The whole of enterprises’ endeavors and behaviors cannot be coerced into models lest they inhibit their ability to navigate ill defined and shifting business environments. Enterprises immersion in digital environments is making limits all the more explicit:
On the environment side, facts, once like manna from heaven ready to be picked and interpreted, have turned into data floods swamping all recognizable models imprints
On the symbolic side, concepts, once steadily supported by explicit models and logic, are now emerging like new species from the Big Data primordial soup.
Typically, business analysts are taking the lead on both fronts toting learning machines and waving knowledge graphs. In between system architects have to deal with a two-pronged encroachment on information models.
On the one hand they have to build a Chinese wall between private data and managed information to comply with regulations
On the other hand they have to feed decision-making processes with accurate and up-to-date observations, and adjust information systems with relevant and actionable concepts.
That brings a new light on the so-called conceptual, logical, and physical “data” models as key components of enterprise architecture:
Physical data models are meant to be directly lined up with operations and digital environments
Logical models represent the categories managed by information systems and must be up to par with systems functional architecture
Conceptual models are meant to represent enterprise knowledge of business domains and objectives, as well as its embodiment in organisation and people.
Logical models (information) appear therefore as an architecture hub linking business facts (data) and concepts (knowledge), ensuring exchanges between environments and representations e.g.:
Reasoning Patterns
Deduction: matching observations (data) with models to produce new information, i.e. data with structure and semantics
Induction: making hypothesises (knowledge) about the scope of models in order to make deductions
Compared to its bricks and mortar counterpart, enterprises architecture is a work in progress to be carried out all along enterprises life cycle; hence the need of actionable representations of environments, organization, assets, and processes.
Weaving Physical and Symbolic Threads into EA Digital Fabric (Inci Eviner)
As any artifact, actual or symbolic, models must serve some purposes which for systems architectures can be of two kind, descriptive (e.g analysis) or prescriptive (e.g design). Although that distinction often remains implicit at the systems level, it becomes critical at the enterprises level, when business objectives and organization take center stage. Compared to systems modeling, that would induce two key differences:
Architecture blueprints: enterprise architecture modeling has to be supported by a built-in distinction between business objectives and systems capabilities.
Engineering Processes: the modeling paradigm must ensure the integration of architecture blueprints and architecture changes.
A Taxonomy
Blueprints (models in systems parlance) can be characterized by a combination of targets and purposes:
Descriptive models cover all relevant aspects of environments and the ways to deal with them.
Prescriptive models aim at managed elements (organization, processes, products, or systems), and how they can be defined, designed, or built.
Predictive models add a virtual dimension to actual descriptive and prescriptive ones.
From a formal point of view these distinctions can be expressed in terms of modal logic:
Descriptive representations are meant to provide serviceable models of the business environment; such models are said to be extensional as their objective is to classify observations of objects and phenomena (or extensions) into categories. Actual descriptive (or analysis) models are used to organize the relevant features of domains; virtual ones (or analytic models) are used to extrapolate from actual observations.
Prescriptive representations go the other way as their purpose is to define presumptive artifacts or activities; they are said to be intensional as they denote sets of features meant to be supported by individuals instead of set of individuals. Actual prescriptive (or design) models deal with artifacts to be built, virtual ones with intended objectives or behaviors .
Digital Immersion & Emerging Architectures
Such a formal understanding of models has practical consequences for enterprise architecture as it provides a principled and integrated governance framework:
Strategic planning: integration of prescriptive representations between organization and systems, and of descriptive ones between expectations (business environment) and observations actual environment).
Systems engineering: integration of portfolio management and projects planning and development combining model based and agile solutions .
Business intelligence: integration of strategic and operational decision-making.
That alignment of systems and knowledge architectures is to be critical for enterprise governance, especially with regard to managing changes in digital environments.
Beyond varying names, requirements have often been classified into four basic categories:
Process requirements deal with organization and business processes independently of the part played by supporting systems.
Application requirements deal with the part played by supporting systems in the realization of processes requirements..
Quality of Service requirements deal with users experience independently of symbolic contents.
Technical requirements deal with the implementation of systems functions independently of users experience.
A customary requirements taxonomy
Yet, regardless of the soundness of these categories, their effectiveness varies with contexts, and contexts have been drastically disrupted with enterprises immersion in digital environments.
Digital Disruption
With the generalization of digital environments and the ensuing intermingling of business processes and IT two established distinctions are losing their grip, first between processes and applications, and then between users and systems.
