The whole of enterprises’ endeavors and behaviors cannot be coerced into models lest they inhibit their ability to navigate ill defined and shifting business environments. Enterprises immersion in digital environments is making limits all the more explicit:
On the environment side, facts, once like manna from heaven ready to be picked and interpreted, have turned into data floods swamping all recognizable models imprints
On the symbolic side, concepts, once steadily supported by explicit models and logic, are now emerging like new species from the Big Data primordial soup.
Typically, business analysts are taking the lead on both fronts toting learning machines and waving knowledge graphs. In between system architects have to deal with a two-pronged encroachment on information models.
On the one hand they have to build a Chinese wall between private data and managed information to comply with regulations
On the other hand they have to feed decision-making processes with accurate and up-to-date observations, and adjust information systems with relevant and actionable concepts.
That brings a new light on the so-called conceptual, logical, and physical “data” models as key components of enterprise architecture:
Physical data models are meant to be directly lined up with operations and digital environments
Logical models represent the categories managed by information systems and must be up to par with systems functional architecture
Conceptual models are meant to represent enterprise knowledge of business domains and objectives, as well as its embodiment in organisation and people.
Logical models (information) appear therefore as an architecture hub linking business facts (data) and concepts (knowledge), ensuring exchanges between environments and representations e.g.:
Reasoning Patterns
Deduction: matching observations (data) with models to produce new information, i.e. data with structure and semantics
Induction: making hypothesises (knowledge) about the scope of models in order to make deductions
Enterprise Architects are to jump across loops (Bruce Beasley)
When push comes to shove, deciding on a development process is to decide between instant or delayed returns, namely focusing on users needs with agile development, or taking extended features into consideration and weighting the benefits of reuse against additional costs, e.g.:
Designs to be reused as patterns.
Profiling configurations.
Structuring business process models so that they could be designed as business functions.
Formatting business logic for automated code generation.
The intricacies of stakes and decision-making processes can be set forth by applying the Observation-Orientation-Decision-Action (OODA) loop to the four views of changes: enterprise, business domains, business applications, systems:
At enterprise level the loops are triggered by changes in business environments pertaining to business model and objectives. They are supposed to affect different business domains.
Observations: Business opportunities
Orientation: Assessment of business opportunities with regard to business objectives.
Decision: Committing resources to changes in organization and processes
Action: Achieving changes in organization and processes
Changes initiated from business domains can be derived from enterprise level or the result of more specific objectives. They are supposed to affect different applications.
Observations: Business analysis
Orientation: Functional feasibility and assessment of transformation benefits.
Decision: Committing changes in functional architecture.
Action: Development, integration, tests
Changes at application level are initiated by organizational units, business or otherwise. They are supposed to be self-contained.
Observations: Users requirements
Orientation: Engineering feasibility and assessment of development options.
Decision: Choice of a development model.
Action: Development, integration, tests
Changes at system level are initiated by organizational units, including business ones (quality of service). They are supposed to affect different applications.
Observations: Process mining and operational requirements
Orientation: Operational feasibility and assessment of configurations.
Decision: Development model.
Action: Deployment and acceptance.
Given that sizeable companies with differentiated organization and business have to manage these different threads continuously and consistently, old fashioned imperative processes can only lead to paralysis. Hence the need of a declarative approach to EA workflows.
As far as enterprise architecture is concerned, the issue of scale is fogged by two confusions: one between processes and structures, the other between space and time. That square is at the core of the discipline.
Scaling Time (Tycho Brahe)
The Matter of Time
Even before the digital unfolding of environments, everybody was to agree that business is all about timing; and yet, that critical dimension remains a side issue of most enterprise architecture frameworks, which consequently fail to deal with enterprises ability to change and adapt in competitive environments.
With regard to time, the business perspective is said to be synchronic because it must continuously tally with environments constraints, opportunities, and risks.
By contrast, the engineering perspective is said to be diachronic because once fastened to requirements, developments are supposed to proceed according their own time-span.
Mixing Timescales
For enterprise architects, pairing up business and engineering momentum may look like a Fourier transform that would decompose enterprise architecture into piecemeal capabilities to be adjusted to the flow of business circumstances. But assets being by nature discrete, changes are not easily ironed out and some mechanism is necessary to align business and engineering time-frames, the former set at enterprise level and used to align enterprise architecture capabilities with business objectives, the latter set at system level and used to manage developments.
