As far as enterprise architecture is concerned, the issue of scale is fogged by two confusions: one between processes and structures, the other between space and time. That square is at the core of the discipline.
Scaling Time (Tycho Brahe)
The Matter of Time
Even before the digital unfolding of environments, everybody was to agree that business is all about timing; and yet, that critical dimension remains a side issue of most enterprise architecture frameworks, which consequently fail to deal with enterprises ability to change and adapt in competitive environments.
With regard to time, the business perspective is said to be synchronic because it must continuously tally with environments constraints, opportunities, and risks.
By contrast, the engineering perspective is said to be diachronic because once fastened to requirements, developments are supposed to proceed according their own time-span.
Mixing Timescales
For enterprise architects, pairing up business and engineering momentum may look like a Fourier transform that would decompose enterprise architecture into piecemeal capabilities to be adjusted to the flow of business circumstances. But assets being by nature discrete, changes are not easily ironed out and some mechanism is necessary to align business and engineering time-frames, the former set at enterprise level and used to align enterprise architecture capabilities with business objectives, the latter set at system level and used to manage developments.
Agile methodologies solve the problem by assuming continuous deliveries disconnected from external schedules and by folding projects into detached time warps. Along with debatable scaling attempts, definitively non agile procedures are used to carry on with agile projects at system level.
As it happens, the iterative model can be upgraded to architecture level, enabling the linking of business driven changes to systems based ones without breaking agile principles:
Projects’ scope, objectives, and invariants are set with regard to enterprise architecture capabilities.
Iterations combine requirements analysis, development, and acceptance.
Increments and deliverables are defined dynamically contingent on scope and invariants.
Exit conditions (aka deliveries) are defined with regard to quality of services and technical requirements.
So-called architecture backlogs could thus be added to coordinate self-contained developments, standalone applications as well as system business functions, e.g. (invariants are in grey):
But the coordination issue remains between architecture backlogs, and adding procedures or committees shouldn’t be an option as it would seriously curb enterprise agility. By contrast, model based solutions are to ensure a constant and consistent adaptation of enterprise architectures to their environment.
For all intents and purposes, digital transformation has opened the door to syntactic interoperability… and thus raised the issue of the semantic one.
Cooked Semantics (Urs Fisher)
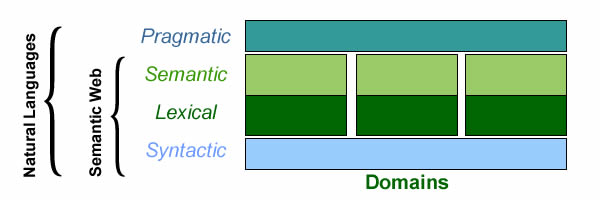
To put the issue in perspective, languages combine four levels of interpretation:
Syntax: how terms can be organized.
Lexical: meaning of terms independently of syntactic constructs.
Semantic: meaning of terms in syntactic constructs.
Pragmatic: semantics in context of use.
Languages levels of interpretation
At first, semantic networks (aka conceptual graphs) appear to provide the answer; but that’s assuming flat ontologies (aka thesaurus) within which all semantics are defined at the same level. That would go against the objective of bringing the semantics of business domains and systems architectures under a single conceptual roof. The problem and a solution can be expounded taking users stories and use cases for examples.
Crossing stories & cases
Beside the difference in perspectives, users stories and use cases stand at a methodological crossroad, the former focused on natural language, the latter on modeling. Using ontologies to ensure semantic interoperability is to enhance both traceability and transparency while making room for their combination if and when called for.
Users’ stories are part and parcel of Agile development model, their backbone, engine, and fuel. But as far as Agile is concerned, users’ stories introduce a dilemma: once being told stories are meant to be directly and iteratively put down in code; documenting them in words would bring back traditional requirements and phased development. Hence the benefits of sorting out and writing up the intrinsic elements of stories as to ensure the continuity and consistency of engineering processes, whether directly to code, or through the mediation of use cases.
To that end semantic interoperability would have to be achieved for actors, events, and activities.
Actors & Events
Whatever architectures or modeling methodologies, actors and events are sitting on systems’ fences, which calls for semantics common to enterprise organization and business processes on one side of the fence, supporting systems on the other side.
To begin with events, the distinction between external and internal ones is straightforward for use cases, because their purpose is precisely to describe the exchanges between systems and environments. Not so for users stories because at their stage the part to be played by supporting systems is still undecided, and by consequence the distinction between external and internal events.
With regard to actors, and to avoid any ambiguity, a semantic distinction could be maintained between roles, defined by organizations, and actors (UML parlance), for roles as enacted by agents interacting with systems. While roles and actors are meant to converge with analysis, understandings may initially differ across the fence between users stories and use cases, to be reconciled at the end of the day.