Before and after digital disruption
For processes, the blurring is to concern non deterministic operations (heuristics, non modal logic, learning, …) that used to be the prerogative of humans but are now commonly carried out by artificial brains set in applications (a), user interface (d), or elsewhere (b). As a corollary, user interfaces are losing their homogeneity, as single systems with established codes of conduct are being replaced by an undefined number of unidentified agents (c, d).
Lest they drive enterprises into dead ends requirements have to map their systems according to the new digital territories. Not surprisingly, that can be best achieved using the symbolic/non symbolic distinction.
Requirements associated with symbolic contents.. Given that symbolic expressions can be reformulated, the granularity of these requirements can always be adjusted as to fall into single domains and therefore under the authority of clearly identified owners or stakeholders.
Requirements not dealing with symbolic contents. Since they cannot be uniquely tied to symbolic flows between systems and business contexts, nothing can be assumed regarding the identity of stakeholders. Yet, as they target systems features and behaviors, they can still be associated with architecture levels: enterprise, functional, technical.
Functional Requirements
As commonly understood, functional requirements cover business concerns and the part supported by systems; as such they can be aligned with enterprise architecture capabilities, symbolic (roles, business entities, business logic), and non symbolic (physical objects and locations, time-frames, events, processes execution).
In order to deal with the blurring induced by digital flows, requirements should ensure the transparency and traceability of interactions:
Transparency: users should be continuously aware of the kind of agent in charge behind the screen.
Traceability: users should be able to ask for explanations about every outcome.
As noted above, such requirements cannot be circumscribed to users interfaces or even applications as they involve the whole of the knowledge architecture . To that end functional requirements should be organized in relation to enterprise architecture capabilities, and include the necessary extensions for knowledge architecture:
When agents/roles assignments remain open requirements should include communication (natural, symbolic, or digital) and cognitive capabilities.
Assuming that requirements are not limited to modeled information, the distinction between data, information, and knowledge should be explicit.
Likewise for non deterministic reasoning used in business logic.
Functional requirements and Capabilities
Requirements concerning the digital capabilities of entry-points and time-frames of processes execution are to be added in order to associate functional and quality of service requirements.
Non Functional Requirements
Non functional requirements (NFRs) are meant to encompass whatever remain which cannot be tied to symbolic representations.
As should be expected for leftover categories, non functional requirements are by nature a mixed bag of overlapping items straddling the line between systems and applications depending on whether they directly affect users experience (quality of service), or are of the sole concern of architects and engineers (technical requirements).
The heterogeneity of non functional requirements is compounded by the mirror impact of the digital transformation on functional ones when business requirements (e.g high-frequency trading) combine performances with “intelligent” computing (e.g. machine learning capabilities).
Quality of Service and Capabilities
Yet, that is not to say that the distinction is arbitrary; in fact it conveys an implicit policy regarding architecture capabilities: defining elapse time as functional means that high-frequency traders will be supported by their own communication network and workstations, otherwise they will be dependent upon the company technical architecture, managed by a separate organizational unit, governed by its own concerns and policies.
On that account the digital transformation may help to clarify the issue of non functional requirements because all requirements, functional or otherwise can now be framed uniformly and therefore discriminate more easily.
Agility is the ability to react quickly and effectively to changes in environments. Taking cue from people, agility is conditioned by the resilience and plasticity of a backbone and the accuracy and reactivity of sensory motor connections.
Information layer (George Drivas)
On that account, the digital transformation of enterprise architectures calls into question the relevance of a flat information layer, and more generally of the traditional distinction between business and IT systems.
VALUE CHAINS & Digital Flows
To begin with connections, the generalization of digital flows is to affect the meaning of value chains, a concept introduced by Porter in 1985 as a way to chart the sequences of activities contributing to the delivery of a valuable product or service to market.
From a digital point of view value chains can be likened to nerves carrying signals between operations and organization; from a business point of view they are meant to track down the path of added value across contributing resources and assets.
But digital transformation and the ensuing pervasiveness of software components in business processes blur the boundaries between primary and supporting activities, calling for a redefinition of the relationships between business processes and supporting systems.
