Preamble
For all intents and purposes, digital transformation has opened the door to syntactic interoperability… and thus raised the issue of the semantic one.

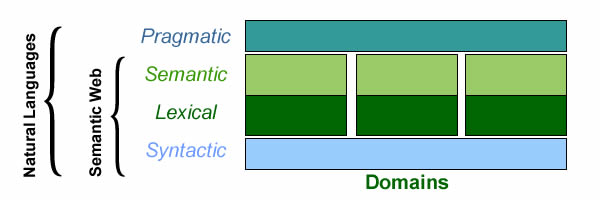
To put the issue in perspective, languages combine four levels of interpretation:
- Syntax: how terms can be organized.
- Lexical: meaning of terms independently of syntactic constructs.
- Semantic: meaning of terms in syntactic constructs.
- Pragmatic: semantics in context of use.

At first, semantic networks (aka conceptual graphs) appear to provide the answer; but that’s assuming flat ontologies (aka thesaurus) within which all semantics are defined at the same level. That would go against the objective of bringing the semantics of business domains and systems architectures under a single conceptual roof. The problem and a solution can be expounded taking users stories and use cases for examples.
Crossing stories & cases
Beside the difference in perspectives, users stories and use cases stand at a methodological crossroad, the former focused on natural language, the latter on modeling. Using ontologies to ensure semantic interoperability is to enhance both traceability and transparency while making room for their combination if and when called for.
Set at the inception of software engineering processes, users’ stories and use cases mark an inflexion point between business requirements and supporting systems functionalities: where and when are determined (a) the nature of interfaces between business processes and systems components and, (b) how to proceed with development models, iterative or model based.
Users’ stories are part and parcel of Agile development model, their backbone, engine, and fuel. But as far as Agile is concerned, users’ stories introduce a dilemma: once being told stories are meant to be directly and iteratively put down in code; documenting them in words would bring back traditional requirements and phased development. Hence the benefits of sorting out and writing up the intrinsic elements of stories as to ensure the continuity and consistency of engineering processes, whether directly to code, or through the mediation of use cases.
To that end semantic interoperability would have to be achieved for actors, events, and activities.
Actors & Events
Whatever architectures or modeling methodologies, actors and events are sitting on systems’ fences, which calls for semantics common to enterprise organization and business processes on one side of the fence, supporting systems on the other side.
To begin with events, the distinction between external and internal ones is straightforward for use cases, because their purpose is precisely to describe the exchanges between systems and environments. Not so for users stories because at their stage the part to be played by supporting systems is still undecided, and by consequence the distinction between external and internal events.
With regard to actors, and to avoid any ambiguity, a semantic distinction could be maintained between roles, defined by organizations, and actors (UML parlance), for roles as enacted by agents interacting with systems. While roles and actors are meant to converge with analysis, understandings may initially differ across the fence between users stories and use cases, to be reconciled at the end of the day.


That would enable use cases and users stories to share overlapping yet consistent semantics for primary actors and external events:
- Across stories: actors contributing to different stories affected by the same events.
- Along processes: use cases set for actors and events defined in stories.
- Across time-frames: actors and events first introduced by use cases before being refined by “pre-sequel” users stories.
Such ontology-based representations are to support full iterative as well as parallel developments independently of the type of methods, diagrams or documents used by projects.
activities
Users’ stories and use cases are set in different perspectives, business processes for the former, supporting systems for the latter. As already noted, their scopes overlap for events and actors which can be defined upfront providing a double distinction between roles (enterprise view) and actors (systems view), and between external and internal events.
Activities raise more difficulties because they are meant to be defined and refined across the whole of engineering processes:
- From business operations as described by users to business functions as conceived by stakeholders.
- From business logic as defined in business processes to their realization as defined in diagram sequences.
- From functional requirements (e.g users authentication or authorization) to quality of service.
- From primitives dealing with integrity constraints to business policies managed through rules engines.
To begin with, if activities have to be consistently defined for both users’ stories and use cases, their footprint should tally the description of actors and events stipulated above; taking a leaf from Aristotle rule of the three units, activity units should therefore:
- Be triggered by a single event initiated by a single primary actor.
- Be located into a single physical space with all resources at hand.
- Timed by a single clock controlling accesses to all resources.
On that basis, the refinement of descriptions could go according to the nature of requirements: business (users’ stories), or functional and quality of service (use cases) .


