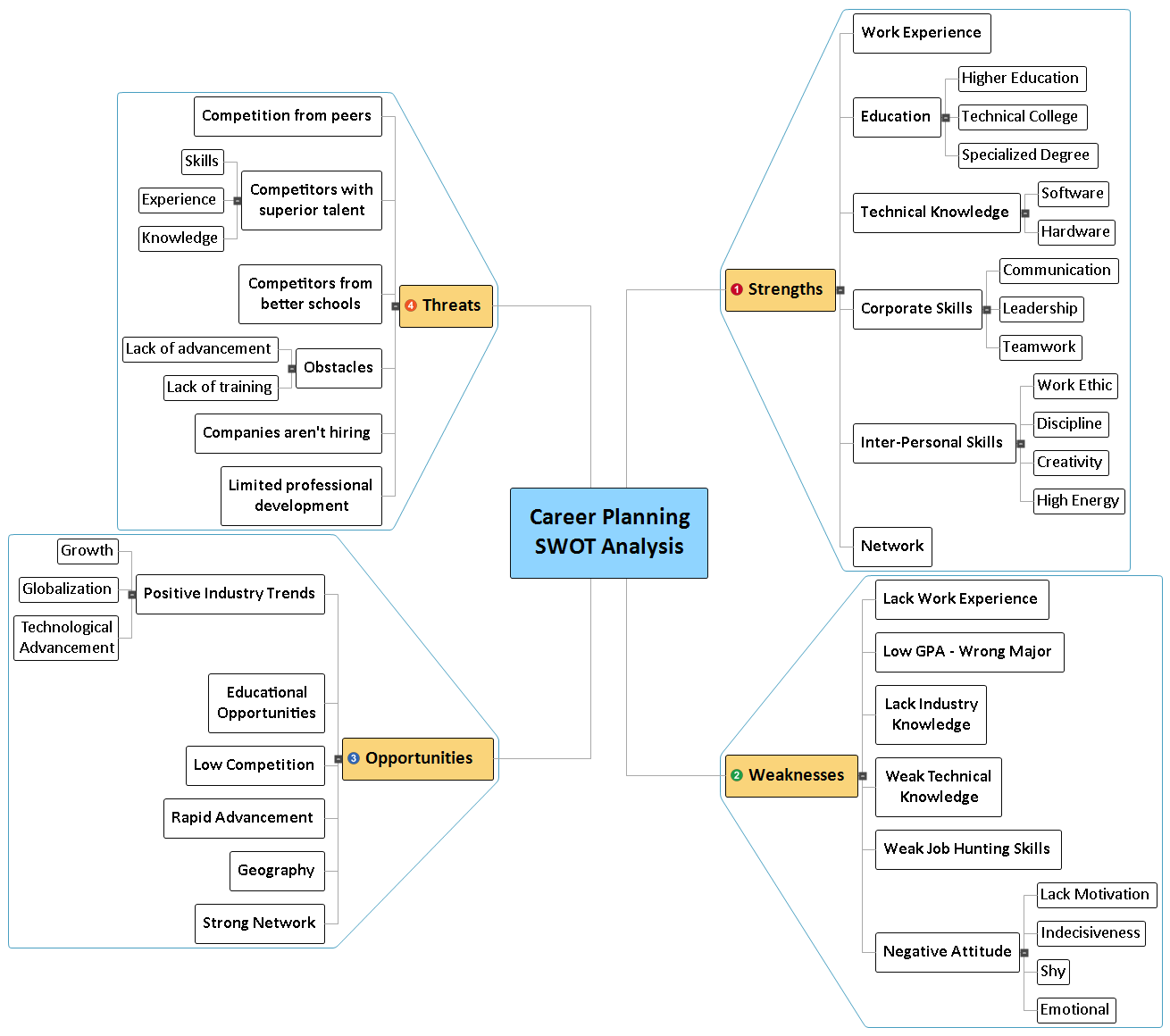
Assuming that intelligence is the capacity to learn, three kind of motifs should be considered:
Data, for facts from physical and symbolic environments
Information, for categories giving structure and meaning to data
Knowledge, for concepts adding purposes to information
The Fabric of Intelligence
These motifs serve three kinds of motives: communication between agents; representation of contexts, concerns, and conversations; imagination of alternatives realities.
That taxonomy neatly coincides with Spinoza’s philosophical one: data for senses and beliefs, information for reason, and knowledge for judgment..
Four Threads
Intelligence can thus be characterized by four cognitive operations:
Deduction infers individual facts from categories’ features
Induction: infers categories’ features from observed facts
Abduction: adds conceptual explanations to induction
Intuition: makes direct associations between experience (facts) and beliefs (concepts)
Necessary (solid line) and non-necessary (dotted line) Inference patterns
Induction, deduction, and abduction may arguably be performed by artificial brains providing traceability; that’s not the case for intuition because it involves accountability.
Brains’ Capabilities
The 3*4 taxonomy of intelligence’s motifs and threads can then be used to characterize brains’ capabilities in terms of problem solving.
To begin with the representation of issues:
Symbolic representation can rely on functions (data), models (information), and semantic or conceptual graphs (explicit knowledge)
Alternatively, non symbolic representation can start with digits (data), documents (information), and neural networks (implicit knowledge)
Brains’ Capabilities
Problem solving itself will make use of:
Symbolic representation: deduction (data), induction (information), and abduction (knowledge)
Non symbolic representation: data analytics (data), pattern matching (information), and Machine learning (implicit knowledge)
Capabilities can then be used to draw a line between natural and artificial brains.