In return, the generalization of homogeneous digital flows within and without enterprises could also support the exchange of combined actual and symbolic contents between business environment and operations; hence the benefits of redefining supporting activities in terms of generic capabilities binding systems to enterprises organization:
Who could use the systems: interfaces, security, confidentiality, numbers, latency, synchronization, …
What kind of objects could be managed: storage, volumes, encryption, …
How activities could be supported: representation, and management of business logic.
When processes could be executed: events, control, orchestration, choreography…
Where processes could be executed : locations, assets, communication channels.
Redefining supporting activities in terms of enterprise architecture capabilities
The immediate benefit of that shift is to bring transparency to the overlaps between business processes and supporting systems. Concomitantly, it paves the way to a tighter integration of enterprise systems and knowledge architectures.
Information Layer vs Digital Backbone
Using digital flows to anchor business processes to architecture capabilities makes redundant the indiscriminate information layer often introduced between business and applications ones. Instead, a digital backbone can be set across the whole of enterprise architectures, with conceptual, logical, and digital data descriptions aligned respectively with computation independent, platform independent, and platform specific models.
A digital backbone instead of an information: layer
The alignment of architecture layers with differentiated information processing capabilities is to become a critical asset for enterprises immersed in digital environment. To deal with changes and competitors enterprises have to combine long-term objectives relative to their business environment with direct observations from the digital one. That cannot be achieved without a distinctive management of data, information, and knowledge:
At digital level data inputs from environments are to be sorted out as observations or managed information, the former to be fed into analytic models, recorded, or deleted, the latter used to update business surrogates in line with systems models.
At business level knowledge is managed with thesauruses and semantic graphs; it is at the source of business models and objectives as well as organization, and consequently of the architecture of information systems; knowledge is also updated through analytic tools.
Enterprise architects could then manage changes with regard to business intelligence (business models and observed and managed data) and existing systems, with ontologies securing the semantic interoperability of the different representations.
Compared to brick and mortar ones, enterprise architectures come with two critical extensions, one for their ability to change, the other for the intertwine of material and symbolic components.
Problems & Solution Spaces (Inci Eviner)
On that account the standard systems modeling paradigm is to fall short when enterprise changes are to be carried out in digital environments.
Problems & Solutions
Whatever the target (from concrete edifices to abstract polities), models come first in architect’s toolbox. Applied to enterprise architectures, models have to fathom different kinds of elements: physical (hardware), logical (software), human (organization), or conceptual (business).
From that point, what characterizes enterprise architectures is the mingling of physical and symbolic components, and their intrinsic evolutionary nature; problems and solutions have to be refined accordingly.
With regard to time and the ability to change, problems and solutions are defined by specific and changing contexts on one hand, shared and stable capabilities on the other hand. As for symbolic components, a level of indirection should be introduced between enterprise and physical spaces:
At enterprise level problems are defined by business environment and objectives (aka business model), and solved by organization and activities, to be translated into processes.
At system level problems are defined by processes requirements, and solved by objects representation and systems functions.
At platform level problems are defined by functional and operational requirements, and solved by applications design and configurations.
EA’s Problem & Solution Spaces
Such layered and crossed spaces are to induce two categories of feedback:
Between problems and solutions spaces, represented respectively by descriptive and prescriptive models.
Between layers and corresponding stakeholders, according to contexts, concerns, and time-frames.
Whereas facilitating that two-pronged approach is to be a primary objective of enterprise architects, the standard modeling paradigm (epitomized by languages like UML or SysML) is floundering up and down: up as it overlooks environments and organizational concerns, down by being overloaded with software concerns.
How to Sort Means (Systems) from Ends (Business)
Extending the system architecture paradigm to enterprise is the cornerstone of enterprise architecture as it provide a principled and integrated governance framework:
Business strategic planning: integration of intensional and extensional representations respectively for organisation and systems and business and physical environments.
System architecture: integration of portfolio management and projects planning and development combining model based and agile solutions .
Business intelligence: integration of strategic operational decision-making.
EA Models of Change
Bringing representations of environments, organization, and systems under a common conceptual roof is critical because planing and managing changes constitute the alpha and omega of enterprise architecture; and changes in diversified and complex organizations cannot be managed without maps.
The Matter of Change
Compared to systems architectures, change is an intrinsic aspect of enterprises architectures; hence the need for a modeling paradigm to ensure a seamless integration of blueprints and evolutionary processes.
Taking example from urbanism, the objective would be to characterize the changes with regard to scope and dependencies across maps and territories. On that account, the primary distinction should be between changes confined to either territories or maps, and changes affecting both.