Representations should support the semantic distinctions as well as trace their convergence.
That would enable use cases and users stories to share overlapping yet consistent semantics for primary actors and external events:
Across stories: actors contributing to different stories affected by the same events.
Along processes: use cases set for actors and events defined in stories.
Across time-frames: actors and events first introduced by use cases before being refined by “pre-sequel” users stories.
Such ontology-based representations are to support full iterative as well as parallel developments independently of the type of methods, diagrams or documents used by projects.
activities
Users’ stories and use cases are set in different perspectives, business processes for the former, supporting systems for the latter. As already noted, their scopes overlap for events and actors which can be defined upfront providing a double distinction between roles (enterprise view) and actors (systems view), and between external and internal events.
Activities raise more difficulties because they are meant to be defined and refined across the whole of engineering processes:
From business operations as described by users to business functions as conceived by stakeholders.
From business logic as defined in business processes to their realization as defined in diagram sequences.
From functional requirements (e.g users authentication or authorization) to quality of service.
From primitives dealing with integrity constraints to business policies managed through rules engines.
To begin with, if activities have to be consistently defined for both users’ stories and use cases, their footprint should tally the description of actors and events stipulated above; taking a leaf from Aristotle rule of the three units, activity units should therefore:
Be triggered by a single event initiated by a single primary actor.
Be located into a single physical space with all resources at hand.
Timed by a single clock controlling accesses to all resources.
On that basis, the refinement of descriptions could go according to the nature of requirements: business (users’ stories), or functional and quality of service (use cases) .
Activities (execution units) should be tally with roles, events, and location.
Use cases wrap computation independent activities into transactions.
As far as ontologies are concerned, the objective is to ensure the continuity and consistency of representations independently of modeling tools and methodologies. For activities appearing in users stories and use cases, that would require:
The description of activities in relation with their business background, their execution in processes, and the corresponding functions already supported by systems.
The progressive refinement of roles (users, devices, other systems), location, and resources (objects or surrogates).
An unified definition of alternatives in stories (branches) and use cases (extension points)
The last point is of particular importance as it will determine how business and functional rules are to be defined and control implemented.
Knitting semantics: symbolic representations
The scope and complexity of semantic interoperability can be illustrated a contrario by a simple activity (checking out) described at different levels with different methods (process, use case, user story), possibly by different people at different time.
The Check-out activity is first introduced at business level (process), next a specific application is developed with agile (user story), and then extended for variants according to channels (use case).
Semantic interoperability between projects, domains, and methods.
Assuming unfettered naming (otherwise semantic interoperability would be a windfall), three parties can be mentioned under various monikers for renters, drivers, and customers.
In a flat semantic context renter could be defined as a subtype of customer, itself a subtype of party. But that option would contradict the neutrality objective as there is no reason to assume a modeling consensus across domains, methods, and time.
The ontological kernel defines parties and actors, as roles associated to agents (organization level).
Enterprises define customers as parties (business model).
Business unit can defines renters in reference to customers (business process) or directly as a subtype of role (user story).
The distinction between renters and drivers can be introduced upfront or with use cases’ actors.
That would ensure semantic interoperability across modeling paradigms and business domains, and along time and transformations.
Probing semantics: metonymies and metaphors
Once established in-depth foundations, and assuming built-in basic logic and lexical operators, semantic interoperability is to be carried out with two basic linguistic contraptions: metonymies and metaphors .
Metonymies and metaphors are linguistic constructs used to substitute a word (or a phrase) by another without altering its meaning, respectively through extensions and intensions, the former standing for the actual set of objects and behaviors, the latter for the set of features that characterize these instances.
Metonymy relies on contiguity to substitute target terms for source ones, contiguity being defined with regard to their respective extensions. For instance, given that US Presidents reside at the White House, Washington DC, each term can be used instead.
Metonymy use physical or functional proximity (full line) to match extensions (dashed line)
Metaphor uses similarity to substitute target terms for source ones, similarity being defined with regard to a shared subset of features, with leftovers taken out of the picture.
Metaphor uses similarity to match descriptions
Compared to basic thesaurus operators for synonymy, antonymy, and homonymy, which are set at lexical level, metonymy and metaphor operate at conceptual level, the former using set of instances (extensions) to probe semantics, the latter using descriptions (intensions).
Applied to users stories and use cases:
Metonymies: terms would be probed with regard to actual sets of objects, actors, events, and execution paths (data from operations) or mined from digital environments.
Metaphors: terms for stories, cases, actors, events, and activities would be probed with regard to the structure and behavior of associated descriptions (intensions).
