redefined due to the insertion of a node with alternative designs (abstract class, interface, etc).

So, as illustrated by this example, generalization should be avoided at requirements level if it is to affect the design of existing components without stating it explicitly. That would be challenging given that abstractions are the basis of inheritance whose semantics at design level often differ depending on programming languages.
Once again, the Object/Aspect distinction may help to overcome the difficulty if inheritance is applied selectively:
- Specialization is straightforward as subsets can be safely defined by combining aspects with sets of identified objects (a).
- Generalization is more problematic because it entails sorting out intrinsic features from aspects. For instance, given homing pigeons and couriers, one may assume intrinsic (and external) identities for pigeons and persons, or opt for a consolidated role supporting identification independently of any physical identities (b).

With specialization and generalization understood as well-defined transformations of models, their use along the engineering process can be summed up:
- Specialization can be introduced for requirements then directly mapped into design without explicit considerations to analysis models in-between.
- Generalization should not be introduced before analysis since it is meant to consolidate prior requirements. Generalization may then be used to consolidate designs.
Those principles have significant repercussions for development processes, in particular for governing model transformation.
Specialization Patterns
Since patterns are meant to characterize problems with regard to solutions, the objective of specialization patterns is to provide analysts with handrails guiding abstraction from partitions (for the description of variants) to sub-types (that will support inheritance).
To begin with, it must be reminded that variants can be modeled either by specialization or by conditional structures, and that the semantics of inheritance may vary with programming languages. Hence the benefits of using consolidated semantics encompassing the different options (cf UML#):
- Strong construct (aka composition) or specialization applies to intrinsic features of identified objects or activities.
- Weak construct (aka aggregation) or specialization applies to contingent features not necessary bound to the identity of objects or activities.

Specialization patterns can then be organized according two criteria: identification (for instanciation) and features (for behaviors):
- Same features, subsets on values: power-type (a).
- Specific features: abstract base type, concrete sub-types (b).
- Additional features: concrete base type, unique sub-type (c).
- Features only (aka aspects): types are abstract as they cannot be instanciated independently. They can be combined by inheritance (d1) or composition or aggregation (d2).

Those constructs can be used independently of targeted instances (objects, events, actors, etc.)
Analysis vs Design
As cognitive operations generalization and specialization and can be applied at a wide range of domains and levels of granularity. But when considered at systems level, a formal basis can be used to align the former with analysis and the latter with design:
- Business analysis models are descriptive (aka extensional); generalization takes actual objects, events, and processes and put them into categories.
- System engineering models are prescriptive (aka intensional); specialization define systems components from expected functionalities.

As far as systems engineering is concerned, the challenge is to build a bridge (DDD) between the generalization of domains analysis and the specialization of supporting systems designs.
Abstractions & Emerging Architectures
Assuming that managing enterprise architectures entails some kind of documentation, the relevant models will have to deal with two kinds of targets, actual assets and processes on one hand, their respective symbolic representation as system objects on the other hand.

On that basis, the modeling shifts from actual (concrete) to symbolic (abstract) descriptions can be seen as the hinge connecting changes in systems and enterprise architectures, with enterprise architects in the middle trying to manage the back and forth movements.
Yet, the apparent symmetry can be misleading: if models of actual assets and processes are meant to reflect a reality, models of system symbolic surrogates are supposed to produce a different one, namely the actual software components managed by systems. And there is no guarantee that their alignment can be comprehensively and continuously maintained. For that to happen, i.e for business objects and processes being drawn from models, the bonds between the descriptions of actual objects and processes on one hand, their symbolic representation on the other hand, have to be loosened, as to give some latitude for the latter to be modified independently of the former. That is to be achieved through abstraction.
As noted above, systems functional architectures can be seen a bridges between business objectives and IT platforms. From the enterprise standpoint the primary factor is the continuity and consistency of corporate identity and activities. For that purpose abstractions have to target functional, persistency, and execution units. Definitions of those abstract units will provide the backbone of enterprise architecture (a). That backbone can then be independently fleshed out with features providing the identified structures of objects and activities are not affected (b).

From the systems standpoint the objective is the alignment of system and enterprise units on one hand, the effectiveness of technical architecture on the other hand. For that purpose abstract architecture units (reflecting enterprise units) are mapped to system units (c), whose design will be carried on independently (d).
Abstractions & Models
Abstraction can also be defined at model level (as opposed to artifacts):
- Ontologies are systematic accounts of existence for whatever is considered, in other words some explicit specification of the concepts meant to make sense of a universe of discourse.
- Conceptual Models can be seen as ontologies with focus and graphical notation.
- Meta-models can be seen as ontologies of models
Open Concepts & Abstraction Limits
With regard to systems modeling, what seems to be lacking is an open conceptual framework that could be applied to both sides of the business/system divide. In order to avoid a flight for abstraction or a rainbow chase, the scope and purpose of concepts have to be clearly circumscribed:
- Their footprint must be limited to their potential realization within business and system realms (no inroads into knowledge management).
- They must be defined independently of their actual realization within business or system realms (no encroaching from system architecture).
Taking a cue from the software open-source paradigm, they could be designated as open and built along similar principles. And to be of any use open concepts should have to be associated with a conceptual thesaurus.
Alignments: Abstractions are in the Eyes of the Stakeholders
Abstractions are symbolic tools whose semantics are defined by context and concerns. From that point of view it may seem natural to see logical technical, functional, and business levels as rungs of some generic abstraction ladder. Yet that understanding doesn’t stand up under scrutiny simply because their relationships are more concrete than symbolic, in other words better described in terms of composition than abstraction:
- Enterprise architecture includes systems which include platforms.
- Business processes are supported by applications which are executed by software components.
With that understanding, abstraction (as a process) is to be carried on from requirements to architectures within each layer: respectively business functions and capabilities, types and services, classes and interfaces.
Set between business processes and software applications, services may be understood as the ultimate enterprise architecture abstraction.
Further Reading
- The Book of Fallacies
- The Finger & the Moon: Fiddling with Definitions
- Reflections for the Perplexed
- Ontologies
- Modeling Paradigm
- What is to be Represented
- Abstraction Layers
- Finding Pies in the Skies: Abstraction in Models
- Knowledge Architecture
- EA & MDA
- Building a bridge
- Abstractions & Emerging Architectures
- Modeling languages: differences matter
- Open Concepts
- Open Concepts Will Make You Free
- Focus: Bounded Contexts & Open Concepts
In other words the ability for the human to change with the course of time and change bought on in society by those that are performing scientific study to see the cause and effect and problem solve that which has conflict adapting with change. Humans are not object they are people and why is that those that are either not black or wealthy should determine who should be abstracted when clearly it is a theory of opinion to create a truth. Sure people will conform to that which is programmed mentally without seeking knowledge as to how not to be systematic government robots but living right with justice. Enslavement again