Agile methodologies solve the problem by assuming continuous deliveries disconnected from external schedules and by folding projects into detached time warps. Along with debatable scaling attempts, definitively non agile procedures are used to carry on with agile projects at system level.
As it happens, the iterative model can be upgraded to architecture level, enabling the linking of business driven changes to systems based ones without breaking agile principles:
Projects’ scope, objectives, and invariants are set with regard to enterprise architecture capabilities.
Iterations combine requirements analysis, development, and acceptance.
Increments and deliverables are defined dynamically contingent on scope and invariants.
Exit conditions (aka deliveries) are defined with regard to quality of services and technical requirements.
So-called architecture backlogs could thus be added to coordinate self-contained developments, standalone applications as well as system business functions, e.g. (invariants are in grey):
But the coordination issue remains between architecture backlogs, and adding procedures or committees shouldn’t be an option as it would seriously curb enterprise agility. By contrast, model based solutions are to ensure a constant and consistent adaptation of enterprise architectures to their environment.
For all intents and purposes, digital transformation has opened the door to syntactic interoperability… and thus raised the issue of the semantic one.
Cooked Semantics (Urs Fisher)
To put the issue in perspective, languages combine four levels of interpretation:
Syntax: how terms can be organized.
Lexical: meaning of terms independently of syntactic constructs.
Semantic: meaning of terms in syntactic constructs.
Pragmatic: semantics in context of use.
Languages levels of interpretation
At first, semantic networks (aka conceptual graphs) appear to provide the answer; but that’s assuming flat ontologies (aka thesaurus) within which all semantics are defined at the same level. That would go against the objective of bringing the semantics of business domains and systems architectures under a single conceptual roof. The problem and a solution can be expounded taking users stories and use cases for examples.
Crossing stories & cases
Beside the difference in perspectives, users stories and use cases stand at a methodological crossroad, the former focused on natural language, the latter on modeling. Using ontologies to ensure semantic interoperability is to enhance both traceability and transparency while making room for their combination if and when called for.
Users’ stories are part and parcel of Agile development model, their backbone, engine, and fuel. But as far as Agile is concerned, users’ stories introduce a dilemma: once being told stories are meant to be directly and iteratively put down in code; documenting them in words would bring back traditional requirements and phased development. Hence the benefits of sorting out and writing up the intrinsic elements of stories as to ensure the continuity and consistency of engineering processes, whether directly to code, or through the mediation of use cases.
To that end semantic interoperability would have to be achieved for actors, events, and activities.
Actors & Events
Whatever architectures or modeling methodologies, actors and events are sitting on systems’ fences, which calls for semantics common to enterprise organization and business processes on one side of the fence, supporting systems on the other side.
To begin with events, the distinction between external and internal ones is straightforward for use cases, because their purpose is precisely to describe the exchanges between systems and environments. Not so for users stories because at their stage the part to be played by supporting systems is still undecided, and by consequence the distinction between external and internal events.
With regard to actors, and to avoid any ambiguity, a semantic distinction could be maintained between roles, defined by organizations, and actors (UML parlance), for roles as enacted by agents interacting with systems. While roles and actors are meant to converge with analysis, understandings may initially differ across the fence between users stories and use cases, to be reconciled at the end of the day.
Representations should support the semantic distinctions as well as trace their convergence.
That would enable use cases and users stories to share overlapping yet consistent semantics for primary actors and external events:
Across stories: actors contributing to different stories affected by the same events.
Along processes: use cases set for actors and events defined in stories.
Across time-frames: actors and events first introduced by use cases before being refined by “pre-sequel” users stories.
Such ontology-based representations are to support full iterative as well as parallel developments independently of the type of methods, diagrams or documents used by projects.
activities
Users’ stories and use cases are set in different perspectives, business processes for the former, supporting systems for the latter. As already noted, their scopes overlap for events and actors which can be defined upfront providing a double distinction between roles (enterprise view) and actors (systems view), and between external and internal events.
Activities raise more difficulties because they are meant to be defined and refined across the whole of engineering processes:
From business operations as described by users to business functions as conceived by stakeholders.
From business logic as defined in business processes to their realization as defined in diagram sequences.
From functional requirements (e.g users authentication or authorization) to quality of service.