Compared to the shallow one set at thesaurus level for terms, deep semantic interoperability encompasses all ontological dimensions, from actual instances to categories, aspects, and concepts. As such it can take full advantage of digital transformation and deep learning technologies.
Use cases and users’ stories being the two major approaches to requirements, outlining their respective scope and purpose should put projects on a sound basis.
Cases & Stories
To that end requirements should be neatly classified with regard to scope (enterprise or system) and level (architectures or processes).
Users stories are set at enterprise level independently of the part played by supporting systems.
Use cases cut across users stories and consider only the part played by supporting systems.
Business stories put users stories (and therefore processes) into the broader perspective of business models.
Business cases put use cases (and therefore applications) into the broader perspective of systems capabilities.
Position on that simple grid should the be used to identify stakeholders and pick between an engineering model, agile or phased.
As championed by a brave writer, should we see the Web as a crib for born again narratives, or as a crypt for redundant texts.
Crib or Crypt (Melik Ohanian)
Once Upon A Time
Borrowing from Einstein, “the only reason for time is so that everything doesn’t happen at once.” That befits narratives: whatever the tale or the way it is conveyed, stories take time. Even if nothing happens, a story must be spelt in tempo and can only be listened to or read one step at a time.
In So Many Words
Stories have been told before being written, which is why their fabric is made of words, and their motifs weaved by natural languages. So, even if illustrations may adorn printed narratives, the magic of stories comes from the music of their words.
A Will To Believe
To enjoy a story, listeners or readers are to detach their mind from what they believe about reality, replacing dependable and well-worn representations with new and untested ones, however shaky or preposterous they may be; and that has to be done through an act of will.
Stories are make-beliefs: as with art in general, their magic depends on the suspension of disbelief. But suspension is not abolition; while deeply submerged in stories, listeners and readers maintain some inward track to the beliefs they left before diving; wandering a cognitive fold between surface truths and submarine untruths, they seem to rely on a secure if invisible tether to the reality they know. On that account, the possibility of an alternative reality is to transform a comforting fold into a menacing abyss, dissolving their lifeline to beliefs. That could happen to stories told through the web.
Stories & Medium
Assuming time rendering, stories were not supposed to be affected by medium; that is, until McLuhan’s suggestion of medium taking over messages. Half a century later internet and the Web are bringing that foreboding in earnest by melting texts into multimedia documents.
Tweets and Short Message Services (SMS) offer a perfect illustration of the fading of text-driven communication, evolving from concise (160 characters) text-messaging to video-sharing.
That didn’t happen by chance but reflects the intrinsic visual nature of web contents, with dire consequence for texts: once lording it over entourages of media, they are being overthrown and reduced to simple attachments, just a peg above fac-simile. But then, demoting texts to strings of characters makes natural languages redundant, to be replaced by a web Esperanto.
Web Semantic Silos
With medium taking over messages, and texts downgraded to attachments, natural languages may lose their primacy for stories conveyed through the web, soon to be replaced by the so-called “semantic web”, supposedly a lingua franca encompassing the whole of internet contents.
As epitomized by the Web Ontology Language (OWL), the semantic web is based on a representation scheme made of two kinds of nodes respectively for concepts (squares) and conceptual relations (circles).
Semantic graphs (aka conceptual networks) combine knowledge representation (blue, left) and domain specific semantics (green, center & right)
Concept nodes are meant to represent categories specific to domains (green, right); that tallies with the lexical level of natural languages.
Connection nodes are used to define two types of associations:
Semantically neutral constructs to be applied uniformly across domains; that tallies with the syntactic level of natural languages (blue, left).
Domain specific relationships between concepts; that tallies with the semantic level of natural languages (green, center).
The mingle of generic (syntactic) and specific (semantic) connectors induces a redundant complexity which grows exponentially when different domains are to be combined, due to overlapping semantics. Natural languages typically use pragmatics to deal with the issue, but since pragmatics scale poorly with exponential complexity, they are of limited use for semantic web; that confines its effectiveness to silos of domain specific knowledge.
Natural Language Pragmatics As Bridges Across Domain Specific Silos
But semantic silos are probably not the best nurturing ground for stories.
Stories In Cobwebs
Taking for granted that text, time, and suspension of disbelief are the pillars of stories, their future on the web looks gloomy:
Texts have no status of their own on the web, but only appear as part of documents, a media among others.
Stories can bypass web practice by being retrieved before being read as texts or viewed as movies; but whenever they are “browsed” their intrinsic time-frame and tempo are shattered, and so is their music.
If lying can be seen as an inborn human cognitive ability, it cannot be separated from its role in direct social communication; such interactive background should also account for the transient beliefs in fictional stories. But lies detached from a live context and planted on the web are different beasts, standing on their own and bereft of any truth currency that could separate actual lies from fictional ones.