Confined changes are meant to occur under the architectural floor, i.e without affecting the mapping of territories:
Territories: local changes at enterprise (e.g organisation) or systems (e.g operations) levels not requiring updates of architecture models.
Maps: local changes of domains or activities not affecting enterprise or systems elements at architecture level (e.g new features or business rules).
Maps & Territories (left) and Actionable EA
Conversely, changes above architectural floor whether originated in territories or maps are meant to modify the mapping relationship:
Changes in business domains (maps) induced by changes in enterprise environments (e.g regulations).
Changes in operations (systems) induced by changes in activities (e.g new channels).
That double helix of organizational, physical, and software components on one hand, models and symbolic artifacts on the other hand, is the key to agile architectures and digital transformation.
Ingrained habits die hard, especially mental ones as they are not weighted down by a mortal envelope. Fear is arguably a primary factor of persistence, if only because being able to repeat something proves that nothing bad has happened before.
Live, Die, Repeat (Philippe de Champaigne)
Procedures epitomize that human leaning as ordered sequences of predefined activities give confidence in proportion to generality. Compounding the deterministic delusion, procedures seem to suspend time, arguably a primary factor of human anxiety.
Procedures are Dead-ends
From hourglasses to T.S. Elliot’s handful, sand materializes human double bind with time, between will of measurement and fear of ephemerality.
Procedures seem to provide a way out of the dilemma by replacing time with prefabricated frames designed to ensure that things can only happen when required. But with extensive and ubiquitous digital technologies dissolving traditional boundaries, enterprises become directly exposed to competitive environments in continuous mutation; that makes deterministic schemes out of kilter:
There is no reason to assume the permanence of initial time-frames for the duration of planned procedures.
The blending of organizations with supporting systems means that architectural changes cannot be carried out top-down lest the whole be paralyzed by the management overheads induced by cross expectations and commitments.
Unfettered digital exchanges between enterprises and their environment, combined with ubiquitous smart bots in business processes, are to require a fine grained management of changes across artefacts.
These shifts call for a complete upturn of paradigm: event driven instead of scheduled, bottom-up instead of top-down, model based instead of activity driven.
Declarative frameworks: Non Deterministic, Model Based, Agile
The procedural/declarative distinction has its origin in the imperative/declarative programming one, the principle being to specify necessary and sufficient conditions instead of defining the sequence of operations, letting programs pick the best options depending on circumstances.
Applying the principle to enterprise architecture can help to get out of a basic conundrum, namely how to manage changes across supporting systems without putting a halt to enterprise activities.
Obviously, the preferred option is to circumscribe changes to well identified business needs, and carry on with the agile development model. But that’s not always possible as cross dependencies (business, organizational, or technical) may induce phasing constraints between engineering tasks.
As notoriously illustrated by Waterfall, procedural (if not bureaucratic) schemes have for long be seen as the only way to deal with phasing constraints; that’s not a necessity: with constraints and conditions defined on artifacts, developments can be governed by their status instead of having to be hard-wired into procedures. That’s precisely what model based development is meant to do.
And since iterative development models are by nature declarative, agile and model-based development schemes may be natural bedfellows.
Epigenetics & Emerging architectures
Given their their immersion in digital environments and the primacy of business intelligence, enterprises can be seen as living organisms using information to keep an edge in competitive environments. On that account homeostasis become a critical factor, to be supported by osmosis, architecture versatility and plasticity, and traditional strategic planning.
Set on a broader perspective, the merging of systems and knowledge architectures on one hand, the pervasive surge of machine learning technologies on the other hand, introduce a new dimension in the exchange of information between enterprises and their environment, making room for emerging architectures.
Using epigenetics as a metaphor of the mechanisms at hand, enterprises would be seen as organisms, systems as organs and cells, and models (including source) as genome coded with the DNA.
According to classical genetics, phenotypes (actual forms and capabilities of organisms) inherit through the copy of genotypes and changes between generations can only be carried out through changes in genotypes. Applied to systems, it would entail that changes would only happen intentionally, after being designed and programmed into the systems supporting enterprise organization and processes.
Enterprises epigenetics and emerging architectures
The Extended Evolutionary Synthesis considers the impact of non coded (aka epigenetic) factors on the transmission of the genotype between generations. Applying the same principles to systems would introduce new mechanisms:
Enterprise organization and their use of supporting systems could be adjusted to changes in environments prior to changes in coded applications.