From primitives dealing with integrity constraints to business policies managed through rules engines.
To begin with, if activities have to be consistently defined for both users’ stories and use cases, their footprint should tally the description of actors and events stipulated above; taking a leaf from Aristotle rule of the three units, activity units should therefore:
Be triggered by a single event initiated by a single primary actor.
Be located into a single physical space with all resources at hand.
Timed by a single clock controlling accesses to all resources.
On that basis, the refinement of descriptions could go according to the nature of requirements: business (users’ stories), or functional and quality of service (use cases) .
Activities (execution units) should be tally with roles, events, and location.
Use cases wrap computation independent activities into transactions.
As far as ontologies are concerned, the objective is to ensure the continuity and consistency of representations independently of modeling tools and methodologies. For activities appearing in users stories and use cases, that would require:
The description of activities in relation with their business background, their execution in processes, and the corresponding functions already supported by systems.
The progressive refinement of roles (users, devices, other systems), location, and resources (objects or surrogates).
An unified definition of alternatives in stories (branches) and use cases (extension points)
The last point is of particular importance as it will determine how business and functional rules are to be defined and control implemented.
Knitting semantics: symbolic representations
The scope and complexity of semantic interoperability can be illustrated a contrario by a simple activity (checking out) described at different levels with different methods (process, use case, user story), possibly by different people at different time.
The Check-out activity is first introduced at business level (process), next a specific application is developed with agile (user story), and then extended for variants according to channels (use case).
Semantic interoperability between projects, domains, and methods.
Assuming unfettered naming (otherwise semantic interoperability would be a windfall), three parties can be mentioned under various monikers for renters, drivers, and customers.
In a flat semantic context renter could be defined as a subtype of customer, itself a subtype of party. But that option would contradict the neutrality objective as there is no reason to assume a modeling consensus across domains, methods, and time.
The ontological kernel defines parties and actors, as roles associated to agents (organization level).
Enterprises define customers as parties (business model).
Business unit can defines renters in reference to customers (business process) or directly as a subtype of role (user story).
The distinction between renters and drivers can be introduced upfront or with use cases’ actors.
That would ensure semantic interoperability across modeling paradigms and business domains, and along time and transformations.
Probing semantics: metonymies and metaphors
Once established in-depth foundations, and assuming built-in basic logic and lexical operators, semantic interoperability is to be carried out with two basic linguistic contraptions: metonymies and metaphors .
Metonymies and metaphors are linguistic constructs used to substitute a word (or a phrase) by another without altering its meaning, respectively through extensions and intensions, the former standing for the actual set of objects and behaviors, the latter for the set of features that characterize these instances.
Metonymy relies on contiguity to substitute target terms for source ones, contiguity being defined with regard to their respective extensions. For instance, given that US Presidents reside at the White House, Washington DC, each term can be used instead.
Metonymy use physical or functional proximity (full line) to match extensions (dashed line)
Metaphor uses similarity to substitute target terms for source ones, similarity being defined with regard to a shared subset of features, with leftovers taken out of the picture.
Metaphor uses similarity to match descriptions
Compared to basic thesaurus operators for synonymy, antonymy, and homonymy, which are set at lexical level, metonymy and metaphor operate at conceptual level, the former using set of instances (extensions) to probe semantics, the latter using descriptions (intensions).
Applied to users stories and use cases:
Metonymies: terms would be probed with regard to actual sets of objects, actors, events, and execution paths (data from operations) or mined from digital environments.
Metaphors: terms for stories, cases, actors, events, and activities would be probed with regard to the structure and behavior of associated descriptions (intensions).
Compared to the shallow one set at thesaurus level for terms, deep semantic interoperability encompasses all ontological dimensions, from actual instances to categories, aspects, and concepts. As such it can take full advantage of digital transformation and deep learning technologies.
Appraising enterprises capability and maturity means navigating between the fuzzy depths of business models and the marked features of supporting systems.
Keeping in touch with environment (Urs Fischer)
Business capabilities are by nature a fleeting lot to assess, considering the innate diversity and volatility of circumstances and the fact that successes belong to exception more than rule. By contrast, the assessment of systems capabilities is much easier as they can be defined in architectural terms.