Artificial vs Natural Brains
The enterprises immersion in digital environments combined with the ubiquity of Artificial intelligence and Machine learning technologies have put traceability and accountability on top of design issues; hence the need to set the limits of artificial brains:
Artificial brains can build and process symbolic and non symbolic representations
Artificial brains can solve problems applying logic and abstraction or data analytics, respectively to symbolic and non symbolic representations
Like natural ones, artificial brains combine sensory-motor capabilities with purely cognitive ones
Like human ones, and apart from sensory-motor capabilities, artificial brains support a degree of cognitive plasticity and versatility between symbolic and non symbolic representation and processing.
While artificial brains’ capabilities appear to match human ones, that’s not the case fall when shortfalls in traceability (e.g., with abduction or intuitions) must be supplemented by judgements’ accountability.
Artificial General Intelligence
While still an open-ended field of research, the debate about Artificial ‘General’ Intelligence (AGI) can be summarized in terms of scope or agents.
Regarding scope the debate turns around the ability of Machine learning technologies to:
Reproduce human implicit knowledge and intuition
Deal consciously with actual and virtual realities
As both issues remain shrouded in the mystery of individual consciousness, it might be worth to consider the collective dimension of general intelligence. Applying the principle to enterprises:
Motifs: intelligence rooted in operations (facts), organization (concepts) and systems (categories)
Motives: intelligence driven by business processes (communication), information management (representation), and planning and decision-making (imagination)
A Collective perspective (green circle) of ‘General’ intelligence
Implicit knowledge and intuition would be rooted in data and process mining, and weaved with the fabric of consciousness built from a continuous adjustment of managed (actual) and planned (virtual) realities.
Turning thoughts into figures faces the intrinsic constraint of dimension: two dimensional representations cannot cope with complexity.
Making his mind about knowledge dimensions: actual world, descriptions, and reproductions (Jan van der Straet)
So, lest they be limited to flat and shallow thinking, mind cartographers have to introduce the cognitive equivalent of geographical layers (nature, demography, communications, economy,…), and archetypes (mountains, rivers, cities, monuments, …)
Nodes: What’s The Map About
Nodes in maps (aka roots, handles, …) are meant to anchor thinking threads. Given that human thinking is based on the processing of symbolic representations, mind mapping is expected to progress wide and deep into the nature of nodes: concepts, topics, actual objects and phenomena, artifacts, partitions, or just terms.
What’s The Map About
It must be noted that these archetypes are introduced to characterize symbolic representations independently of domain semantics.
Connectors: Cognitive Primitives
Nodes in maps can then be connected as children or siblings, the implicit distinction being some kind of refinement for the former, some kind of equivalence for the latter. While such a semantic latitude is clearly a key factor of creativity, it is also behind the poor scaling of maps with complexity.
A way to frame complexity without thwarting creativity would be to define connectors with regard to cognitive primitives, independently of nodes’ semantics:
References connect nodes as terms.
Associations: connect nodes with regard to their structural, functional, or temporal proximity.
Analogies: connect nodes with regard to their structural or functional similarities.
At first, with shallow nodes defined as terms, connections can remain generic; then, with deeper semantic levels introduced, connectors could be refined accordingly for concepts, documentation, actual objects and phenomena, artifacts,…
Connectors are aligned with basic cognitive mechanisms of metonymy (associations) and analogy (similarities)
Semantics: Extensional vs Intensional
Given mapping primitives defined independently of domains semantics, the next step is to take into account mapping purposes:
Extensional semantics deal with categories of actual instances of objects or phenomena.
Intensional semantics deal with specifications of objects or phenomena.
That distinction can be applied to basic semantic archetypes (people, roles, events, …) and used to distinguish actual contexts, symbolic representations, and specifications, e.g:
Extensions (full border) are about categories of instances, intensions (dashed border) are about specifications
Car (object) refers to context, not to be confused with Car (surrogate) which specified the symbolic counterpart: the former is extensional (actual instances), the latter intensional (symbolic representations)
Maintenance Process is extensional (identified phenomena), Operation is intensional (specifications).
Reservation and Driver are symbolic representations (intensional), Person is extensional (identified instances).
It must be reminded that whereas the choice is discretionary and contingent on semantic contexts and modeling purposes (‘as-it-is’ vs ‘as-it-should-be’), consequences are not because the choice is to determine abstraction semantics.
For example, the records for cars, drivers, and reservations are deemed intensional because they are defined by business concerns. Alternatively, instances of persons and companies are defined by contexts and therefore dealt with as extensional descriptions.
Abstractions: Subsets & Sub-types
Thinking can be characterized as a balancing act between making distinctions and managing the ensuing complexity. To that end, human edge over other animal species is the use of symbolic representations for specialization and generalization.
That critical mechanism of human thinking is often overlooked by mind maps due to a confused understanding of inheritance semantics:
Strong inheritance deals with instances: specialization define subsets and generalization is defined by shared structures and identities.
Weak inheritance deals with specifications: specialization define sub-types and generalization is defined by shared features.
Inheritance semantics: shared structures (dark) vs shared features (white)
The combination of nodes (intension/extension) and inheritance (structures/features) semantics gives cartographers two hands: a free one for creative distinctions, and a safe one for the ensuing complexity. e.g:
Intension and weak inheritance: environments (extension) are partitioned according to regulatory constraints (intension); specialization deals with subtypes and generalization is defined by shared features.
Extension and strong inheritance: cars (extension) are grouped according to motorization; specialization deals with subsets and generalization is defined by shared structures and identities.
Intension and strong inheritance: corporate sub-type inherits the identification features of type Reservation (intension).
Mind maps built on these principles could provide a common thesaurus encompassing the whole of enterprise data, information and knowledge.
Intelligence: Data, Information, Knowledge
Considering that mind maps combine intelligence and cartography, they may have some use for enterprise architects, in particular with regard to economic intelligence, i.e the integration of information processing, from data mining to knowledge management and decision-making:
Data provide the raw input, without clear structures or semantics (terms or aspects).
Categories are used to process data into information on one hand (extensional nodes), design production systems on the other hand (intensional nodes).