Enterprise architects could use data mining and deep-learning technologies to understand those changes and assess their impact on strategies.
Abstractions would be used to consolidate emerging designs with existing architectures.
Models would be transformed accordingly.
While applying the epigenetics metaphor to enterprise mutations has obvious limitations, it nonetheless puts a compelling light on two necessary conditions for emerging structures:
Non-deterministic mechanisms governing the way changes are activated.
A decrypting mechanism between implicit or latent contents (data from digital environments) to explicit ones (information systems).
The first condition is to be met with agile and model based engineering, the second one with deep-learning.
Appraising enterprises capability and maturity means navigating between the fuzzy depths of business models and the marked features of supporting systems.
Keeping in touch with environment (Urs Fischer)
Business capabilities are by nature a fleeting lot to assess, considering the innate diversity and volatility of circumstances and the fact that successes belong to exception more than rule. By contrast, the assessment of systems capabilities is much easier as they can be defined in architectural terms.
Digital transformation may help to solve the dilemma by dissolving it: given the merging of systems and organization, the key success factor for enterprises is their capacity to assess changes and opportunities and adjust their processes and architectures accordingly. On that account, performances are to depend on the dynamic alignment of enterprises representations (maps) with their business and technological environments (territories).
enterprise architecture & environments
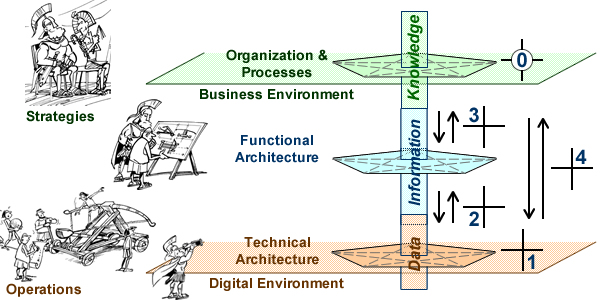
Based on a broadly accepted architecture paradigm epitomised by the Zachman framework, and figured by the Pagoda blueprint, enterprise environments and architectures are to be defined along three levels (aka tiers or layers):
Enterprise must align their maps and territories
Data level, for digital environment, operations, and platforms; described by physical and analytical models.
Information level, for systems and engineering, described by logical and functional models.
Knowledge level, for business objectives and organization; described by conceptual and process models.
That framework can be used to assess enterprises capacity to change independently of business specificites.
DEALING WITH CHANGES
Whereas absolute measurements are tied to valuation contexts, relative ones can be ecumenical, hence the benefit of targeting the capacity to change instead of trying to measure capacity by itself.
As far as enterprise architectures are concerned, changes can originate from business or technological environments, the former at process level, the latter at application level.
To begin with, as much change as possible should be dealt with at application level through organizational, functional, or operational adjustments, without affecting architectural assets. That is to be achieved through architectures versatility and plasticity (aka agility) .
When architectural changes are needed, their footprint can be layered in terms of Model Driven Architecture (MDA) , i.e computation independent (CIM), platform independent (PIM), and platform specific (PSM) models.
Change in Enterprise Architectures
Ideally, changes should spread top-down from computation independent models to platform specific ones, with or without affecting platform independent ones. On that account, the footprint of changes rooted in technical environment should be circumscribed to platforms adaptations and charted by platform specific models.
By contrast, changes rooted in business environment could induce changes in any or all architecture layers:
Platform specific (PSM), e.g when business logic is implemented by rules engines.
Platform independent (PIM), e.g new business functions.
Computation independent (CIM), e.g new business processes.
That model-based approach is to be used to define enterprises changes in terms of entropy.
Entropy & capacity to change
Change is a matter of time, especially for business, and a delicate balance is to be achieved between assessments (which improve when given time until they become redundant), and commitments (which risk missing opportunities if kept waiting for too long).
Changes in business and technology environments are observed at digital (e.g data mining) or conceptual level (e.g business intelligence) (a).
Assessment deals with the reliability of observations as well as their meaning with regard to enterprise objectives, organization, and systems (b).
Policies are updated and decisions made regarding the adjustment of objectives, resources, organization, or assets (c).
Decisions are implemented as technical and business commitments (d).
On that basis, the capacity to change is to depend on:
Osmosis: quality (accuracy, reliability,…), delay, and automaticity of observations with regard to changes in environments (data mining).