Digital transformation may help to solve the dilemma by dissolving it: given the merging of systems and organization, the key success factor for enterprises is their capacity to assess changes and opportunities and adjust their processes and architectures accordingly. On that account, performances are to depend on the dynamic alignment of enterprises representations (maps) with their business and technological environments (territories).
enterprise architecture & environments
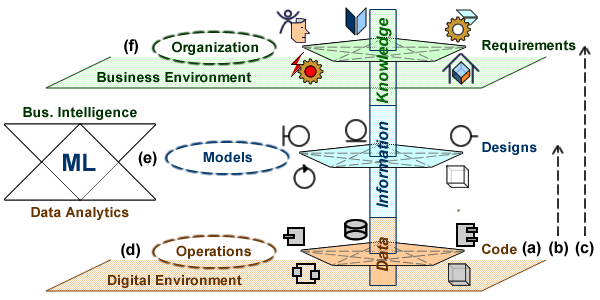
Based on a broadly accepted architecture paradigm epitomised by the Zachman framework, and figured by the Pagoda blueprint, enterprise environments and architectures are to be defined along three levels (aka tiers or layers):
Enterprise must align their maps and territories
Data level, for digital environment, operations, and platforms; described by physical and analytical models.
Information level, for systems and engineering, described by logical and functional models.
Knowledge level, for business objectives and organization; described by conceptual and process models.
That framework can be used to assess enterprises capacity to change independently of business specificites.
DEALING WITH CHANGES
Whereas absolute measurements are tied to valuation contexts, relative ones can be ecumenical, hence the benefit of targeting the capacity to change instead of trying to measure capacity by itself.
As far as enterprise architectures are concerned, changes can originate from business or technological environments, the former at process level, the latter at application level.
To begin with, as much change as possible should be dealt with at application level through organizational, functional, or operational adjustments, without affecting architectural assets. That is to be achieved through architectures versatility and plasticity (aka agility) .
When architectural changes are needed, their footprint can be layered in terms of Model Driven Architecture (MDA) , i.e computation independent (CIM), platform independent (PIM), and platform specific (PSM) models.
Change in Enterprise Architectures
Ideally, changes should spread top-down from computation independent models to platform specific ones, with or without affecting platform independent ones. On that account, the footprint of changes rooted in technical environment should be circumscribed to platforms adaptations and charted by platform specific models.
By contrast, changes rooted in business environment could induce changes in any or all architecture layers:
Platform specific (PSM), e.g when business logic is implemented by rules engines.
Platform independent (PIM), e.g new business functions.
Computation independent (CIM), e.g new business processes.
That model-based approach is to be used to define enterprises changes in terms of entropy.
Entropy & capacity to change
Change is a matter of time, especially for business, and a delicate balance is to be achieved between assessments (which improve when given time until they become redundant), and commitments (which risk missing opportunities if kept waiting for too long).
Changes in business and technology environments are observed at digital (e.g data mining) or conceptual level (e.g business intelligence) (a).
Assessment deals with the reliability of observations as well as their meaning with regard to enterprise objectives, organization, and systems (b).
Policies are updated and decisions made regarding the adjustment of objectives, resources, organization, or assets (c).
Decisions are implemented as technical and business commitments (d).
On that basis, the capacity to change is to depend on:
Osmosis: quality (accuracy, reliability,…), delay, and automaticity of observations with regard to changes in environments (data mining).
Operational traceability across decisions, actions and observations (process mining, verification).
Alignment of business and digital environments (validation).
Consistency of architecture models (CIMs, PIMs, PSMs).
Value chains and lean engineering: business logic (CIMs) directly embedded in software designs (PSMs).
Capacity to Change
With the benefits of digital transformation, these dimensions should be defined in terms of information processing.
osmosis & blind spots
The generalization of digital exchanges between enterprises and their environment brings back the concept of entropy, defined by cybernetics as the quantum of energy within a system that cannot be put to use. Applied to enterprises, entropy can be understood as a blind spot on environment data, arguably a critical hindrance to their capacity to move and adjust. The primary objective should therefore to minimize that blind spot, i.e to maximize the outcome of data processing .
As digital environments bring about level data playground, to get a competitive edge enterprises have to make a better sense of it; hence the importance of a distinction between data and information, the former obtained from the environment, the latter obtained through the processing of the former. On that basis, the capacity to change, defined as the opposite of entropy, is to be determined by the way data is processed into information.