Abstractions (concepts) makes knowledge from information by putting it to use.
Conclusion
Along that perspective mind maps could serve as front-ends for enterprise architecture ontologies, offering a layered cartography that could be organized according to concerns:
Enterprise architects would look at physical environments, business processes, and functional and technical systems architectures.
Using layered maps to visualize enterprise architectures
Knowledge managers would take a different perspective and organize the maps according to the nature and source of data, information, and knowledge.intelligence w
Using layered maps to build economic intelligence
As demonstrated by geographic information systems, maps built on clear semantics can be combined to serve a wide range of purposes; furthering the analogy with geolocation assistants, layered mind maps could be annotated with punctuation marks (e.g ?, !, …) in order to support problem-solving and decision-making.
Self-driving vehicles should behave like humans, here is how to teach them so.
Preamble
The eventuality of sharing roads with self-driven vehicles raises critical issues, technical, social, or ethical. Yet, a dual perspective (us against them) may overlook the question of drivers’ communication (and therefore behavior) because:
Contrary to smart cars, human drivers don’t use algorithms.
Contrary to humans, smart cars are by nature unethical.
If roads are to become safer when shared between human and self-driven vehicles, enhancing their collaboration should be a primary concern.
Driving Is A Social Behavior
The safety of roads has more to do with social behaviors than with human driving skills, as it depends on human ability, (a) to comply with clearly defined rules and, (b) to communicate if and when rules fail to deal with urgent and exceptional circumstances. Given that self-driving vehicles will have no difficulty with rules compliance, the challenge is their ability to communicate with other drivers, especially human ones.
What Humans Expect From Other Drivers
Social behavior of human drivers is basically governed by clarity of intent and self-preservation:
Clarity of intent: every driver expects from all protagonists a basic knowledge of the rules, and the intent to follow the relevant ones depending on circumstances.
Self-preservation: every driver implicitly assumes that all protagonists will try to preserve their physical integrity.
As it happens, these assumptions and expectations may be questioned by self-driving cars:
Human drivers wouldn’t expect other drivers to be too smart with their interpretation of the rules.
Machines have no particular compunction with their physical integrity.
Mixing human and self-driven cars may consequently induce misunderstandings that could affect the reliability of communications, and so the safety of the roads.
Why Self-driving Cars Have To Behave Like Human Drivers
As mentioned above, driving is a social behavior whose safety depends on communication. But contrary to symbolic and explicit driving regulations, communication between drivers is implicit by necessity; if and when needed, it is in urgency because rules are falling short of circumstances: communication has to be instant.
So, since there is no time for interpretation or reasoning about rules, or for the assessment of protagonists’ abilities, communication between drivers must be implicit and immediate. That can only be achieved if all drivers behave like human ones.
Turing’s Imitation Game Revisited
Alan Turing designed his Imitation Game as a way to distinguish between human and artificial intelligence. For that purpose a judge was to interact via computer screen and keyboard with two anonymous “agents”, one human and one artificial, and to decide which was what.
Extending the principle to drivers’ behaviors, cars would be put on the roads of a controlled environment, some driven by humans, others self-driven. Behaviors in routine and exceptional circumstances would be recorded and analyzed for drivers and protagonists.
Control environments should also be run, one for human-only drivers, and one with drivers unaware of the presence of self-driving vehicles.
Drivers’ behaviors would then be assessed according to the nature of protagonists:
H / H: Should be the reference model for all driving behaviors.
H / M: Human drivers should make no difference when encountering self-driving vehicles.
M / H: Self-driving vehicles encountering human drivers should behave like good human drivers.
Ma / Mx: Self-driving vehicles encountering self-driving protagonists and recognizing them as such could change their driving behavior providing no human protagonists are involved.
Ma / Ma: Self-driving vehicles encountering self-driving protagonists and recognizing them as family related could activate collaboration mechanisms providing no other protagonists are involved.
Such a scheme could provide the basis of a driving licence equivalent for self-driving vehicles.
Self-driving Vehicles & Self-improving Safety
If self-driving vehicles have to behave like humans and emulate their immediate reactions, they may prove exceptionally good at it because imitation is what machines do best.
When fed with data about human drivers behaviors, deep-learning algorithms can extract implicit knowledge and use it to mimic human behaviors; and with massive enough data inputs, such algorithms can be honed to statistically perfect similitude.
That could set the basis of a feedback loop:
A limited number of self-driving vehicles (properly fed with data) are set to learn from communicating with human drivers.
As self-driving vehicles become better at the imitation game their number can be progressively increased.
Human behaviors improve influenced by the growing number of self-driving vehicles, which adjust their behavior in return.
That is to create a virtuous feedback for roads safety.
PS: A Contrary Evidence
A trial in Texas demonstrates a contrario the potency of the argument by adopting the alternative policy, making clear that self-driving vehicles are indeed machines. Apart for being introduced as a public transport within a defined area and designed stops, two schemes are used to inhibit the imitation game:
Appearance: design and color enable immediate recognition.
Communication: external screens are used for textual (as opposed to visual) notification to pedestrians and other vehicles.
Future will tell if that policy is just a tactical step or a more significant shift towards a functional distinction between artificial brains and humans ones.
Given the digitization of enterprises environments, engineering processes have to be entwined with business ones while kept in sync with enterprise architectures. That calls for new threads of collaboration taking into account the integration of business and engineering processes as well as the extension to business environments.
Collaboration can be personal and direct, or collective and mediated (Wang Qingsong)
Whereas models are meant to support communication, traditional approaches are already straining when used beyond software generation, that is collaboration between humans and CASE tools. Ontologies, which can be seen as a higher form of models, could enable a qualitative leap for systems collaborative engineering at enterprise level.
Systems Engineering: Contexts & Concerns
To begin with contents, collaborations should be defined along three axes:
Requirements: business objectives, enterprise organization, and processes, with regard to systems functionalities.
