Enterprise Architects are to jump across loops (Bruce Beasley)
When push comes to shove, deciding on a development process is to decide between instant or delayed returns, namely focusing on users needs with agile development, or taking extended features into consideration and weighting the benefits of reuse against additional costs, e.g.:
Designs to be reused as patterns.
Profiling configurations.
Structuring business process models so that they could be designed as business functions.
Formatting business logic for automated code generation.
The intricacies of stakes and decision-making processes can be set forth by applying the Observation-Orientation-Decision-Action (OODA) loop to the four views of changes: enterprise, business domains, business applications, systems:
At enterprise level the loops are triggered by changes in business environments pertaining to business model and objectives. They are supposed to affect different business domains.
Observations: Business opportunities
Orientation: Assessment of business opportunities with regard to business objectives.
Decision: Committing resources to changes in organization and processes
Action: Achieving changes in organization and processes
Changes initiated from business domains can be derived from enterprise level or the result of more specific objectives. They are supposed to affect different applications.
Observations: Business analysis
Orientation: Functional feasibility and assessment of transformation benefits.
Decision: Committing changes in functional architecture.
Action: Development, integration, tests
Changes at application level are initiated by organizational units, business or otherwise. They are supposed to be self-contained.
Observations: Users requirements
Orientation: Engineering feasibility and assessment of development options.
Decision: Choice of a development model.
Action: Development, integration, tests
Changes at system level are initiated by organizational units, including business ones (quality of service). They are supposed to affect different applications.
Observations: Process mining and operational requirements
Orientation: Operational feasibility and assessment of configurations.
Decision: Development model.
Action: Deployment and acceptance.
Given that sizeable companies with differentiated organization and business have to manage these different threads continuously and consistently, old fashioned imperative processes can only lead to paralysis. Hence the need of a declarative approach to EA workflows.
As far as enterprise architecture is concerned, the issue of scale is fogged by two confusions: one between processes and structures, the other between space and time. That square is at the core of the discipline.
Scaling Time (Tycho Brahe)
The Matter of Time
Even before the digital unfolding of environments, everybody was to agree that business is all about timing; and yet, that critical dimension remains a side issue of most enterprise architecture frameworks, which consequently fail to deal with enterprises ability to change and adapt in competitive environments.
With regard to time, the business perspective is said to be synchronic because it must continuously tally with environments constraints, opportunities, and risks.
By contrast, the engineering perspective is said to be diachronic because once fastened to requirements, developments are supposed to proceed according their own time-span.
Mixing Timescales
For enterprise architects, pairing up business and engineering momentum may look like a Fourier transform that would decompose enterprise architecture into piecemeal capabilities to be adjusted to the flow of business circumstances. But assets being by nature discrete, changes are not easily ironed out and some mechanism is necessary to align business and engineering time-frames, the former set at enterprise level and used to align enterprise architecture capabilities with business objectives, the latter set at system level and used to manage developments.
Agile methodologies solve the problem by assuming continuous deliveries disconnected from external schedules and by folding projects into detached time warps. Along with debatable scaling attempts, definitively non agile procedures are used to carry on with agile projects at system level.
As it happens, the iterative model can be upgraded to architecture level, enabling the linking of business driven changes to systems based ones without breaking agile principles:
Projects’ scope, objectives, and invariants are set with regard to enterprise architecture capabilities.
Iterations combine requirements analysis, development, and acceptance.
Increments and deliverables are defined dynamically contingent on scope and invariants.
Exit conditions (aka deliveries) are defined with regard to quality of services and technical requirements.
So-called architecture backlogs could thus be added to coordinate self-contained developments, standalone applications as well as system business functions, e.g. (invariants are in grey):
But the coordination issue remains between architecture backlogs, and adding procedures or committees shouldn’t be an option as it would seriously curb enterprise agility. By contrast, model based solutions are to ensure a constant and consistent adaptation of enterprise architectures to their environment.
The way tests are designed and executed is being doubly affected by development methods and AI technologies. On one hand well-founded approaches (e.g test-driven development) are often confined to faith-based niches; on the other hand automated schemes and agile methods push many testers out of their comfort zone.