Digital osmosis, i.e the exchange of digital data between enterprises operations and environments is clearly a primary factor: inbound streams can be mined as to provide comprehensive and timely snapshots, outbound streams can be weaved into business processes, enhancing the capacity to translate decisions into action.
Digital osmosis could also bolster lean engineering with the direct integration of (digital) business logic into software (e.g using rules engines), reinforcing the shortcuts between observations and decisions whenever orientation can be avoided. That would also enhance traceability between platform specific (PSMs) and operational models, as well as the monitoring of actions and the analysis of feedbacks (process mining).
Osmosis could be easily (if not accurately) estimated with the ratio between digitized flows and the whole of data flows, with measurements weighted by delays between observations and data processing.
A taxonomy of changes
Digital and business environments are not to be confused, and there is no reason to assume that their respective changes tally. As it happens, digital transformation may reinstall organizations at the nexus of changes by providing a powerful leverage on systems; and if entropy is considered, that is to be achieved through symbolic representations, aka models.
While names may vary, a distinction is generally made between changes according to their horizon, shorter for operational or tactical ones, longer for strategic ones. As so often with quantitative classifications, that understanding has been of limited use given the diversity of time-frames across industries. The digital transformation open the door to a qualitative approach, defining changes according to the nature of of their footprint:
From the business perspective, it should restate the primacy of organization for the harnessing of IT benefits.
From the architecture perspective, it would rank assets according to “digital modality”: symbolic (information, knowledge), tangible (e.g platforms), or a combination of both (functional architecture).
Changes can be defined according to the digital modality of their footprint
Taking the strategic perspective, changes in technical or economic factorsare to affect assets and processes for a large and often undetermined number of production cycles; they must consequently be set in time-frames extending beyond managed horizons (actual chronologies depend on industries specificities). Despite regular updates, supporting models and hypothesis may lose their relevance during the intervals, with the resulting entropy hampering the assessment of opportunities and policies. Such discrepancies can be circumscribed if planned organization and computation independent models (CIMs) are systematically checked against observations.
Compared to strategic ones, functional changes can be aligned with a limited number of production cycles, which irons out most of the discrepancies between maps and territories associated with strategic planning. Instead, entropy could arise from a lack of transparency and traceability between the models used to map organization and processes (CIMs) to functional (PIMs) and technical (PSMs) architectures.
Finally, operational changes can be carried out at process level, without affecting architectures. In that case entropy could be the result of a misalignment of commitments and observations granularity.
On that basis, planning and managing changes in digital and business environments should be driven by models.
ENTROPY & maturity
As defined by cybernetics, entropy can be explained by the discrepancies between environment states (aka micro-states) and their representation (macro-states). Applied to enterprises environments and architectures, it would mean territories and operations for the former, maps and policies for the latter.
On that account the maturity of an organization should be assessed with regard to its ability to manage changes within and across environments:
Consistency of changes within environments: between territories and operations (digital environments), between maps and policies (business environments) .
Validity of changes across environments: between maps and territories, and between policies and operations.
Consistency is checked within environments, validity is checked across environments
Maturity levels could then be set according to the scope of managed entropy:
Digital osmosis: all exchanges with environments come with digital counterpart sorted with regard to operational data, data attached to managed information, environment data detached from managed information.
Digital value chains: digital integration of business and engineering processes ensuring transparency and traceability along value chains.
Organizational pivot: value chains can be redefined as to make the best of information assets.
Knowledge based architectures: enterprise layers (platforms, systems, organization) are aligned with data, information, and knowledge layers, leveraging the benefits of machine learning across enterprise organization and systems.
The way tests are designed and executed is being doubly affected by development methods and AI technologies. On one hand well-founded approaches (e.g test-driven development) are often confined to faith-based niches; on the other hand automated schemes and agile methods push many testers out of their comfort zone.
Reality check (Kader Attia)
Resetting the issue within a knowledge-based enterprise architecture would pave the way for sound methods and could open new doors for their users.
outline
Tests can be understood in terms of preventive and predictive purposes, the former with regard to actual products, the latter with regard to their forthcoming employ. On that account policies are to distinguish between:
Test plans, to be derived from requirements.
Test cases, to be collected from environments.
Test execution, to be run and monitored in simulated environments.
The objective is to cross these pursuits with knowledge architecture layers.