That depressing perspective is borne out by the tools supposed to give a new edge to text processing:
Hyper-links are part and parcel of internet original text processing. But as far and long as stories go, introducing links (hardwired or generated) is to hand narrative threads over to readers, and by so transforming them into “entertextment” consumers.
Machine learning can do wonders mining explicit and implicit meanings from the whole of past and present written and even spoken discourses. But digging stories out is more about anthropology or literary criticism than about creative writing.
As for the semantic web, it may work as a cobweb: by getting rid of pragmatics, deliberately or otherwise, it disables narratives by disengaging them from their contexts, cutting them out in one stroke from their original meaning, tempo, and social currency.
The Deconstruction of Stories
Curiously, what the web may do to stories seems to reenact a philosophical project which gained some favor in Europe during the second half of the last century. To begin with, the deconstruction philosophy was rooted in literary criticism, and its objective was to break the apparent homogeneity of narratives in order to examine the political, social, or ideological factors at play behind. Soon enough, a core of upholders took aim at broader philosophical ambitions, using deconstruction to deny even the possibility of a truth currency.
With the hindsight on initial and ultimate purposes of the deconstruction project, the web and its semantic cobweb may be seen as the stories nemesis.
Agile and phased development solutions are meant to solve different problems and therefore differ with artifacts and activities; that can be illustrated by requirements, understood as dialogs for the former, etched statements for the latter.
Running Stories (Kara Walker)
Ignoring that distinction is to make stories stutter from hiccupped iterations, or phases sputter along ripped milestones.
Agile & Phased Tell Different Stories Differently
As illustrated by ill-famed waterfall, assuming that requirements can be fully set upfront often put projects at the hazards of premature commitments; conversely, giving free rein to expectations could put requirements on collision courses.
That apparent dilemma can generally be worked out by setting apart business outlines from users’ stories, the latter to be scripted and coded on the fly (agile), the former analysed and documented as a basis for further developments (phased). To that end project managers must avoid a double slip:
Mission creep: happens when users’ stories are mixed with business models.
Jump to conclusions: happens when enterprise business cases prevail over the specifics of users’ concerns.
Interestingly, the distinction between purposes (users concerns vs business functions) can be set along one between language semantics (natural vs modeling).
Semantics: Capture vs Analysis
Beyond methodological contexts (agile or phased), a clear distinction should be made between requirements capture (c) and modeling (m): contrary to the former which translates sequential specifications from natural to programming (p) languages without breaking syntactic and semantic continuity, the latter carries out a double translation for dimension (sequence vs layout) and language (natural vs modeling.)
Semantic continuity (c>p) and discontinuity (c>m>p)
The continuity between natural and programming languages is at the root of the agile development model, enabling users’ stories to be iteratively captured and developed into code without intermediate translations.
That’s not the case with modeling languages, because abstractions introduce a discontinuity. As a corollary, requirements analysis is to require some intermediate models in order to document translations.
The importance of discontinuity can be neatly demonstrated by the use of specialization and generalization in models: the former taking into account new features to characterize occurrences (semantic continuity), the latter consolidating the meaning of features already defined (semantic discontinuity).
Confusion may arise when users’ stories are understood as a documented basis for further developments; and that confusion between outcomes (coding vs modeling) is often compounded by one between intents (users concerns vs business cases).
Concerns: Users’ Stories vs Business Cases
As noted above, users’ stories can be continuously developed into code because a semantic continuity can be built between natural and programming languages statements. That necessary condition is not a sufficient one because users’ stories have also to stand as complete and exclusive basis for applications.
Such a complete and exclusive mapping to application is de-facto guaranteed by continuous and incremental development, independently of the business value of stories. Not so with intermediate models which, given the semantic discontinuity, may create back-doors for broader concerns, e.g when some features are redefined through generalization. Hence the benefits of a clarity of purpose:
Users’ stories stand for specific requirements meant to be captured and coded by increments. Documentation should be limited to application maintenance and not confused with analysis models.
Use cases should be introduced when stories are to be consolidated or broader concerns factored out , e.g the consolidation of features or business cases.
Sorting out the specifics of users concerns while keeping them in line with business models is at the core of business analysts job description. Since that distinction is seldom directly given in requirements, it could be made easier if aligned on modeling options: stories and specialization for users concerns, models and generalization for business features.
From Stories to Cases
The generalization of digital environments entails structural and operational adjustments within enterprise architectures.
At enterprise level the integration of homogeneous digital flows and heterogeneous symbolic representations can be achieved through enterprise architectures and profiled ontologies. But that undertaking is contingent on the way requirements are first dealt with, namely how the specifics of users’ needs are intertwined with business designs.