Reality check (Kader Attia)
Resetting the issue within a knowledge-based enterprise architecture would pave the way for sound methods and could open new doors for their users.
outline
Tests can be understood in terms of preventive and predictive purposes, the former with regard to actual products, the latter with regard to their forthcoming employ. On that account policies are to distinguish between:
Test plans, to be derived from requirements.
Test cases, to be collected from environments.
Test execution, to be run and monitored in simulated environments.
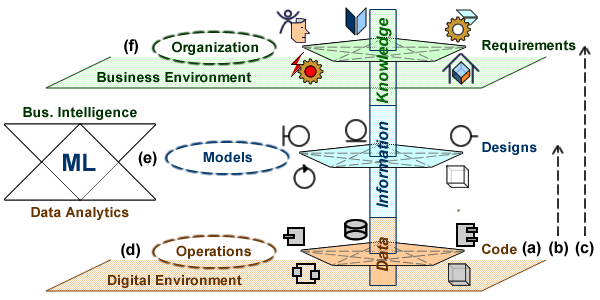
The objective is to cross these pursuits with knowledge architecture layers.
Test plans are derived from business requirements, either on their own at process level (e.g as users stories or activities), or combined with functional requirements at application level (e.g as use cases). Both plans describe sequences of actions meant to be performed by organizational entities identified at enterprise level. Circumstances are then specified with regard to quality of service and technical requirements.
Mapping tests to knowledge architecture layers.
Test cases’ backbones are built from business scenarii fleshed out with instances mimicking identified entities from business environment, and hypothetical decisions taken by entitled users. The generation of actual instances and decisions could be automated depending on the thoroughness and consistency of business requirements.
To be actually tested, business scenarii have to be embedded into functional ones, yet the distinction must be maintained between what pertains to business logic and what pertains to the part played by supporting systems.
By contrast, despite being built from functional scenarii, integration and acceptance ones are meant to be blind to business or functional contents, and cases can therefore be generated independently.
Unit and components tests are the building blocks of all test cases, the former rooted in business requirements, the latter in functional ones. As such they can be used to a built-in integration of tests and development.
TDD in the loop
Whatever its merits for phased projects, the development V-model suffers from a structural bias because flaws rooted in requirements, arguably the most damaging, tend to be diagnosed after designs are encoded. Test driven development (TDD) takes a somewhat opposite approach as code specifications are governed by testability. But reversing priorities may also introduce reverse issues: where the V-model’s verification and validation come too late and too wide, TDD’s may come hasty and blinkered, with local issues masking global ones. Applying the OODA (Observation, Orientation, Decision, Action) loop to test cases offers a way out of the dilemma:
Observation (West): test and assessment for component, integration, and acceptance test cases.
Orientation (North): assessment in the broader context of requirements space (business, functional, Quality of Service), or in the local context of application (East).
Decision (East): confirm or adjust the development paths with regard to functional scenarii, development backlog, or integration constraints.
Action (South): develop code at unit, component, or process levels.
From V to O: How to iterate across layers
As each station is meant to deal with business, functional, and operational test cases, the challenge is to ensure a seamless integration and reuse across iterations and layers.
managing Tests cases
Whatever the method, tests plans are meant to mirror requirements scope and structure. For architecture oriented projects, tests should be directly aligned with the targeted capabilities of architecture layers:
For architecture oriented projects test plans should be set with regard to capabilities.
For business driven projects, test plans should be set along business scenarii, with development units and associated test cases defined with regard to activities. When use cases, which cover the subset of activities supported by systems, are introduced upfront for both business and functional requirements, test plans should keep the distinction between business and functional requirements.
Stories (bottom left), activities (right), use cases (top left).
All things considered, test cases are to be comprehensively and consistently run against requirements distinct in goals (business vs architecture), layers (business, functions, platforms), or formalism (text, stories, use cases, …).
In contrast, test cases are by nature homogeneous as made of instances of objects, events, and behaviors; ontologies can therefore be used to define and manage these instances directly from models. The example below make use of instances for types (propulsion, body), car model (Renault Clio), and car (58642).