Feasibility: business requirements with regard to architectures capabilities.
Architectures: supporting functionalities with regard to architecture capabilities.
Engineering Collaborations at Enterprise Level
Since these axes are usually governed by different organizational structures and set along different time-frames, collaborations must be supported by documentation, especially models.
Shared Models
In order to support collaborations across organizational units and time-frames, models have to bring together perspectives which are by nature orthogonal:
Contexts, concerns, and languages: business vs engineering.
Time-frames and life-cycle: business opportunities vs architecture stability.
Harnessing MBSE to EA
That could be achieved if engineering models could be harnessed to enterprise ones for contexts and concerns. That is to be achieved through the integration of processes.
Processes Integration
As already noted, the integration of business and engineering processes is becoming a key success factor.
For that purpose collaborations would have to take into account the different time-frames governing changes in business processes (driven by business value) and engineering ones (governed by assets life-cycles):
Business requirements engineering is synchronic: changes must be kept in line with architectures capabilities (full line).
Software engineering is diachronic: developments can be carried out along their own time-frame (dashed line).
Synchronic (full) vs diachronic (dashed) processes.
Application-driven projects usually focus on users’ value and just-in-time delivery; that can be best achieved with personal collaboration within teams. Architecture-driven projects usually affect assets and non-functional features and therefore collaboration between organizational units.
Collaboration: Direct or Mediated
Collaboration can be achieved directly or through some mediation, the former being a default option for applications, the latter a necessary one for architectures.
Both can be defined according to basic cognitive and organizational mechanisms and supported by a mix of physical and virtual spaces to be dynamically redefined depending on activities, projects, locations, and organisation.
Direct collaborations are carried out between individuals with or without documentation:
Immediate and personal: direct collaboration between 5 to 15 participants with shared objectives and responsibilities. That would correspond to agile project teams (a).
Delayed and personal: direct collaboration across teams with shared knowledge but with different objectives and responsibilities. That would tally with social networks circles (c).
Collaborations
Mediated collaborations are carried out between organizational units through unspecified individual members, hence the need of documentation, models or otherwise:
Direct and Code generation from platform or domain specific models (b).
Model transformation across architecture layers and business domains (d)
Depending on scope and mediation, three basic types of collaboration can be defined for applications, architecture, and business intelligence projects.
Projects & Collaborations
As it happens, collaboration archetypes can be associated with these profiles.
Collaboration Mechanisms
Agile development model (under various guises) is the option of choice whenever shared ownership and continuous delivery are possible. Application projects can so be carried out autonomously, with collaborations circumscribed to team members and relying on the backlog mechanism.
Projects set across enterprise architectures cannot be carried out without taking into account phasing constraints. While ill-fated Waterfall methods have demonstrated the pitfalls of procedural solutions, phasing constraints can be dealt with a roundabout mechanism combining iterative and declarative schemes.
Engineering vs Business Driven Collaborations
With collaborative engineering upgraded at enterprise level, the main challenge is to iron out frictions between application and architecture projects and ensure the continuity, consistency and effectiveness of enterprise activities. That can be achieved with roundabouts used as a collaboration mechanism between projects, whatever their nature:
Shared models are managed at roundabout level.
Phasing dependencies are set in terms of assertions on shared models.
Depending on constraints projects are carried out directly (1,3) or enter roundabouts (2), with exits conditioned by the availability of models.
Engineering driven collaboration: roundabout and backlogs
Moreover, with engineering embedded in business processes, collaborations must also bring together operational analytics, decision-making, and business intelligence. Here again, shared models are to play a critical role:
Enterprise descriptive and prescriptive models for information maps and objectives
Environment predictive models for data and business understanding.
Business driven collaboration: operations and business intelligence
Whereas both engineering and business driven collaborations depend on sharing information and knowledge, the latter have to deal with open and heterogeneous semantics. As a consequence, collaborations must be supported by shared representations and proficient communication languages.
Ontologies & Representations
Ontologies are best understood as models’ backbones, to be fleshed out or detailed according to context and objectives, e.g:
Thesaurus, with a focus on terms and documents.
Systems modeling, with a focus on integration, e.g Zachman Framework.
Classifications, with a focus on range, e.g Dewey Decimal System.
Meta-models, with a focus on model based engineering, e.g models transformation.
Conceptual models, with a focus on understanding, e.g legislation.
Knowledge management, with a focus on reasoning, e.g semantic web.
As such they can provide the pillars supporting the representation of the whole range of enterprise concerns:
Taking a leaf from Zachman’s matrix, ontologies can also be used to differentiate concerns with regard to architecture layers: enterprise, systems, platforms.
Last but not least, ontologies can be profiled with regard to the nature of external contexts, e.g:
Institutional: Regulatory authority, steady, changes subject to established procedures.
Professional: Agreed upon between parties, steady, changes subject to established procedures.
Corporate: Defined by enterprises, changes subject to internal decision-making.
Social: Defined by usage, volatile, continuous and informal changes.
Personal: Customary, defined by named individuals (e.g research paper).
Cross profiles: capabilities, enterprise architectures, and contexts.
Ontologies & Communication
If collaborations have to cover engineering as well as business descriptions, communication channels and interfaces will have to combine the homogeneous and well-defined syntax and semantics of the former with the heterogeneous and ambiguous ones of the latter.
With ontologies represented as RDF (Resource Description Framework) graphs, the first step would be to sort out truth-preserving syntax (applied independently of domains) from domain specific semantics.
RDF graphs (top) support formal (bottom left) and domain specific (bottom right) semantics.
On that basis it would be possible to separate representation syntax from contents semantics, and to design communication channels and interfaces accordingly.
That would greatly facilitate collaborations across externally defined ontologies as well as their mapping to enterprise architecture models.
Conclusion
To summarize, the benefits of ontological frames for collaborative engineering can be articulated around four points:
A clear-cut distinction between representation semantics and truth-preserving syntax.