As suggested above, modeling schemes could help to distinguish as well as consolidate users narratives and business outlooks, capturing the former with users’ stories and the latter with use cases models.
Use cases describe the part played by systems taking into account all supported stories.
That would neatly align means (part played by supporting systems) with ends (users’ stories vs business cases):
Users’ stories describe specific objectives independently of the part played by supporting systems.
Use cases describe the part played by systems taking into account all supported stories.
It must be stressed that this correspondence is not a coincidence: the consolidation of users’ stories into broader business objectives becomes a necessity when supporting systems are taken into account, which is best done with use cases.
Aligning Stories with Cases
Stories and models are orthogonal descriptions, the former being sequenced, the latter laid out; it ensues that correspondences can only be carried out for individuals uniformly identified (#) at enterprise and systems level, specifically: roles (aka actors), events, business objects, and execution units.
Crossing cases with stories: events, roles, business objects, and execution units must be uniformly and consistently identified (#) .
It must be noted that this principle is supposed to apply independently of the architectures or methodologies considered.
With continuity and consistency of identities achieved at architecture level, the semantic discontinuity between users’ stories and models (classes or use cases) can be managed providing a clear distinction is maintained between:
Modeling abstractions, introduced by requirements analysis and applied to artifacts identified at architecture level.
The semantics of attributes and operations, defined by users’ stories and directly mapped to classes or use cases features.
From Capture to Analysis: Abstractions introduce a semantic discontinuity
Finally, stories and cases need to be anchored to epics and enterprise architecture.
Business Cases & Enterprise Stories
Likening epics to enterprise stories would neatly frame the panoply of solutions:
At process level users’ stories and use cases would be focused respectively on specific business concerns and supporting applications.
At architecture level business stories (aka epics) and business cases (aka plots) would deal respectively with business models and objectives, and supporting systems capabilities.
Cases & Stories
That would provide a simple yet principled basis for enterprise architectures governance.
Oral cultures come with implicit codes for the repetition of words and sentences, making room for some literary hide-and-seek between the storyteller and his audience.
Stories Waiting to Happen
Could such narrative schemes be employed for users’ stories to open out the dialog between users (the storytellers) and business analysts (the listeners).
Open Storytelling
To begin with fiction, authors are meant to tell stories for readers ready to believe them at least while they are reading.
For young readers yet unable to suspend their disbelief, laser-disc games of the last century already gave post-toddlers a free hand to play with narratives.
But when the same scheme has been tried with grown-ups it has fizzled out: what would be the point of buying a story if you have to make it yourself ? the answer of agile business analysts is that users’ stories may be more pliable than budgets.
Tell Once, Tell Twice, Think Again
That’s what has just happened to “Hamlet on the Holodeck: The Future of Narrative in Cyberspace”, first published by Janet H. Murray twenty years ago with qualified ado, and now making a new debut, unedited yet clever as ever. That suggests both an observation and an interrogation.
For one, and notwithstanding readers consideration, a good story, fiction or otherwise, remains a good story which may be better appreciated in different circumstances. Then, considering the weighty mutation of circumstances since the book first appearance, the interrogation is about probable cause: should the origin of the rebirth to be looked for in technological advances, in the readers’ mind of that specific (non-fiction) book, or in the readiness of (fiction) books readers to collaborate in story building
Alternates in Narrative
As probable cause for new narrative ways, technology obviously comes first due to its means to change the relationship between readers and stories: breakthroughs in artificial intelligence, deep-learning, and computational linguistics have opened paths barely conceivable twenty years ago.
As a collateral effect of the technological revolution, opportunity may explain the renewed interest of Janet Murray’s likely readers: issues that were hardly broached before the initial publishing are now routinely mooted in the literati cognosphere.
Finally, on a broader social perspective, changes may have altered the motivation of fiction aficionados, bringing new relevancy to Janet Murray’s intuitions: as farcically illustrated by the uncritical audiences for alternative facts, the perception of reality may have been transformed by the utter sway of social networks.
Back to a literary perspective, evidences seem to point to the status of stories with regard to reality:
When embedded in games, stories don’t pretend to anything. On that ground changes are driven by players’ decisions regarding events or characters’ options that only affect the narratives of a plot defined upfront.
When set as fictions, stories, however preposterous, are meant to stand on their own ground. The meanings given to events and options are constitutive of the plot, and readers’ decisions are driven by their understanding of facts and behaviors.
So, Google’s AlphaGo may have overturned the grounds for the first category, but stories are not games and the only variants that count are the ones affecting understanding. More so for stories that use fictional realities to tell what should be.
Heed & Lead in Users’ Stories
Users’ stories are the agile answer to the challenge of elusive requirements. Definitively a cornerstone of the agile approach to software engineering, users’ stories are meant to deal with the instability of requirements, in contours as well as detours.