Test cases as instances of processes (integration) and activities (development)
The primary and direct benefit of representing test cases as instances in ontologies is to ensures a seamless integration and reuse of development, integration, and acceptance test cases independently of requirements context.
But the ontological approach have broader and deeper consequences: by defining test cases as instances in line with environment data, it opens the door to their enrichment through deep-learning.
knowledgeable test cases
Names may vary but tests are meant to serve a two-facet objective: on one hand to verify the intrinsic qualities of artefacts as they are, independently of context and usage; on the other hand to validate their features with regard to extrinsic circumstances, present or in a foreseeable future.
That duality has logical implications for test cases:
The verification of intrinsic properties can be circumscribed and therefore by carried out based on available information, e.g: design, programing language syntax and semantics, systems configurations, etc.
The validation of functional features and behaviors is by nature open-ended with regard to scope and time-frame; it ensues that test cases have to rely on incomplete or uncertain information.
Without practical applications that distinction has been of little consequence, until now: while the digital transformation removes the barriers between test cases and environment data, the spreading of machine learning technologies multiplies the possibilities of exchanges.
Along the traditional approach, test cases relies on three basic sources of information:
Syntax and semantics of programing languages are used to check software components (a)
Logical and functional models (including patterns) are used to check applications designs (b).
Requirements are used to check applications compliance (c).
Traditional (a,b,c) and knowledge driven (d,e,f) test cases
With barriers removed, test cases as instances can be directly aligned with environment data, opening doors to their enrichment, e.g:
Random data samples can be mined from environments and used to deal with human instinctive or erratic behaviors. By nature knee jerks or latent behavior cannot be checked with reasoned test cases, yet they neither occur in a void but within known operational of functional or circumstances; data analytics can be used to identify these quirks (d).
Systems being designed artifacts, components are meant to tally with models for structures as well as behaviors. Crossing operational data with design models will help to refine and hone integration and acceptance test cases (e).
Whereas integration tests put the focus on models and code, acceptance tests also involve the mapping of models to business and organizational concepts. As a corollary, test cases are to rely on a broader range of knowledge: external regulations, mined from environments, or embedded in organization through individual and collective skills (f).
Given the immersion of enterprises in digital environments, and assuming representing test cases as ontological instances, these are already practical opportunities. But the real benefits of knowledge based test cases are to come from leveraging machine learning technologies across enterprise and knowledge architectures.
As every artifact, models can be defined by nature and function. With regard to nature, models are symbolic representations, descriptive (categories of actual instances) or prescriptive (blueprints of artifacts). With regard to function, models can be likened to currency, as they serve as means of exchange, instruments of measure, or repository.
Along that understanding, models can be neatly characterized by their intent:
No use of models, direct exchange (barter) can be achieved between business analysts and software engineers.
Models are needed as medium supporting exchange between organizational units with different business or technical concerns.
Models are used to assess contents with regard to size, complexity, quality, …
Models are kept and maintained for subsequent use or reuse.
Depending on organizations, providers and customers could then be identified, as well as modeling languages.
As it’s the case of every measurement, software engineering metrics must be defined by clear targets and purposes, and using them shouldn’t affect neither of them.
On that account, a clear distinction should be maintain between business value (set independently of supporting systems), the size and complexity of functionalities, and the work effort needed for their development. As far as systems are concerned, the Function Points approach can be defined with regard to the nature of requirements (business or system), and their scope (primary for artifact, adjustment for architecture):
Measures of business requirements are based on intrinsic domain complexity (domains function points, or DFP), adjusted for activities (adjustment function point, or AFP); they are set at artifact level independently of operational constraints or supporting systems.
Business requirements metrics are added up and adjusted for operational constraints.
Functional requirements measures target the subset of business requirements meant to be supported by systems. As such they are best defined at use case level (use case function points (UCFP).
Metrics for quality of service may be specific to functionalities or contingent on architectures and operational constraints.
Whatever the difficulties of implementation, function points remain the only principled approach to software and systems assessment, and consequently to reliable engineering costs/benefits analysis and planning.