Test plans are derived from business requirements, either on their own at process level (e.g as users stories or activities), or combined with functional requirements at application level (e.g as use cases). Both plans describe sequences of actions meant to be performed by organizational entities identified at enterprise level. Circumstances are then specified with regard to quality of service and technical requirements.
Mapping tests to knowledge architecture layers.
Test cases’ backbones are built from business scenarii fleshed out with instances mimicking identified entities from business environment, and hypothetical decisions taken by entitled users. The generation of actual instances and decisions could be automated depending on the thoroughness and consistency of business requirements.
To be actually tested, business scenarii have to be embedded into functional ones, yet the distinction must be maintained between what pertains to business logic and what pertains to the part played by supporting systems.
By contrast, despite being built from functional scenarii, integration and acceptance ones are meant to be blind to business or functional contents, and cases can therefore be generated independently.
Unit and components tests are the building blocks of all test cases, the former rooted in business requirements, the latter in functional ones. As such they can be used to a built-in integration of tests and development.
TDD in the loop
Whatever its merits for phased projects, the development V-model suffers from a structural bias because flaws rooted in requirements, arguably the most damaging, tend to be diagnosed after designs are encoded. Test driven development (TDD) takes a somewhat opposite approach as code specifications are governed by testability. But reversing priorities may also introduce reverse issues: where the V-model’s verification and validation come too late and too wide, TDD’s may come hasty and blinkered, with local issues masking global ones. Applying the OODA (Observation, Orientation, Decision, Action) loop to test cases offers a way out of the dilemma:
Observation (West): test and assessment for component, integration, and acceptance test cases.
Orientation (North): assessment in the broader context of requirements space (business, functional, Quality of Service), or in the local context of application (East).
Decision (East): confirm or adjust the development paths with regard to functional scenarii, development backlog, or integration constraints.
Action (South): develop code at unit, component, or process levels.
From V to O: How to iterate across layers
As each station is meant to deal with business, functional, and operational test cases, the challenge is to ensure a seamless integration and reuse across iterations and layers.
managing Tests cases
Whatever the method, tests plans are meant to mirror requirements scope and structure. For architecture oriented projects, tests should be directly aligned with the targeted capabilities of architecture layers:
For architecture oriented projects test plans should be set with regard to capabilities.
For business driven projects, test plans should be set along business scenarii, with development units and associated test cases defined with regard to activities. When use cases, which cover the subset of activities supported by systems, are introduced upfront for both business and functional requirements, test plans should keep the distinction between business and functional requirements.
Stories (bottom left), activities (right), use cases (top left).
All things considered, test cases are to be comprehensively and consistently run against requirements distinct in goals (business vs architecture), layers (business, functions, platforms), or formalism (text, stories, use cases, …).
In contrast, test cases are by nature homogeneous as made of instances of objects, events, and behaviors; ontologies can therefore be used to define and manage these instances directly from models. The example below make use of instances for types (propulsion, body), car model (Renault Clio), and car (58642).
Test cases as instances of processes (integration) and activities (development)
The primary and direct benefit of representing test cases as instances in ontologies is to ensures a seamless integration and reuse of development, integration, and acceptance test cases independently of requirements context.
But the ontological approach have broader and deeper consequences: by defining test cases as instances in line with environment data, it opens the door to their enrichment through deep-learning.
knowledgeable test cases
Names may vary but tests are meant to serve a two-facet objective: on one hand to verify the intrinsic qualities of artefacts as they are, independently of context and usage; on the other hand to validate their features with regard to extrinsic circumstances, present or in a foreseeable future.
That duality has logical implications for test cases:
The verification of intrinsic properties can be circumscribed and therefore by carried out based on available information, e.g: design, programing language syntax and semantics, systems configurations, etc.
The validation of functional features and behaviors is by nature open-ended with regard to scope and time-frame; it ensues that test cases have to rely on incomplete or uncertain information.
Without practical applications that distinction has been of little consequence, until now: while the digital transformation removes the barriers between test cases and environment data, the spreading of machine learning technologies multiplies the possibilities of exchanges.
Along the traditional approach, test cases relies on three basic sources of information:
Syntax and semantics of programing languages are used to check software components (a)
Logical and functional models (including patterns) are used to check applications designs (b).
Requirements are used to check applications compliance (c).