With regard to contours, users’ stories explore the space of requirements through successive iterations rooted into clearly identified users’ needs. Whereas the backbone (the plot) is set by stakeholders (the authors), the scope doesn’t have to be revealed upfront but can be progressively discovered through interactions between users (the storytellers) and analysts (the listeners).
But detours are where alternates in narratives may really prove themselves by helping to adjust users’ needs (the narratives) to business objectives (the plot). As a consequence changes suggested by analysts should not be limited to users’ options and ergonomy but may also concern the meaning of facts and behaviors. Along that reasoning users’ stories would use the agility of words to align the meanings of new business applications with the ones set by business functionalities already supported by systems.
As originally defined by Ivar Jacobson, uses cases (UCs) are focused on the interactions between users and systems. The question is how to associate UC requirements, by nature local, concrete, and changing, with broader business objectives set along different time-frames.
Cases, Kites, and Clouds (Sigmar Polke)
Backing Use Cases
On the system side UCs can be neatly traced through the other UML diagrams for classes, activities, sequence, and states. The task is more challenging on the business side due to the diversity of concerns to be defined with other languages like Business Process Modeling Notation (BPMN).
Use Cases contexts
Broadly speaking, tracing use cases to their business environments have been undertaken with two approaches:
Differentiated use cases, as epitomized by Alister Cockburn’s seminal book (Readings).
Business use cases, to be introduced beside standard (often renamed as “system”) use cases.
As it appears, whereas Cockburn stays with UCs as defined by Jacobson but refines them to deal specifically with generalization, scaling, and extension, the second approach introduces a somewhat ill-defined concept without setting apart the different concerns.
Differentiated Use Cases
Being neatly defined by purposes (aka goals), Cockburn’s levels provide a good starting point:
Users: sea level (blue).
Summary: sky, cloud and kite (white).
Functions: underwater, fish and clam (indigo).
As such they can be associated with specific concerns:
Cockburn’s differentiated use cases
Blue level UCs are concrete; that’s where interactions are identified with regard to actual agents, place, and time.
White level UCs are abstract and cannot be instanciated; cloud ones are shared across business processes, kite ones are specific.
Indigo level UCs are concrete but not necessarily the primary source of instanciation; fish ones may or may not be associated with business functions supported by systems (grey), e.g services , clam ones are supposed to be directly implemented by system operations.
As illustrated by the example below, use cases set at enterprise or business unit level can also be concrete:
Example with actors for users and legacy systems (bold arrows for primary interactions)
Compared to Cockburn’s efficient (no new concept) and clear (qualitative distinctions) scheme, the business use case alternative adds to the complexity with a fuzzy new concept based on quantitative distinctions like abstraction levels (lower for use cases, higher for business use cases) or granularity (respectively fine- and coarse-grained).
At first sight, using scales instead of concepts may allow a seamless modeling with the same notations and tools; but arguing for unified modeling goes against the introduction of a new concept. More critically, that seamless approach seems to overlook the semantic gap between business and system modeling languages. Instead of three-lane blacktops set along differentiated use cases, the alignment of business and system concerns is meant to be achieved through a medley of stereotypes, templates, and profiles supporting the transformation of BPMN models into UML ones.
But as far as business use cases are concerned, transformation schemes would come with serious drawbacks because the objective would not be to generate use cases from their business parent but to dynamically maintain and align business and users concerns. That brings back the question of the purpose of business use cases:
Are BUCs targeting business logic ? that would be redundant because mapping business rules with applications can already be achieved through UML or BPMN diagrams.
Are BUCs targeting business objectives ? but without a conceptual definition of “high levels” BUCs are to remain nondescript practices. As for the “lower levels” of business objectives, users’ stories already offer a better defined and accepted solution.
If that makes the concept of BUC irrelevant as well as confusing, the underlying issue of anchoring UCs to broader business objectives still remains.
Conclusion: Business Case for Use Cases
With the purposes clearly identified, the debate about BUC appears as a diversion: the key issue is to set apart stable long-term business objectives from short-term opportunistic users’ stories or use cases. So, instead of blurring the semantics of interactions by adding a business qualifier to the concept of use case, “business cases” would be better documented with the standard UC constructs for abstraction. Taking Cockburn’s example:
Abstract use cases: no actor (19), no trigger (20), no execution (21)
Different levels of abstraction can be combined, e.g:
Business rules at enterprise level: “Handle Claim” (19) is focused on claims independently of actual use cases.
Interactions at process level: “Handle Claim” (21) is focused on interactions with Customer independently of claims’ details.
Broader enterprise and business considerations can then be documented depending on scope.