A common functional architecture for all users interfaces, humans or otherwise.
Modular functionalities for specific semantics on one hand, generic truth-preserving and cognitive operations on the other hand.
Profiled ontologies according to concerns and contexts.
A critical fifth benefit could be added with regard to business intelligence: combined with deep learning capabilities, ontologies would extend the scope of collaboration to explicit as well as implicit knowledge, the former already framed by languages, the latter still open to interpretation and discovery.
P.S.
Knowledge graphs, which have become a key component of knowlege management, are best understood as a reincarnation of ontologies.
An often overlooked benefit of artificial intelligence has been a renewed interest in seminal philosophical and cognitive topics; ontologies coming top of the list.
The Thinker Monkey, Breviary of Mary of Savoy
Yet that interest has often been led astray by misguided perspectives, in particular:
Universality: one-fits-all approaches are pointless if not self-defeating considering that ontologies are meant to target specific domains of concerns.
Implementation: the focus is usually put on representation schemes (commonly known as Resource Description Frameworks, or RDFs), instead of the nature of targeted knowledge and the associated cognitive capabilities.
Those misconceptions, often combined, may explain the limited practical inroads of ontologies. Conversely, they also point to ontologies’ wherewithal for enterprises immersed into boundless and fluctuating knowledge-driven business environments.
Ontologies as Assets
Whatever the name of the matter (data, information or knowledge), there isn’t much argument about its primacy for business competitiveness; insofar as enterprises are concerned knowledge is recognized as a key asset, as valuable if not more than financial ones, and should be managed accordingly. Pushing the comparison still further, data would be likened to liquidity, information to fixed income investment, and knowledge to capital ventures. To summarize, assets whatever their nature lose value when left asleep and bear fruits when kept awake; that’s doubly the case for data and information:
Digitized business flows accelerates data obsolescence and makes it continuous.
Shifting and porous enterprises boundaries and markets segments call for constant updates and adjustments of enterprise information models.
But assessing the business value of knowledge has always been a matter of intuition rather than accounting, even when it can be patented; and most of knowledge shapes up well beyond regulatory reach. Nonetheless, knowledge is not manna from heaven but the outcome of information processing, so assessing the capabilities of such processes could help.
Admittedly, traditional modeling methods are too stringent for that purpose, and looser schemes are needed to accommodate the open range of business contexts and concerns; as already expounded, that’s precisely what ontologies are meant to do, e.g:
Systems modeling, with a focus on integration, e.g Zachman Framework.
Classifications, with a focus on range, e.g Dewey Decimal System.
Conceptual models, with a focus on understanding, e.g legislation.
Knowledge management, with a focus on reasoning, e.g semantic web.
And ontologies can do more than bringing under a single roof the whole of enterprise knowledge representations: they can also be used to nurture and crossbreed symbolic assets and develop innovative ones.
Ontologies Benefits
Knowledge is best understood as information put to use; accounting rules may be disputed but there is no argument about the benefits of a canny combination of information, circumstances, and purpose. Nonetheless, assessing knowledge returns is hampered by the lack of traceability: if a part of knowledge is explicit and subject to symbolic representation, another is implicit and manifests itself only through actual behaviors. At philosophical level it’s the line drawn by Wittgenstein: “The limits of my language mean the limits of my world”; at technical level it’s AI’s two-lanes approach: symbolic rule-based engines vs non symbolic neural networks; at corporate level implicit knowledge is seen as some unaccounted for aspect of intangible assets when not simply blended into corporate culture. With knowledge becoming a primary success factor, a more reasoned approach of its processing is clearly needed.
To begin with, symbolic knowledge can be plied by logic, which, quoting Wittgenstein again, “takes care of itself; all we have to do is to look and see how it does it.” That would be true on two conditions:
Domains are to be well circumscribed.
A water-tight partition must be secured between the logic of representations and the semantics of domains.
That could be achieved with modular and specific ontologies built on a clear distinction between common representation syntax and specific domains semantics.
As for non-symbolic knowledge, its processing has for long been overshadowed by the preeminence of symbolic rule-based schemes, that is until neural networks got the edge and deep learning overturned the playground. In a few years’ time practically unlimited access to raw data and the exponential growth in computing power have opened the door to massive sources of unexplored knowledge which is paradoxically both directly relevant yet devoid of immediate meaning:
Relevance: mined raw data is supposed to reflect the geology and dynamics of targeted markets.
Meaning: the main value of that knowledge rests on its implicit nature; applying existing semantics would add little to existing knowledge.
Assuming that deep learning can transmute raw base metals into knowledge gold, enterprises would need to understand, assess, and improve the refining machinery. That could be done with ontological frames.
A Proof of Concept
Compared to tangible assets knowledge may appear as very elusive, yet, and contrary to intangible ones, knowledge is best understood as the outcome of processes that can be properly designed, assessed, and improved. And that can be achieved with profiled ontologies.
As a Proof of Concept, an ontological kernel has been developed along two principles:
A clear-cut distinction between truth-preserving representation and domain specific semantics.
Profiled ontologies designed according to the nature of contents (concepts, documents, or artifacts), layers (environment, enterprise, systems, platforms), and contexts (institutional, professional, corporate, social.
That provides for a seamless integration of information processing, from data mining to knowledge management and decision making:
Data is first captured through aspects.
Categories are used to process data into information on one hand, design production systems on the other hand.
Concepts serve as bridges to knowledgeable information.
In the footsteps of robots replacing workmen, deep learning bots look to boot out knowledge workers overwhelmed by muddy data.
Cloning Knowledge (Tadeusz Cantor, from “The Dead Class”)
Faced with that perspective, should humans try to learn deeper and faster than clones, or should they learn from octopuses and their smart hands.