As far as ontologies are concerned, the objective is to ensure the continuity and consistency of representations independently of modeling tools and methodologies. For activities appearing in users stories and use cases, that would require:
- The description of activities in relation with their business background, their execution in processes, and the corresponding functions already supported by systems.
- The progressive refinement of roles (users, devices, other systems), location, and resources (objects or surrogates).
- An unified definition of alternatives in stories (branches) and use cases (extension points)
The last point is of particular importance as it will determine how business and functional rules are to be defined and control implemented.
Knitting semantics: symbolic representations
The scope and complexity of semantic interoperability can be illustrated a contrario by a simple activity (checking out) described at different levels with different methods (process, use case, user story), possibly by different people at different time.
The Check-out activity is first introduced at business level (process), next a specific application is developed with agile (user story), and then extended for variants according to channels (use case).

Assuming unfettered naming (otherwise semantic interoperability would be a windfall), three parties can be mentioned under various monikers for renters, drivers, and customers.
In a flat semantic context renter could be defined as a subtype of customer, itself a subtype of party. But that option would contradict the neutrality objective as there is no reason to assume a modeling consensus across domains, methods, and time.
- The ontological kernel defines parties and actors, as roles associated to agents (organization level).
- Enterprises define customers as parties (business model).
- Business unit can defines renters in reference to customers (business process) or directly as a subtype of role (user story).
- The distinction between renters and drivers can be introduced upfront or with use cases’ actors.

That would ensure semantic interoperability across modeling paradigms and business domains, and along time and transformations.
Probing semantics: metonymies and metaphors
Once established in-depth foundations, and assuming built-in basic logic and lexical operators, semantic interoperability is to be carried out with two basic linguistic contraptions: metonymies and metaphors .
Metonymies and metaphors are linguistic constructs used to substitute a word (or a phrase) by another without altering its meaning, respectively through extensions and intensions, the former standing for the actual set of objects and behaviors, the latter for the set of features that characterize these instances.
Metonymy relies on contiguity to substitute target terms for source ones, contiguity being defined with regard to their respective extensions. For instance, given that US Presidents reside at the White House, Washington DC, each term can be used instead.

Metaphor uses similarity to substitute target terms for source ones, similarity being defined with regard to a shared subset of features, with leftovers taken out of the picture.

Compared to basic thesaurus operators for synonymy, antonymy, and homonymy, which are set at lexical level, metonymy and metaphor operate at conceptual level, the former using set of instances (extensions) to probe semantics, the latter using descriptions (intensions).
Applied to users stories and use cases:
- Metonymies: terms would be probed with regard to actual sets of objects, actors, events, and execution paths (data from operations) or mined from digital environments.
- Metaphors: terms for stories, cases, actors, events, and activities would be probed with regard to the structure and behavior of associated descriptions (intensions).
Compared to the shallow one set at thesaurus level for terms, deep semantic interoperability encompasses all ontological dimensions, from actual instances to categories, aspects, and concepts. As such it can take full advantage of digital transformation and deep learning technologies.
further reading
- How to Mind a Tree Story
- From Stories to Models
- Agile & Models
- The agility of words
- Agile Business Analysis: From Wonders to Logic
- Spaces, Paths, Paces (Part 1)
- Spaces, Paths, Paces (Part 2)
- Business Stories: Stakeholders’ Plots & Users’ Narratives
- Focus: Users’ Stories & Use Cases
- Boost Your Mind Mapping
- Economic Intelligence & Semantic Galaxies
- Open Ontologies: From Silos to Architectures
- Ontologies & Enterprise Architecture,
- Systems, Information, Knowledge
- Knowledge Architecture
- Ontologies & Models
- Enterprise Governance & Knowledge
- Data Mining & Requirements Analysis
- Ontologies as Productive Assets
- Caminao Ontological Kernel (Protégé/OWL 2)
- Focus: Individuals in Models





































{kind=link}