Operational traceability across decisions, actions and observations (process mining, verification).
Alignment of business and digital environments (validation).
Consistency of architecture models (CIMs, PIMs, PSMs).
Value chains and lean engineering: business logic (CIMs) directly embedded in software designs (PSMs).
Capacity to Change
With the benefits of digital transformation, these dimensions should be defined in terms of information processing.
osmosis & blind spots
The generalization of digital exchanges between enterprises and their environment brings back the concept of entropy, defined by cybernetics as the quantum of energy within a system that cannot be put to use. Applied to enterprises, entropy can be understood as a blind spot on environment data, arguably a critical hindrance to their capacity to move and adjust. The primary objective should therefore to minimize that blind spot, i.e to maximize the outcome of data processing .
As digital environments bring about level data playground, to get a competitive edge enterprises have to make a better sense of it; hence the importance of a distinction between data and information, the former obtained from the environment, the latter obtained through the processing of the former. On that basis, the capacity to change, defined as the opposite of entropy, is to be determined by the way data is processed into information.
Digital osmosis, i.e the exchange of digital data between enterprises operations and environments is clearly a primary factor: inbound streams can be mined as to provide comprehensive and timely snapshots, outbound streams can be weaved into business processes, enhancing the capacity to translate decisions into action.
Digital osmosis could also bolster lean engineering with the direct integration of (digital) business logic into software (e.g using rules engines), reinforcing the shortcuts between observations and decisions whenever orientation can be avoided. That would also enhance traceability between platform specific (PSMs) and operational models, as well as the monitoring of actions and the analysis of feedbacks (process mining).
Osmosis could be easily (if not accurately) estimated with the ratio between digitized flows and the whole of data flows, with measurements weighted by delays between observations and data processing.
A taxonomy of changes
Digital and business environments are not to be confused, and there is no reason to assume that their respective changes tally. As it happens, digital transformation may reinstall organizations at the nexus of changes by providing a powerful leverage on systems; and if entropy is considered, that is to be achieved through symbolic representations, aka models.
While names may vary, a distinction is generally made between changes according to their horizon, shorter for operational or tactical ones, longer for strategic ones. As so often with quantitative classifications, that understanding has been of limited use given the diversity of time-frames across industries. The digital transformation open the door to a qualitative approach, defining changes according to the nature of of their footprint:
From the business perspective, it should restate the primacy of organization for the harnessing of IT benefits.
From the architecture perspective, it would rank assets according to “digital modality”: symbolic (information, knowledge), tangible (e.g platforms), or a combination of both (functional architecture).
Changes can be defined according to the digital modality of their footprint
Taking the strategic perspective, changes in technical or economic factorsare to affect assets and processes for a large and often undetermined number of production cycles; they must consequently be set in time-frames extending beyond managed horizons (actual chronologies depend on industries specificities). Despite regular updates, supporting models and hypothesis may lose their relevance during the intervals, with the resulting entropy hampering the assessment of opportunities and policies. Such discrepancies can be circumscribed if planned organization and computation independent models (CIMs) are systematically checked against observations.
Compared to strategic ones, functional changes can be aligned with a limited number of production cycles, which irons out most of the discrepancies between maps and territories associated with strategic planning. Instead, entropy could arise from a lack of transparency and traceability between the models used to map organization and processes (CIMs) to functional (PIMs) and technical (PSMs) architectures.
Finally, operational changes can be carried out at process level, without affecting architectures. In that case entropy could be the result of a misalignment of commitments and observations granularity.
On that basis, planning and managing changes in digital and business environments should be driven by models.
ENTROPY & maturity
As defined by cybernetics, entropy can be explained by the discrepancies between environment states (aka micro-states) and their representation (macro-states). Applied to enterprises environments and architectures, it would mean territories and operations for the former, maps and policies for the latter.
On that account the maturity of an organization should be assessed with regard to its ability to manage changes within and across environments:
Consistency of changes within environments: between territories and operations (digital environments), between maps and policies (business environments) .
Validity of changes across environments: between maps and territories, and between policies and operations.
Consistency is checked within environments, validity is checked across environments
Maturity levels could then be set according to the scope of managed entropy:
Digital osmosis: all exchanges with environments come with digital counterpart sorted with regard to operational data, data attached to managed information, environment data detached from managed information.
Digital value chains: digital integration of business and engineering processes ensuring transparency and traceability along value chains.