Machine Learning & The Economics of Clones
As illustrated by scan-reading AI machines, the spreading of learning AI technology in every nook and cranny introduces something like an exponential multiplier: compared to the power-loom of the Industrial Revolution which substituted machines for workers, deep learning is substituting replicators for machines; and contrary to power looms, there is no physical limitation on the number of smart clones that can be deployed. So, however fast and deep humans can learn, clones are much too prolific: it’s a no-win situation. To get out of that conundrum humans have to put their hand on a competitive edge, e.g some kind of knowledge that cannot be cloned.
Senses (views, sounds, smells, touches) or beliefs (as nurtured by the supposed common “sense”). Artificial sensors can compete with human ones, and smart machines are much better if prejudiced beliefs are put into the equation.
Reasoning, i.e the mental processing of symbolic representations. As demonstrated by AlphaGo, machines are bound to fast extend their competitive edge.
Philosophy which is by essence meant to bring together perceptions, intuitions, and symbolic representations. That’s where human intelligence could beat its artificial cousin which is clueless when purposes are needed.
That assessment is bore out by evolution: the absolute dominance established by humans over other animal species comes from their use of knowledge, which can be summarized as:
Use of symbolic representations.
Ability to formulate and exchange representations of contexts, concerns, and policies.
Ability to agree on stakes and cooperate on policies.
On that basis, the third dimension, i.e the use of symbolic knowledge to cooperate on non-zero-sum endeavors, can be used to draw the demarcation line between human and artificial intelligence:
Paths and paces of pursuits as part and parcel of the knowledge itself. The fact that both are mostly obviated by search engines gives humans some edge.
Operational knowledge is best understood as information put to use, and must include concerns and decision-making. But smart bots’ ubiquity and capabilities often sap information traceability and decisions transparency, which makes room for humans to prevail.
So humans can find a clear competitive edge in this knowledge dimension because it relies on a combination of experience and thinking and is therefore hard to clone. Organizations should make sure that’s where smart systems take back and humans take up.
Organization & Innovation
Innovation being at the root of competitive edge, understanding the role played by smart systems is a key success factor; that is to be defined by organization.
As epitomized by Henry Ford, industrial-era thinking associated innovation with top-down management and the specialization of execution:
At execution level manual tasks were to be fragmented and specialized.
At management level analysis and decision-making were to be centralized and abstracted.
That organizational paradigm puts a double restraint on innovation:
On execution side the fragmentation of manual tasks prevents workers from effectively assessing and improving their performances.
On management side knowledge is kept in conceptual boxes and bereft of feedback from actual uses.
That railing between smart brains and dumb hands may have worked well enough for manufacturing processes limited to material flows and subject to circumscribed and predictable technological changes. It didn’t last.
First, as such hierarchies necessarily grow with processes complexity, overheads and rigidity force repeated pruning. Then, flat hierarchies are of limited use when information flows are to be combined with material ones, so enterprises have to start with matrix organization. Finally, with the seamless integration of digital and material flows, perpetuating the traditional line between management and execution is bound to hamstring innovation:
Smart tools may be able to perform a wide range of physical tasks without human supervision, but the core of innovation core as well as its front lines are where human and machines collaborate in processing a mix of material and information flows, both learning from the experience.
Hierarchies and centralized decision-making are being cut out from feeders when set in networked business environments colonized by smart bots on both sides of corporate boundaries.
Not surprisingly, these innovation trends seem to tally with the social dimension of knowledge.
Learning from the Octopus
The AI revolution has already broken all historical records of footprint (everything is affected) and speed (a matter of years). Given the length of human education cycles, appraising the consequences comes with some urgency, beginning with the disposal of two entrenched beliefs:
Knowledge should not be dealt with as a single and homogeneous corpus: by focusing on collective knowledge and decision-making humans can take the lead on cloned brains, whatever their learning capability.
At individual level the new paradigm could be compared to the nervous system of octopuses: each arm gets its brain and neurons, and so its own touch of knowledge and taste of decision-making.
On a broader (i.e enterprise) perspective, knowledge should be supported by two organizational layers, one direct and innovation-driven between trusted co-workers, the other networked and knowledge-driven between remote workers, trusted or otherwise.
Humans looking for reassurance against the encroachment of artificial brains should try YouTube subtitles: whatever Google’s track record in natural language processing, the way its automated scribe writes down what is said in the movies is essentially useless.
A blank sheet of paper was copied on a Xerox machine. This copy was used to make a second copy. The second to make a third one, and so on… Each copy as it came out of the machine was re-used to make the next. This was continued for one hundred times, producing a book of one hundred pages. (Ian Burn)
Experience directly points to the probable cause of failure: the usefulness of real-time transcriptions is not a linear function of accuracy because every slip can be fatal, without backup or second chance. It’s like walking a line: for all practical purposes a single misunderstanding can throw away the thread of understanding, without a chance of retrieve or reprieve.
Contrary to Turing machines, listeners have no finite states; and contrary to the sequence of symbols on tapes, tales are told by weaving together semantic threads. It ensues that stories are work in progress: readers can pause to review and consolidate meanings, but listeners have no other choice than punting on what comes to they mind, hopping that the fabric of the story will carry them out.
So, whereas automated scribes can deep learn from written texts and recorded conversations, there is no way to do the same from what listeners understand. That’s the beauty of story telling: words may be written but meanings are renewed each time the words are heard.
Tests are meant to ensure that nothing will go amiss. Assuming that expected hazards can be duly dealt with beforehand, the challenge is to guard against unexpected ones.
Unexpected Outcome (Ariel Schlesinger)
That would require the scripting of every possible outcomes in an unlimited range of unknown circumstances, and that’s where Deep Learning may help.
What to Look For
As Donald Rumsfeld once famously said, there are things that we know we don’t know, and things we don’t know we don’t know; hence the need of setting things apart depending on what can be known and how, and build the scripts accordingly:
Business requirements: tests can be designed with respect to explicit specifications; yet some room should also be left for changes in business circumstances.