Traditional (a,b,c) and knowledge driven (d,e,f) test cases
With barriers removed, test cases as instances can be directly aligned with environment data, opening doors to their enrichment, e.g:
Random data samples can be mined from environments and used to deal with human instinctive or erratic behaviors. By nature knee jerks or latent behavior cannot be checked with reasoned test cases, yet they neither occur in a void but within known operational of functional or circumstances; data analytics can be used to identify these quirks (d).
Systems being designed artifacts, components are meant to tally with models for structures as well as behaviors. Crossing operational data with design models will help to refine and hone integration and acceptance test cases (e).
Whereas integration tests put the focus on models and code, acceptance tests also involve the mapping of models to business and organizational concepts. As a corollary, test cases are to rely on a broader range of knowledge: external regulations, mined from environments, or embedded in organization through individual and collective skills (f).
Given the immersion of enterprises in digital environments, and assuming representing test cases as ontological instances, these are already practical opportunities. But the real benefits of knowledge based test cases are to come from leveraging machine learning technologies across enterprise and knowledge architectures.
To hear the buzz around business capabilities one would expect some consensus about basic principles as well as an established track record. Since there is little to be found on either account, should the notion be seen as a modern philosophers’ stone ?
People, System, Environment
Clear evidence can be found by asking two questions: what should be looked for, and why it can’t be found.
What is looked for
Business capabilities can be understood as a modern avatar of the medieval philosophers’ stone, a alchemical substance capable of turning base metals into gold.
In the context of corporate governance, that would mean a combination of assets blueprints and managing principles paving the way to success.
But such a quest is to err between the sands of businesses specificities and the clouds of accounting generalities.
At ground level enterprises have to mark their territory and keep it safe from competitors. Whatever the means they use (niche segments, effective organization, monopolistic situations, …,) success comes from making a difference.
With hindsight, revealing singularities may be discovered among the idiosyncrasies of business successes, but that can only be done from accounting heights, where capabilities are clouded by numbers.
why it can’t be found
The fallacy of a notion can also be established a contrario if, assuming the existence of a philosophers’ stone, the same logic would also demonstrate the futility of the quest.
Such a reasoning appears more like a truism when applied to business capabilities: insofar as business competition is concerned success is exclusive and cutting edges are not shared. It ensues that assuming business capabilities could be found, they would by the same move become obsolete and be instantly dissolved.
What should be looked for
As far as business environments are concerned, success is by nature singular and transient, and it consequently depends on sustaining a balancing act between assets and opportunities; that’s what a business model is meant to achieve.
The immersion of enterprises into digital environments and the merging of business and engineering processes are bound to impact traditional approaches to strategic planning.
Strategic planning can be summarily defined as the alignment of two kinds of horizons:
External horizons are set on markets, competition, and technologies, with views and anticipations coming through data analytics and game theory.
Internal horizons are set on enterprise architectures, with business models and policies on one hand, organization and systems on the other. Both are set on purposes, the former aiming at specificity and edge, the latter at sharing and stability.
How to manage the alignment of controlled enterprise horizons with anticipated external ones
As far as the strategic alignment of means (internal horizons) and ends (external horizons) are concerned, time is of the essence; that’s where is the fault line: whatever enterprise planned time-frames, they can only be mapped to fuzzy or unreliable ones outside. As a corollary, alignments have to be carried out either as a continuum, or through discrete and periodic adjustments to predictive models.
The future begins now
As suggested by Lewis Carroll’s Red Queen, the survival of enterprises in their evolutionary arms race doesn’t depend on their absolute speed set against some universal time-frame but on the relative one set by markets and competitors. Taking into account the role of a reliable and up-to-date basis for decision-making, strategic schemes can be characterized in terms of virtual and augmented reality:
Strategies set along predefined time-frames are by construct loosely tied to business environments since discrepancies are bound to develop during the intervals between anticipations (virtual reality) and realizations (actual reality). Hence the need of overall and planned adjustments.
By contrast, strategies set dynamically through OODA (observations, orientation, decision, action) loops can be carried out without overall anticipations; like augmented reality (AR) they mix fine-grained data observations and business intelligence with additional layers of information deemed to be relevant.