The Agile development model should not be seen as a panacea or identified with specific methodologies. Instead it should be understood as a default option to be applied whenever phased solutions can be factored out.
Agile (a,b) versus phased (d,b,c,) development processes
Characteristics: Assuming conditions are met, agile software engineering can be fully and neatly defined by a combination of users stories and iterative development.
Alternative: When conditions cannot be met, i.e when phased solutions are required, model-based system engineering frameworks should be used to integrate business-driven projects (agile) with architecture oriented ones (phased).
Variants and extensions: Even when conditions about shared ownership and continuous delivery are met, scaling issues may have to be taken into account; in that case they should be sorted out between broader business objectives on one hand, systems architecture engineering on the other hand
These guidelines are not meant to define how agile projects are to be carried out, only to determine their scope and relevance along other systems engineering processes.
Use cases and users’ stories being the two major approaches to requirements, outlining their respective scope and purpose should put projects on a sound basis.
Cases & Stories
To that end requirements should be neatly classified with regard to scope (enterprise or system) and level (architectures or processes).
Users stories are set at enterprise level independently of the part played by supporting systems.
Use cases cut across users stories and consider only the part played by supporting systems.
Business stories put users stories (and therefore processes) into the broader perspective of business models.
Business cases put use cases (and therefore applications) into the broader perspective of systems capabilities.
Position on that simple grid should the be used to identify stakeholders and pick between an engineering model, agile or phased.
All too often choosing a development method is seen as a matter of faith, to be enforced uniformly whatever the problems at hand.
Tools and problems at hand (Jacob Lawrence)
As it happens, this dogmatic approach is not limited to procedural methodologies but also affect some agile factions supposedly immunized against such rigid stances.
A more pragmatic approach should use simple and robust principles to pick and apply methods depending on development problems.
Iterative vs Phased Development
Beyond the variety of methodological dogmas and tools, there are only two basic development patterns, each with its own merits.
Iterative developments are characterized by the same activity (or a group of activities) carried out repetitively by the same organizational unit sharing responsibility, until some exit condition (simple or combined) verified.
Phased developments are characterized by sequencing constraints between differentiated activities that may or may not be carried out by the same organizational units. It must be stressed that phased development models cannot be reduced to fixed-phase processes (e.g waterfall); as a corollary, they can deal with all kinds of dependencies (organizational, functional, technical, …) and be neutral with regard to implementations (procedural or declarative).
A straightforward decision-tree can so be built, with options set by ownership and dependencies:
Shared Ownership: Agile Schemes
A project’s ownership is determined by the organizational entities that are to validate the requirements (stakeholders), and accept the products (users).
Iterative approaches, epitomized by the agile development model, is to be the default option for projects set under the authority of single organizational units, ensuring shared ownership and responsibility by business analysts and software engineers.
Projects set from a business perspective are rooted in business processes, usually through users’ stories or use cases. They are meant to be managed under the shared responsibility of business analysts and software engineers, and carried out independently of changes in architecture capabilities (a,b).
Agile Development & Architecture Capabilities
Projects set from a system perspective potentially affect architectures capabilities. They are meant to be managed under the responsibility of systems architects and carried out independently of business applications (d,b,c).
Transparency and traceability between the two perspectives would be significantly enhanced through the use of normalized capabilities, e.g from the Zachman’s framework:
Who: enterprise roles, system users, platform entry points.
What: business objects, symbolic representations, objects implementation.
How: business logic, system applications, software components.
When: processes synchronization, communication architecture, communication mechanisms.
Where: business sites, systems locations, platform resources.
It must be noted that as far as architecture and business driven cycles don’t have to be synchronized (principle of continuous delivery), the agile development model can be applied uniformly; otherwise phased schemes must be introduced.
Cross Dependencies: Phased Schemes
Cross dependencies mean that, at some point during project life-cycle, decision-making may involve organizational entities from outside the team. Two mechanisms have traditionally been used to cope with the coordination across projects:
Fixed phases processes (e.g Analysis/Design/Implementation) have shown serious shortcomings, as illustrated by notorious waterfall.