Functional requirements: assuming business requirements are satisfied, the part played by supporting systems can be comprehensively tested with respect to well-defined boundaries and operations.
Quality of service: assuming business and functional requirements are satisfied, tests will have to check how human interfaces and resources are to cope with users behaviors and expectations which, by nature, cannot be fully anticipated.
Technical requirements: assuming business and functional requirements are satisfied as well as users’ expectations for service, deployment, maintenance, and operations are to be tested with regard to feasibility and costs.
Automated testing has to take into account these differences between scope and nature, from bounded and defined specifications to boundless, fuzzy and changing circumstances.
Automated Software Testing
Automated software testing encompasses two basic components: first the design of test cases (events, operations, and circumstances), then their scripted execution. Leading frameworks already integrate most of the latter together with the parts of the former targeting technical aspects like graphical user interfaces or system APIs. Artificial intelligence (AI) and machine learning (ML) have also been tried for automated test generation, yet with a scope limited by dependency on explicit knowledge, and consequently by the need of some “manual” teaching. That hurdle may be overcame by the deep learning ability to get direct (aka automated) access to implicit knowledge.
Reconnaissance: Known Knowns
Systems are designed artifacts, with the corollary that their components are fully defined and their behavior predictable. The design of technical test cases can therefore be derived from what is known of software and systems architectures, the former for test units, the latter for integration and acceptance tests. Deep learning could then mine recorded log-files in order to identify critical cases’ events and circumstances.
Exploration: Known Unknowns
Assuming that applications must be tested for use during their expected shelf life, some uncertainty has to be factored in for future business circumstances. Yet, assuming applications are designed to meet specific business objectives, such hypothetical circumstances should remain within known boundaries. In that context deep learning could be applied to exploration as well as policies:
Compared to technical test cases that can rely on the content of systems log-files, business and functional ones have to look outside and mine raw data from business environments.
In return, the relevancy of observations can be assessed with regard to business objectives, improved, and feed the policy module in charge of defining test cases.
Blind Errands: Unknown Unknowns
Even with functional and technical capabilities well-tested and secured, quality of service may remain contingent on human quirks: instinctive or erratic behaviors that could thwart the best designed handrails. On one hand, and due to their very nature, such hazards are not to be easily forestalled by reasoned test cases; but on the other hand they don’t take place in a void but within known functional circumstances. Given that porosity of functional and cognitive layers, the validity of functional test cases may be compromised by unfathomable cognitive associations, and that could open the door to unmanageable regression. Enter deep learning and its ability to extract knowledge from insignificance.
Compared to business and functional test cases, hazards are not directly related to business activities. As a consequence, the learning process cannot be guided by business and functional test cases but has to chart unpredictable human behaviors. As it happens, that kind of learning combining random simulation with automated reinforcement is what makes the specificity of deep learning.
From Non-regression to Self-improvement
As a conclusion, if non-regression is to be the cornerstone of quality management, test cases are to be set along clear swim-lanes: business logic (independently of systems), supporting systems functionalities (for shared applications), users interfaces (for non shared interactions). Then, since test cases are also run across swim-lanes, it opens the door to feedback, e.g unit test cases reassessed directly from business rules independently of systems functionalities, or functional test cases reassessed from users’ behaviors.
Considering that well-defined objectives, sound feedback mechanisms, and the availability of massive data from systems logs (internal) and business environment (external) are the main pillars of deep learning technologies, their combination in integrated frameworks could result in a qualitative leap toward self-improving automated test cases.
Preamble
Speaking in tongues (aka Glossolalia) is the fluid vocalizing of speech-like syllables without any recognizable association with a known language. Such experience is best (not ?) understood as the actual speaking of a gutted language with grammatical ghosts inhabited by meaningless signals.
Silent Sounds (Herbert List)
Usually set in religious context or circumstances, speaking in tongue looks like souls having their own private conversations. Yet, contrary to extraterrestrial languages, the phenomenon is not fictional and could therefore point to offbeat clues for natural language technology.
Computers & Language Technology
From its inception computers technology has been a matter of language, from machine code to domain specific. As a corollary, the need to be in speaking terms with machines (dumb or smart) has put a new light on interpreters (parsers in computer parlance) and open new perspectives for linguistic studies. In due return, computers have greatly improved the means to experiment and implement new approaches.
During the recent years advances in artificial intelligence (AI) have brought language technologies to a critical juncture between speech recognition and meaningful conversation, the former leaping ahead with deep learning and signal processing, the latter limping along with the semantics of domain specific languages.
Interestingly, that juncture neatly coincides with the one between the two intrinsic functions of natural languages: communication and representation.
Rules Engines & Neural Network
As exemplified by language technologies, one of the main development of deep learning has been to bring rules engines and neural networks under a common functional roof, turning the former unfathomable schemes into smart conceptual tutors for the latter.
In contrast to their long and successful track record in computer languages, rule-based approaches have fallen short in human conversations. And while these failings have hindered progress in the semantic dimension of natural language technologies, speech recognition have strode ahead on the back of neural networks fed by massive data from social networks and fueled by increasing computing power. But the rift between processing and understanding natural languages is now being fastened through deep learning technologies. And with the leverage of rule engines harnessing neural networks, processing and understanding can be carried out within a single feedback loop.
From Communication to Cognition
From a functional point of view, natural languages can be likened to money, first as medium of exchange, then as unit of account, finally as store of value. Along that understanding natural languages would be used respectively for communication, information processing, and knowledge representation. And like the economics of money, these capabilities are to be associated to phased cognitive developments:
Communication: languages are used to trade transient signals; their processing depends on the temporal persistence of the perceived context and phenomena; associated behaviors are immediate (here-and-now).
Information: languages are also used to map context and phenomena to some mental representations; they can therefore be applied to scripted behaviors and even policies.