A seamless integration of OODA & Economic Intelligence
The first category has for long been a cornerstone of established strategic planning, with its implicit assumption of a conceptual gap between ‘Here and Now’ and future visions. But the induced latencies and discrepancies may become liabilities if enterprises have to continuously adjust representations and policies.
For mammals such awareness is a biological capability: any discrepancy between perceived movements and their counterpart in the vestibular system is to generate motion sickness or vertigo.
Enterprises have no such built-in mechanism yet their awareness is nonetheless contingent on the alignment of representations with observations and orientations. As a corollary, out-of-kilter time-frames and outdated schemes may remain unnoticed, introducing governance dizziness and strategic missteps.
Obsolete representations (grey) are bound to generate dizziness and missteps
Such drawbacks can be limited with decision-making set along differentiated time-frames, e.g:
Operational decisions, to be carried out within processes time-frame (a).
Architecture decisions, for changes in assets affecting the design of business processes and supporting platforms (b).
Organizational decisions, for changes affecting roles and processes (c).
Weaving fine-grained threads across enterprise architectures and consistent time-frames.
That would allow the weaving of fine-grained policies across enterprise architectures and along consistent time-frames, mixing actual observations, representations of current and planned assets and resources, and anticipations of markets changes a competitors moves.
On that basis strategic alignments would not have to be set at fixed time for overall models, but could be managed continuously, with decision-making finely tuned for targets and timing:
External horizons: business decisions could be balanced by the need to know with the reliability of available information.
Internal horizons: decisions about organization and systems could be taken at the “last responsible moment”, i.e until not taking side could change the possible options.
Strategic planning could then be defined by crossing these rationales at the relevant granularity.
The digital transformation induces fundamental changes for the exchanges between enterprises and their environment.
To begin with, their immersion into digital environments means that the traditional fences surrounding their IT systems are losing their relevance, being bypassed by massive data flows to be processed without delay.
Then, the induced osmosis upturns the competition playground and compels drastic changes in governance: less they fall behind, enterprises have to redefine their organization, systems, and processes.
Strategies are meant to draw passageways between current circumstances and conjectured horizons (Kader Attia)
New playground
Strategic thinking is first and foremost making differences with regard to markets, resources and assets, and time-frames. But what makes the digital revolution so disruptive is that it resets the ways differences are made:
Markets: the traditional distinctions between products and services are all but forgotten.
Resources and assets: with software, smart or otherwise, now tightly mixed in products fabric, and business processes now driven by knowledge, intangible assets are taking the lead on conventional ones.
Time-frames: strategies have for long been defined as a combination of anticipations, objectives and policies whose scope extends beyond managed horizons. But digital osmosis and the ironing out of markets and assets traditional boundaries are dissolving the milestones used to draw horizons perspectives.
New perspectives
To overcome these challenges enterprises strategies should focus on four pillars:
Data and Information: massive and continuous inflows of data calls for a seamless integration of data analytics (perception), information models (reasoning), and knowledge (decision-making).
Security & Confidentiality: new regulatory environments and costs of privacy breaches call for a clear distinction between data tied to identified individuals and information associated to designed categories.
Innovation: digital environments induce a new order of magnitude for the pace of technological change. Making opportunities from changes can only be achieved through collaboration mechanisms harnessing enterprise knowledge management to environments intakes.
Despite (or because) their ubiquity across powerpoint presentations, business capabilities appear under a wide range of guises. Putting them in perspectives could clarify the issue.
To begin with, business capabilities should not be confused with systems ones as they are supposed to be driven by changing environments and opportunities, in contrast to continuity, integrity, and returns on investments. Were it not for the need to juggle with both there would be no need of chief “whatever” officers.
Then, if they are to be assessed across changing contexts and concerns, business capabilities should not be tied to specific ones but focus on enterprise wherewithal :
Material: capacity and maturity of platforms with regard to changes in business processes and environments.
Functional: capacity and maturity of supporting systems with regard to changes in business processes.
Organizational: versatility and plasticity of roles and processes in dealing with changes in business opportunities.
Intelligence: information assets and ability of people to use them.
These could then be adjusted with regard to finance and time:
Strategic: assets, to be deployed and paid for across a number of business exercices.
Tactical: resources, to be deployed and paid for within single business exercices.
Particular: combined assets and resources needed to support specific value chains.
The role of enterprise architects would then to plan, assess, and manage the dynamic alignment of business and architecture capabilities.