As Aristotle noted some time ago, plots are the backbone of any story as they uphold the causal sequence of events and actions: they provide the “why” of what happens, compared to narratives, which tell “how” what happened is being told.
Only shadows will tell: as far as stories are concerned, possibilities remain unknown until their realization.
So, in principle, plots deal with possibilities and narratives with realizations. But in fact plots remain unknown until being narrated; in other words fictions are like Schrödinger’s cat: there is no way to set possibilities and realizations apart.
That literary conundrum may convey some useful clues for business analysis, with stakeholders objectives seen as plots, and users’ stories as narratives.
Stakeholders’ Plots vs Users’ Narratives
With regard to the functionalities of supporting systems, a key issue for business analysts is to accommodate specific and/or short-term opportunities identified by business units with broader and long-standing objectives defined at corporate level.
Using the fictional metaphor, business expectations can be charted in terms of plots and narratives:
Business objectives (as plots) are meant to apply continuously and consistently to different agents, different concerns, and different contexts. As such they are best defined as rules and constraints (declarative schemes).
Users’ stories (as narratives) are supposed to translate as soon as possible into business transactions. As such they are best defined as sequences of operations governed by users’ choices (procedural schemes).
Then, just like narratives are meant to carry out the plots, users’ stories are supposed to follow the paths set by business objectives. But if confusion is to be avoided between strategic orientations, regulatory directives, and opportunist moves, the walk of business objectives and the talk of users’ stories should be termed differently.
Business Objectives (Plots): Symbolic & Allochronic
The definition of business objectives has to find its terms between the Charybdis of abstractions and the Scylla of specific business processes, the former to be avoided because they are by nature detached from reality and only make sense with regard to models, the latter because they would be too specific and restrictive. In-between, business objectives would be best defined through:
Strategic and financial objectives expressed using symbolic categories applied to environments, products, and resources.
Modal time-frames identified in reference to events and qualified by assumptions with regard to symbolic categories.
Business functions to be optimized given a set of constraints.
These could be comprehensively and consistently expressed with declarative languages.
Users’ Stories (Narratives): Actual & Contemporaneous
Users’ stories are at their best when tied to specific circumstances and purposes without being led away by modeling concerns. As narratives they should stick to agents, triggering events, and scripted sequences of options, operations, and outcomes:
Compared to the symbolic categories used for business objectives, users stories should refer to actual subsets of objects and events defined on contexts.
Contrary to the modal time-frames of business objectives, the scripts of users’ stories must be fully timed with regard to their triggering events.
That can only be expressed as procedures.
From Fiction to Artifacts: Aligning Business Objectives & Enterprise Architectures
Likening business analysis to its distant literary kin goes beyond the metaphor as it points to a practical organization of business objectives and users’ stories.
And the benefits of the distinction between declarative (for business plots) and procedural (for users’ narratives) blueprints is not limited to business analysis but can be extended to systems architecture (as plots) and software design (as narratives). On that basis declarative schemes could be applied to business functions and architectures capabilities, and procedural ones to users’ stories (or use cases) and software design.
As illustrated by the recent Mashable “pivot”, meaningful (i.e unbranded) contents appear to be the main casualty of new communication technologies. Hopefully (sic), bots may point to a more positive perspective, at least if their want for no no-nonsense gist is to be trusted.
Could bots restore the music of words ? (Latifa Echakhch)
The Mashable Pivot to “branded” Stories
Announcing Mashable recent pivot, Pete Cashmore (Mashable ‘s founder and CEO) was very candid about the motives:
“What our advertisers value most about Mashable is the same thing that our audience values: Our content. The world’s biggest brands come to us to tell stories of digital culture, innovation and technology in an optimistic and entertaining voice. As a result, branded content has become our fastest growing revenue stream over the past year. Content is now at the core of our ad offering and we plan to double down there.”
Also revealing was the semantic shift in a single paragraph: from “stories”, to “stories told with an optimistic and entertaining voice”, and finally to “branded stories”; as if there was some continuity between Homer’s Iliad and Outbrain’s gibberish.
Spinning Yarns
From Lacan to Seinfeld, it has often been said that stories are what props up our world. But that was before Twitter, Facebook, YouTube and others ruled over the waves and screens. Nowadays, under the combined assaults of smart dummies and instant messaging, stories have been forced to spin advertising schemes, and scripts replaced by subliminal cues entangled in webs of commercial hyperlinks. And yet, somewhat paradoxically, fictions may retrieve some traction (if not spirit) of their own, reprieved not so much by human cultural thirst as by smartphones’ hunger for fresh technological contraptions.