Knowledge: languages are used to map contexts, phenomena, and policies to categories and concepts to be stored as symbolic representations fully detached of original circumstances; these surrogates can the be used, assessed, and improved on their own.
As it happens, advances in technologies seem to follow these cognitive distinctions, with the internet of things (IoT) for data communications, neural networks for data mining and information processing, and the addition of rules engines for knowledge representation. Yet paces differ significantly: with regard to language processing (communication and information), deep learning is bringing the achievements of natural language technologies beyond 90% accuracy; but when language understanding has to take knowledge into account, performances still lag a third below: for computers knowledge to be properly scaled, it has to be confined within the semantics of specific domains.
Sound vs Speech
Humans listening to the Universe are confronted to a question that can be unfolded in two ways:
Is there someone speaking, and if it’s the case, what’s the language ?.
Is that a speech, and if it’s the case, who’s speaking ?.
In both case intentionality is at the nexus, but whereas the first approach has to tackle some existential questioning upfront, the second can put philosophy on the back-burner and focus on technological issues. Nonetheless, even the language first approach has been challenging, as illustrated by the difference in achievements between processing and understanding language technologies.
Recognizing a language has long been the job of parsers looking for the corresponding syntax structures, the hitch being that a parser has to know beforehand what it’s looking for. Parser’s parsers using meta-languages have been effective with programming languages but are quite useless with natural ones without some universal grammar rules to sort out babel’s conversations. But the “burden of proof” can now be reversed: compared to rules engines, neural networks with deep learning capabilities don’t have to start with any knowledge. As illustrated byGoogle’s Multilingual Neural Machine Translation System,such systems can now build multilingual proficiency from sufficiently large samples of conversations without prior specific grammatical knowledge.
To conclude, “Translation System” may even be self-effacing as it implies language-to-language mappings when in principle such systems can be fed with raw sounds and be able to parse the wheat of meanings from the chaff of noise. And, who knows, eventually be able to decrypt languages of tongues.
Sometimes the future is best seen through rear-view mirrors; given the advances of artificial intelligence (AI) in 2016, hindsight may help for the year to come.
Deep Mind Learning (J.Bosh)
Deep Learning & the Depths of Intelligence
Deep learning may not have been discovered in 2016 but Google’s AlphaGo has arguably brought a new dimension to artificial intelligence, something to be compared to unearthing the spherical Earth.
As should be expected for machines capabilities, artificial intelligence has for long been fettered by technological handcuffs; so much so that expert systems were initially confined to a flat earth of knowledge to be explored through cumbersome sets of explicit rules. But exponential increase in computing power has allowed neural networks to take a bottom-up perspective, mining for implicit knowledge hidden in large amount of raw data.
Like digging tunnels from both extremities, it took some time to bring together top-down and bottom-up schemes, namely explicit (rule-based) and implicit (neural network-based) knowledge processing. But now that it comes to fruition, the alignment of perspectives puts a new light on the cognitive and social dimensions of intelligence.
Intelligence as a Cognitive Capability
Assuming that intelligence is best defined as the ability to solve problems, the first criterion to consider is the type of input (aka knowledge) to be used:
Explicit: rational processing of symbolic representations of contexts, concerns, objectives, and policies.
Implicit: intuitive processing of factual (non symbolic) observations of objects and phenomena.
That distinction is broadly consistent with the one between humans, seen as the sole symbolic species with the ability to reason about explicit knowledge, and other animal species which, despite being limited to the processing of implicit knowledge, may be far better at it than humans. Along that understanding, it would be safe to assume that systems with enough computing power will sooner or later be able to better the best of animal species, in particular in the case of imperfect inputs.
Intelligence as a Social Capability
Alongside the type of inputs, the second criterion to be considered is obviously the type of output (aka solution). And since classifications are meant to be built on purpose, a typology of AI outcomes should focus on relationships between agents, humans or otherwise:
Self-contained: problem-solving situations without opponent.
Competitive: zero-sum conflictual activities involving one or more intelligent opponents.
Collaborative: non-zero-sum activities involving one or more intelligent agents.
That classification coincides with two basic divides regarding communication and social behaviors:
To begin with, human behavior is critically different when interacting with living species (humans or animals) and machines (dumb or smart). In that case the primary factor governing intelligence is the presence, real or supposed, of beings with intentions.
Then, and only then, communication may take different forms depending on languages. In that case the primary factor governing intelligence is the ability to share symbolic representations.
A taxonomy of intelligence with regard to cognitive (reason vs intuition) and social (symbolic vs non-symbolic) capabilities may help to clarify the role of AI and the importance of deep learning.
Between Intuition and Reason
Google’s AlphaGo astonishing performances have been rightly explained by a qualitative breakthrough in learning capabilities, itself enabled by the two quantitative factors of big data and computing power. But beyond that success, DeepMind (AlphaGo’s maker) may have pioneered a new approach to intelligence by harnessing both symbolic and non symbolic knowledge to the benefit of a renewed rationality.
Perhaps surprisingly, intelligence (a capability) and reason (a tool) may turn into uneasy bedfellows when the former is meant to include intuition while the latter is identified with logic. As it happens, merging intuitive and reasoned knowledge can be seen as the nexus of AlphaGo decisive breakthrough, as it replaces abrasive interfaces with smart full-duplex neural networks.
Intelligent devices can now process knowledge seamlessly back and forth, left and right: borne by DeepMind’s smooth cognitive cogwheels, learning from factual observations can suggest or reinforce the symbolic representation of emerging structures and behaviors, and in return symbolic representations can be used to guide big data mining.
From consumers behaviors to social networks to business marketing to supporting systems, the benefits of bridging the gap between observed phenomena and explicit causalities appear to be boundless.





































{kind=link}