Milestones improve on fixed schemes by using check-points on development flows instead of predefined activities. Yet, their benefits remain limited if development flows are still defined with regard to the same top-down and one-fits-all activities.
Model based systems engineering (MBSE) offers a way out of the dilemma by defining flows directly from artifacts. Taking OMG’s model driven architecture (MDA) as example:
Computation Independent Models (CIMs) describe business objects and activities independently of supporting systems.
Platform Independent Models (PIMs) describe systems functionalities independently of platforms technologies.
Platform Specific Models (PSMs) describe systems components as implemented by specific technologies.
Layered Dependencies & Development Cycles with MDA
Projects can then be easily profiled with regard to footprints, dependencies, and iteration patterns (domain, service, platform, or architecture, …).
That understanding puts the light on the complementarity of agile and phased solutions, often known as scaled agile.
Digital environments and the ubiquity of software in business processes introduces a new perspective on value chains and the assessment of supporting applications.
Business & Supporting Processes (Michel Blazy)
At the same time, as software designs cannot be detached of architectures capabilities, the central question remains of allocating costs and benefits between primary and support activities .
Value Chains & Activities
The concept of value chain introduced by Porter in 1985 is meant to encompass the set of activities contributing to the delivery of a valuable product or service for the market.
Porter’s generic model
Taking from Porter’s generic model, various value chains have been refined according to business specific categories for primary and support activities.
Whatever their merits, these approaches are essentially static and fall short when the objective is to trace changes induced by business developments; and that flaw may become critical with the generalization of digital business environments:
Given the role and ubiquity of software components (not to mention smart ones), predefined categories are of little use for impact analysis.
When changes in value chains are considered, the shift of corporate governance towards enterprise architecture puts the focus on assets contribution, cutting down the relevance of activities.
Hence the need of taking into account changes, software development, and enterprise architectures capabilities.
Value Added & Software Development
While the growing interest for value chains in software engineering is bound to agile approaches and business driven developments, the issue can be put in the broader perspective of project planning.
With regard to assessment,stakeholders, start with business opportunities and look at supporting systems from a black box perspective; in return, software providers are to analyze requirements from a white box perspective, and estimate corresponding development effort and time delivery.
Assuming transparency and good faith, both parties are meant to eventually align expectations and commitments with regard to features, prices, and delivery.
With regard to policies, stakeholders put the focus on returns on investment (ROI), obtained from total cost of ownership, quality of service, and timely delivery. Providers for their part try to minimize development costs while taking into account effective use of resources and costs of opportunities. As it happens, those objectives may be carried on as non-zero sum games:
Business stakeholders foretell the actualized returns (a) to be expected from the functionalities under consideration (b).
Providers consider the solutions (b’) and estimate actualized costs (a’).
Stakeholders and providers agree on functionalities, prices and deliveries (c).
Developing the value chain
Assuming that business and engineering environments are set within different time-frames, there should be room for non-zero-sum games winding up to win-win adjustments on features, delivery, and prices.
Continuous vs Phased Alignments
Notwithstanding the constraints of strategic planning, business processes are by nature opportunistic, and their ability to be adjusted to circumstances is becoming all the more critical with the generalization of digital business environments.
Broadly speaking, the squaring of supporting applications to business value can be done continuously or by phases:
Phased alignments start with some written agreements with regard to features, delivery, and prices before proceeding with development phases.
Continuous alignment relies on direct collaboration and iterative development to shape applications according to business needs.
Phased vs Continuous Adjustments
Beyond sectarian controversies, each approach has its use:
Continuous schemes are clearly better at harnessing value chains, providing that project teams be allowed full project ownership, with decision-making freed of external dependencies or delivery constraints.
Phased schemes are necessary when value chains cannot be uniquely sourced as they take roots in different organizational units, or if deliveries are contingent on technical constraints.
In any case, it’s not a black-and-white alternative as work units and projects’ granularity can be aligned with differentiated expectations and commitments.