Apps: What You Show is What You Get
As far as users are concerned, apps often make phones too smart by half: with more than 100 billion of apps already downloaded, users face an embarrassment of riches compounded by the inherent limitations of packed visual interfaces. Enticed by constantly renewed flows of tokens with perfunctory guidelines, human handlers can hardly separate the wheat from the chaff and have to let their choices be driven by the hypothetical wisdom of the crowd. Whatever the outcomes (crowds may be right but often volatile), the selection process is both wasteful (choices are ephemera, many apps are abandoned after a single use, and most are sparely used), and hazardous (too many redundant dead-ends open doors to a wide array of fraudsters). That trend is rapidly facing the physical as well as business limits of a zero-sum playground: smarter phones appear to make for dumber users. One way out of the corner would be to encourage intelligent behaviors from both parties, humans as well as devices. And that’s something that bots could help to bring about.
Bots: What You Text Is What You Get
As software agents designed to help people find their ways online, bots can be differentiated from apps on two main aspects:
They reside in the cloud, not on personal devices, which means that updates don’t have to be downloaded on smartphones but can be deployed uniformly and consistently. As a consequence, and contrary to apps, the evolution of bots can be managed independently of users’ whims, fostering the development of stable and reliable communication grammars.
They rely on text messaging to communicate with users instead of graphical interfaces and visual symbols. Compared to icons, text put writing hands on driving wheels, leaving much less room for creative readings; given that bots are not to put up with mumbo jumbo, they will prompt users to mind their words as clearly and efficiently as possible.
Each aspect reinforces the other, making room for a non-zero playground: while the focus on well-formed expressions and unambiguous semantics is bots’ key characteristic, it could not be achieved without the benefits of stable and homogeneous distribution schemes. When both are combined they may reinstate written languages as the backbone of communication frameworks, even if it’s for the benefits of pidgin languages serving prosaic business needs.
A Literary Soup of Business Plots & Customers Narratives
Given their need for concise and unambiguous textual messages, the use of bots could bring back some literary considerations to a latent online wasteland. To be sure, those considerations are to be hard-headed, with scripts cut to the bone, plots driven by business happy ends, and narratives fitted to customers phantasms.
Nevertheless, good storytelling will always bring some selective edge to businesses competing for top tiers. So, and whatever the dearth of fictional depth, the spreading of bots scripts could make up some kind of primeval soup and stir the emergence of some literature untainted by its fouled nourishing earth.
Content discovery and the game of Go can be used to illustrate the strengths and limits of artificial intelligence.
Now and Then: contents discovery across media and generations (Pavel Wolberg)
Game of Go: Closed Ground, Non Semantic Charts
The conclusive successes of Google’s AlphaGo against world’s best players are best understood when related to the characteristics of the game of Go:
Contrary to real life competitions, games are set on closed and standalone playgrounds detached from actual concerns. As a consequence players (human or artificial) can factor out emotions from cognitive behaviors.
Contrary to games like Chess, Go’s playground is uniform and can be mapped without semantic distinctions for situations or moves. Whereas symbolic knowledge, explicit or otherwise, is still required for good performances, excellence can only be achieved through holistic assessments based on intuition and implicit knowledge.
Both characteristics fully play to the strengths of AI, in particular computing power (to explore playground and alternative strategies) and detachment (when decisions have to be taken).
Content Discovery: Open Grounds, Semantic Charts
Content discovery platforms like Outbrain or Taboola are meant to suggest further (commercial) bearings to online users. Compared to the game of Go, that mission clearly goes in the opposite direction:
Channels may be virtual but users are humans, with real emotions and concerns. And they are offered proxy grounds not so much to be explored than to be endlessly redefined and made more alluring.
Online strolls may be aimless and discoveries fortuitous, but if content discovery devices are to underwrite themselves, they must bring potential customers along monetized paths. Hence the hitch: artificial brains need some cues about what readers have in mind.
That makes content discovery a challenging task for artificial coaches as they have to usher wanderers with idiosyncratic but unknown motivations through boundless expanses of symbolic shopping fields.
What Would Eliza Say
When AI was still about human thinking Alan Turing thought of a test that could check the ability of a machine to exhibit intelligent behaviors. As it was then, available computing power was several orders of magnitude below today’s capacities, so the test was not about intelligence itself, but with the ability to conduct text-based dialogues equivalent to, or indistinguishable from, that of a human. That approach was famously illustrated by Eliza, a software able to beguile humans in conversations without any understanding of their meanings.
More than half a century later, here are some suggestions of leading content discovery engines:
After reading about the Ecuador quake or Syrian rebels one is supposed to be interested by 8 tips to keep our liver healthy, or 20 reasons of unsuccessful attempts at losing weight.
After reading about growing coffee in Ethiopia one is supposed to be interested by the mansions of world billionaires, or a Shepard pup surviving after being lost at sea for a month.
It’s safe to assume that both would have flunked the Turing Test.