Organizational pivot: value chains can be redefined as to make the best of information assets.
Knowledge based architectures: enterprise layers (platforms, systems, organization) are aligned with data, information, and knowledge layers, leveraging the benefits of machine learning across enterprise organization and systems.
As defined by thermodynamics entropy is a measure of the energy within a system that cannot be usefully harnessed; cybernetics has took over, making entropy a pillar of information theory.
Figuring Digital Matter (Marcelo Cidade)
Notwithstanding the focus put on viable systems and organizations (as epitomized by the pioneering work of Stafford Beer), cybernetics’ actual imprint on corporate governance has been frustrated by the correspondence assumed between information and energy. But the immersion of enterprises into digital environments brings entropy back in front, along with a paradigmatic shift out of thermodynamics.
domain: Physics vs Economics
The second law of thermodynamics states that entropy within a system is constant, and so is information as defined by cybernetics. But economics laws, if there is such a thing, are to differ: as far as business is concerned information is not to be found in commons but comes from the processing of raw data.
As a matter of fact, thermodynamic stability is meaningless in economics because business information is not a given and uniform quantity but a fluctuating and polymorph one. It ensues that for enterprises in competitive environments measures of entropy set in isolation are pointless: taking a leaf from Lewis Carroll’s Red Queen, the entropy of any given enterprise can only be assessed in relation with its competitors.
Taking a general perspective, entropy is meant to be observed either between the two ends of communication channels, or at the boundaries of complex systems (animals, machines, or organizations). While the former can be seen as a formal coding issue, the latter is of particular relevance for enterprises immersed in digital environments.
Departing from thermodynamics view of entropy measuring a system’s thermal energy unavailable for conversion into mechanical work, economics will consider unexplained information, i.e which cannot be acted upon.
But leaving physics also means forsaking the comfort of its metrics. That’s not a problem for communication entropy, which can be dealt with as a coding issue; but the difficulty appears when counts of digits have to be replaced by measures of knowledge.
complexity: microstates vs macrostates
When there are no clear and reliable metrics to put light on it, entropy becomes a black hole defined by disorder or randomness, the former in reference to the order borne out by classifications, the latter in reference to the predictability borne out by probabilities. Since both approaches deal with the relationship between configurations and information, the issue can be summarized with:
A quantum of hypothetical information (dashed line).
The complexity of identified items (aka microstates).
The complexity of representations (aka macrostates).
The quantum of information accounted for, ordered or predicted.
How to assess what is missed ?
As stated by the basic law of thermodynamics, to be of any energetic use the internal heat of a system has to be lower than the external one. Generalized in terms of complexity, it means that the quantum of information accounted for will first increase with the number of configurations considered, reach a maximum, and then decrease until the complexity of configurations (aka internal heat) equates the complexity of the target (aka external heat).
Translated to economics, that scheme must be restated in terms of digital environments and business information.
Representation: whether the exchanges are carried out at digital level (data observations of microstates) or in association with symbolic representations (models of macrostates) of managed information.
Coupling: whether the processing of data is tied to operations or carried out independently.
Entropy Layers
The issue of entropy can be restated accordingly:
The direct consequence of the digital transformation is to increase osmosis between enterprises and their environment, with data flows bypassing traditional boundaries and feeding directly operational processes (bottom right).
As a result, data analytics can be integrated with business processes, improving operational decision-making. In terms of entropy the outcome would be a more effective use of information models (bottom left).
Next, information models (aka symbolic representations) can themselves be changed as to improve their effectiveness, i.e reduce entropy at process as well as architecture level (top left).
Last but not least, deep learning could be applied to digitalized contexts (aka microstates) in order to derive new symbolic representations (aka macrostates) (top right).
On that basis entropy policies should be set at operational and strategic levels, the former dealing with processes, the latter with architectures.
Homeostasis: from Data to knowledge
As far as enterprises are concerned, homeostasis means the adaptation of organizations and systems to changes in competitive environments. To that end, policies set along the entropy paradigm could draw on improving the perception of microstates (data level) as well as the representation of macrostates (information level).
At data level, the perception of changes depends on the osmosis between systems and environments. To that end data mining is to be used to hone the sampling of populations and refine microstates.
At symbolic level (representations), the economics perspective differs from physics on two critical aspects:
Contrary to heat, economic information is not a constant, which means that macrostates are to be continuously updated.
