Preamble
The way tests are designed and executed is being doubly affected by development methods and AI technologies. On one hand well-founded approaches (e.g test-driven development) are often confined to faith-based niches; on the other hand automated schemes and agile methods push many testers out of their comfort zone.

Resetting the issue within a knowledge-based enterprise architecture would pave the way for sound methods and could open new doors for their users.
outline
Tests can be understood in terms of preventive and predictive purposes, the former with regard to actual products, the latter with regard to their forthcoming employ. On that account policies are to distinguish between:
- Test plans, to be derived from requirements.
- Test cases, to be collected from environments.
- Test execution, to be run and monitored in simulated environments.
The objective is to cross these pursuits with knowledge architecture layers.
Test plans are derived from business requirements, either on their own at process level (e.g as users stories or activities), or combined with functional requirements at application level (e.g as use cases). Both plans describe sequences of actions meant to be performed by organizational entities identified at enterprise level. Circumstances are then specified with regard to quality of service and technical requirements.

Test cases’ backbones are built from business scenarii fleshed out with instances mimicking identified entities from business environment, and hypothetical decisions taken by entitled users. The generation of actual instances and decisions could be automated depending on the thoroughness and consistency of business requirements.
To be actually tested, business scenarii have to be embedded into functional ones, yet the distinction must be maintained between what pertains to business logic and what pertains to the part played by supporting systems.
By contrast, despite being built from functional scenarii, integration and acceptance ones are meant to be blind to business or functional contents, and cases can therefore be generated independently.
Unit and components tests are the building blocks of all test cases, the former rooted in business requirements, the latter in functional ones. As such they can be used to a built-in integration of tests and development.
TDD in the loop
Whatever its merits for phased projects, the development V-model suffers from a structural bias because flaws rooted in requirements, arguably the most damaging, tend to be diagnosed after designs are encoded. Test driven development (TDD) takes a somewhat opposite approach as code specifications are governed by testability. But reversing priorities may also introduce reverse issues: where the V-model’s verification and validation come too late and too wide, TDD’s may come hasty and blinkered, with local issues masking global ones. Applying the OODA (Observation, Orientation, Decision, Action) loop to test cases offers a way out of the dilemma:
- Observation (West): test and assessment for component, integration, and acceptance test cases.
- Orientation (North): assessment in the broader context of requirements space (business, functional, Quality of Service), or in the local context of application (East).
- Decision (East): confirm or adjust the development paths with regard to functional scenarii, development backlog, or integration constraints.
- Action (South): develop code at unit, component, or process levels.

As each station is meant to deal with business, functional, and operational test cases, the challenge is to ensure a seamless integration and reuse across iterations and layers.
managing Tests cases
Whatever the method, tests plans are meant to mirror requirements scope and structure. For architecture oriented projects, tests should be directly aligned with the targeted capabilities of architecture layers:

For business driven projects, test plans should be set along business scenarii, with development units and associated test cases defined with regard to activities. When use cases, which cover the subset of activities supported by systems, are introduced upfront for both business and functional requirements, test plans should keep the distinction between business and functional requirements.

All things considered, test cases are to be comprehensively and consistently run against requirements distinct in goals (business vs architecture), layers (business, functions, platforms), or formalism (text, stories, use cases, …).
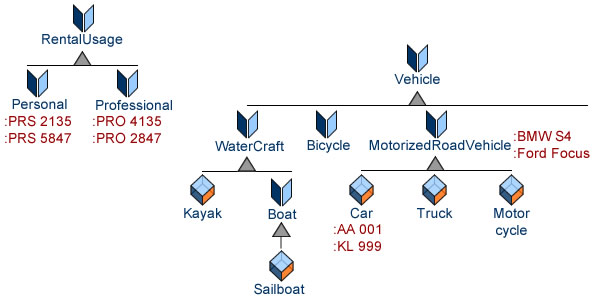
In contrast, test cases are by nature homogeneous as made of instances of objects, events, and behaviors; ontologies can therefore be used to define and manage these instances directly from models. The example below make use of instances for types (propulsion, body), car model (Renault Clio), and car (58642).

Ontologies can then be used to manage test cases as instances of activities (development tests) or processes (integration and acceptance tests):

The primary and direct benefit of representing test cases as instances in ontologies is to ensures a seamless integration and reuse of development, integration, and acceptance test cases independently of requirements context.
But the ontological approach have broader and deeper consequences: by defining test cases as instances in line with environment data, it opens the door to their enrichment through deep-learning.
knowledgeable test cases
Names may vary but tests are meant to serve a two-facet objective: on one hand to verify the intrinsic qualities of artefacts as they are, independently of context and usage; on the other hand to validate their features with regard to extrinsic circumstances, present or in a foreseeable future.
That duality has logical implications for test cases:
- The verification of intrinsic properties can be circumscribed and therefore by carried out based on available information, e.g: design, programing language syntax and semantics, systems configurations, etc.
- The validation of functional features and behaviors is by nature open-ended with regard to scope and time-frame; it ensues that test cases have to rely on incomplete or uncertain information.
Without practical applications that distinction has been of little consequence, until now: while the digital transformation removes the barriers between test cases and environment data, the spreading of machine learning technologies multiplies the possibilities of exchanges.
Along the traditional approach, test cases relies on three basic sources of information:
- Syntax and semantics of programing languages are used to check software components (a)
- Logical and functional models (including patterns) are used to check applications designs (b).
- Requirements are used to check applications compliance (c).
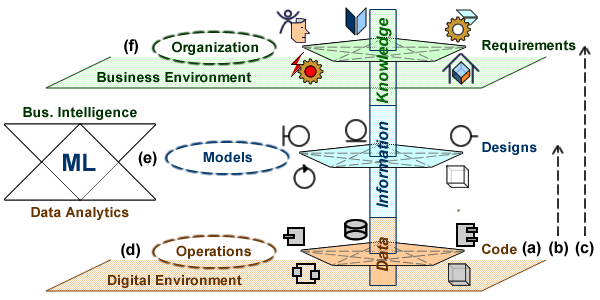
With barriers removed, test cases as instances can be directly aligned with environment data, opening doors to their enrichment, e.g:
- Random data samples can be mined from environments and used to deal with human instinctive or erratic behaviors. By nature knee jerks or latent behavior cannot be checked with reasoned test cases, yet they neither occur in a void but within known operational of functional or circumstances; data analytics can be used to identify these quirks (d).
- Systems being designed artifacts, components are meant to tally with models for structures as well as behaviors. Crossing operational data with design models will help to refine and hone integration and acceptance test cases (e).
- Whereas integration tests put the focus on models and code, acceptance tests also involve the mapping of models to business and organizational concepts. As a corollary, test cases are to rely on a broader range of knowledge: external regulations, mined from environments, or embedded in organization through individual and collective skills (f).
Given the immersion of enterprises in digital environments, and assuming representing test cases as ontological instances, these are already practical opportunities. But the real benefits of knowledge based test cases are to come from leveraging machine learning technologies across enterprise and knowledge architectures.