Work Units & Architecture Capabilities
While continuous and phased approaches are often opposed under the guises of Agile vs Waterfall, that understanding is misguided as it extends the former to a motley of self-appointed agile schemes and reduces the latter to an ill-famed archetype.
Instead, a reasoned selection of a development models should be contingent on the problems at hand, and that can be best achieved by defining work-units bottom-up with regard to the capabilities targeted by requirements:
Work units should be defined with regard to the capabilities targeted by requirements
Development patterns could then be defined with regard to architecture layers (organization and business, systems functionalities, platforms implementations) and capabilities footprint:
Phased: work units are aligned with architecture capabilities, e.g : business objects (a), business logic (b), business processes (c), users interfaces (d).
Iterative: work units are set across capabilities and defined dynamically according to development problems.
A common development framework for phased and iterative projects
That would provide a development framework supporting the assessment of iterative as well as phased projects, paving the way for comprehensive and integrated impact analysis.
Value Chains & Architecture Capabilities
As far as software engineering is concerned, the issue is less the value chain itself than its change, namely how value is to be added along the chain.
To summarize, the transition to this layout is carried out in two steps:
Conceptually, Zachman’s original “Why” column is translated into a line running across column capabilities.
Graphically, the five remaining columns are replaced by embedded pentagons, one for each architecture layer, with the new “Why” line set as an outer layer linking business value to architectures capabilities:
Mapping value chains to enterprise architectures capabilities
That apparently humdrum transformation entails a significant shift in focus and practicality:
The focus is put on organizational and business objectives, masking the ones associated to systems and platforms layers.
It makes room for differentiated granularity in the analysis of value, some items being anchored to specific capabilities, others involving cross dependencies.
Value chains can then be charted from business processes to supporting architectures, with software applications in between.
Impact Analysis
As pointed above, the crumbling of traditional fences and the integration of enterprise architectures into digital environments undermine the traditional distinction between primary and support activities.
To be sure, business drive is more than ever the defining factor for primary activities; and computing more than ever the archetype of supporting ones. But in between the once clear-cut distinctions are being blurred by a maze of digital exchanges.
In order to avoid a spaghetti heap of undistinguished connections, value chains are to be “colored” according to the nature of links:
Between architectures capabilities: business and organization (enterprise), systems functionalities, or platforms and technologies.
Between architecture layers: engineering processes.
Tracing value chains across architectures layers
When set within that framework, value chains could be navigated in both directions:
For the assessment of applications developed iteratively: business value could be compared to development costs and architecture assets’ depreciation.
For the assessment of features (functional or non functional) to be shared across business applications: value chains will provide a principled basis for standard accounting schemes.
Combined with model based system engineering that could significantly enhance the integration of enterprise architecture into corporate governance.
Computation independent models (CIMs) describe organization and business processes independently of the role played by supporting systems.
Platform independent models (PIMs) describe the functionalities supported by systems independently of their implementation.
Platform specific models (PSMs) describe systems components depending on platforms and technologies.
Engineering processes can then be phased along architecture layers (a), or carried out iteratively for each application (b).
When set across activities value chains could be engraved in CIMs and refined with PIMs and PSMs(a). Otherwise, i.e with business value neatly rooted in single business units, value chains could remain implicit along software development (b).
Models are meant to characterize categories of given (descriptive models), designed (prescriptive models), or hypothetical (predictive models) individuals.
Identity Matter (Terracotta Soldiers of Emperor Qin Shi Huang)
Insofar as purposes can be kept apart, the discrepancies in targeted individuals can be ironed out, notably by using power-types. Otherwise, e.g if modeling concerns mix business analysis with software engineering, meta-models are introduced as jack-of-all-trades to deal with mixed semantics.
But meta-models generate exponential complexity when used across domains, not to mention the open and fuzzy ones of business intelligence. What is at stake can be better understood through the way individuals are identified and represented.
Partitions & Abstraction
Since models are meant to classify instances with regard to concerns, mixing concerns is to entail mixed classifications, horizontally across domains (e.g business and accounting), or vertically along engineering cycles (e.g business and engineering).
That can be achieved with power-types, meta-classes, or ontologies.