Moreover, the economic playground is not homogenous but combines physical (e.g demographics or climate), socio-economic (e.g income or education) and symbolic (e.g politics or culture) microstates, which means that macrostates are to be differentiated.
Improving entropy
With or without differentiated macrostates, policies are to rely on two categories of models:
Extensional ones target environments, dealing with the analysis of business context, operations, and changes (descriptive models), as well as what should be expected (predictive models).
Intensional ones deal with enterprise architectures, current or planned, at processes as well as architecture level (prescriptive models).
As figured above, representations and policies are to be combined, hence the need to anchor them to enterprise architectures, as can be illustrated with the Pagoda blueprint:
Architectures & Homeostasis (crosses and numbers refer to the table above)
Populations of instances (microstates) are obtained from digital environments as well as from processes execution (1). Data analytics are used to improve descriptive and predictive models (operational macrostates), and consequently the osmosis between processes and environment (2).
Architecture improvements can be achieved through changes in prescriptive models (structural macrostates). Compared to strategic planning carried out top-down from business models and requirements, homeostasis also relies on bottom-up forces which can combine with business models and coalesce into emerging architectures (3).
Business and organization models are arguably a primary factor in sorting out data, respectively from environments and systems; and being by nature essentially symbolic, they are more pliable than systems models (0). Homeostasis could therefore bypass architectural macrostates, with models of business and organization emerging directly from digital environments through data mining and deep learning (4).
Such alignment of enterprise architectures and symbolic representations is to greatly enhance the transparency and traceability of digital transformations by organising changes and policies with regard to their nature (physical, functional, organizational, or business) and decision-making horizon (operational or strategic).
As a capability of live organisms, languages are best understood in terms of communication.
That understanding is of particular interest for enterprises immersed in digital environments inhabited by hybrids with deep learning capabilities.
Languages begin with the need of direct (here) and immediate (now) communication. While there is no time for explanations, messages must convey some meaning, if only to distinguish friends from foes. Hence the use of signs pointing to categories of objects or phenomena. That’s the language lexical layer linking instantly observations (data) to information (bottom right).
Rules governing the combination of signs follow soon because more has to be communicated about circumstances and what is to be done with. That’s the language syntactic layer linking observations (data) to current information (top right).
The breakthrough comes with symbolic representation: once disentangled from immediate circumstances, communications can encompass whatever is deemed relevant in contexts and concerns; That’s the language semantic layer that weave together information and knowledge (top left).
The cognitive ability to “manipulate” symbolic representations (aka models) independently of circumstances opens the door to any kind of constructions. That’s the language pragmatic layer meant to put knowledge to actual use (bottom left).
That functional taxonomy can be usefully applied to the digital transformation of enterprise architectures, the first layer aligned with data, the second and third with information, and the fourth with knowledge.
The digital transformation induces fundamental changes for the exchanges between enterprises and their environment.
To begin with, their immersion into digital environments means that the traditional fences surrounding their IT systems are losing their relevance, being bypassed by massive data flows to be processed without delay.
Then, the induced osmosis upturns the competition playground and compels drastic changes in governance: less they fall behind, enterprises have to redefine their organization, systems, and processes.
Strategies are meant to draw passageways between current circumstances and conjectured horizons (Kader Attia)
New playground
Strategic thinking is first and foremost making differences with regard to markets, resources and assets, and time-frames. But what makes the digital revolution so disruptive is that it resets the ways differences are made:
Markets: the traditional distinctions between products and services are all but forgotten.
Resources and assets: with software, smart or otherwise, now tightly mixed in products fabric, and business processes now driven by knowledge, intangible assets are taking the lead on conventional ones.
Time-frames: strategies have for long been defined as a combination of anticipations, objectives and policies whose scope extends beyond managed horizons. But digital osmosis and the ironing out of markets and assets traditional boundaries are dissolving the milestones used to draw horizons perspectives.
New perspectives
To overcome these challenges enterprises strategies should focus on four pillars:
Data and Information: massive and continuous inflows of data calls for a seamless integration of data analytics (perception), information models (reasoning), and knowledge (decision-making).
Security & Confidentiality: new regulatory environments and costs of privacy breaches call for a clear distinction between data tied to identified individuals and information associated to designed categories.
Innovation: digital environments induce a new order of magnitude for the pace of technological change. Making opportunities from changes can only be achieved through collaboration mechanisms harnessing enterprise knowledge management to environments intakes.