Delegation & Power-types
Given that categories (or classes or types) represent set of instances (given, designed, or simulated), they may by themselves be regarded as symbolic instances used to manage features commonly valued by their own members.
Power-types are simultaneously categories and instances.
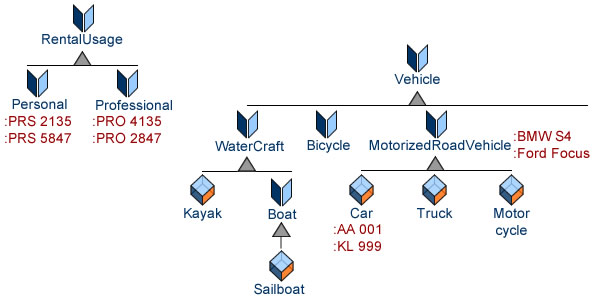
This approach is consistent as well as effective providing the semantics and identities of instances are shared by all agents concerned, e.g business and technical aspects of car rentals. Yet it falls short on both accounts when abstractions levels a set across domains, inducing connectors with different semantics and increased complexity.
Abstraction & Sub-classes
Sub-classes often appear as a way to overcome the difficulty, as illustrated by the Hepp Research’s Vehicle Sales Ontology: despite being set at different abstraction levels, instances for cars and models are defined and identified uniformly.
If, in that case, the model fulfils the substitution principle for external consistency, sub-types will fall short if engineering concerns were to be taken into account because the set of individual car models could then differ depending on perspective.
Meta-classes & Stereotypes
The overuse of meta-classes and stereotypes epitomizes the escapism school of modeling. That may be understandable, if not helpful, for the former which is by nature a free pass to abstraction; less so for the latter which is supposed to go the other way toward the specialization of meta-classes according to specific profiles. It ensues that stereotypes should never be used on their own or be extended by another stereotype.
As it happens, such consistency concerns appear to be easily diluted when stereotypes are jumbled with meta constructs; e.g:
Abstract stereotype (a).
Strong (aka class) inheritance of abstract stereotype from concrete meta-class (b).
Weak inheritance (aka aspect) between stereotypes (c, f).
Meta-constraint used to map Vehicle to methodology stereotype (d).
Domain specific connector to stereotype (e).
Without comprehensive and consistent semantics for instances and abstractions, individuals cannot be solidly mapped to models:
Individual concepts (car, horse, boat, …) have no clear mooring.
Actual vehicles cannot be tied to the meta-class or the abstract stereotype.
There is no strong inheritance tying individuals models and rental cars to an identification mechanism.
Assuming that detachment is not an option, the basis of models must be reset.
Ontologies & open concepts
Put in simple words, ontologies are meant to examine the nature and categories of existence, in general (metaphysics) or in specific contexts. As for the latter, they can be applied to individuals according to the nature of their existence (aka epistemic identity): concepts, documents, categories and aspects.
As it happens, sorting things out makes the whole paraphernalia of meta-classes and stereotypes no longer needed because the semantics of inheritance and associations can be set according to the nature of individuals.
That can be illustrated with OWL 2 and the Caminao Ontological Kernel (CaKe_WIP):
Categories associated to business entities managed through symbolic counterparts (_#): rental cars and vehicle models
Partitions (_2): structural (Body style) or functional (Rental group).
Instances of actual objects (Rental car: Clio58642) and categories (Model:Clio, Body style: Sedan, Propulsion: combustion).
With individuals solidly rooted in targeted domains, models can then fully serve their purposes.
What’s the Point
It’s worth to remind that models have to be built on purpose, which cannot be achieved without a clear understanding of context and targets. Here are some examples:
Then, individuals could be used to map models to past and future, the former for refactoring, the latter for business intelligence.
Refactoring looks to the pastbut is frustrated by undocumented legacy code. Combined with machine learning, individuals could help to bridge the gap between code and models.
Business Intelligence looks the other wayas it is meant to map hypothetical business objects and behaviors to the structures and semantics already managed by information systems. As in reversal of legacy benefits, individuals could provide cues to new business meanings.