“Since words are only names for things, it would be more convenient for all men to carry about them such things as were necessary to express a particular business they are to discourse on.”
Jonathan Swift, Gulliver’s Travels
Objective
Modeling languages are meant to support the description of contexts and concerns from specific standpoints. And because those different perspectives have to be mapped against shared references, language must also provide constructs for ironing out variants and factoring out constants.
Ironing out differences in features and behaviors (Erwitt Elliott)
Yet, while most languages generally agree on basic definitions of objects and behaviors, many distinctions are ignored or subject to controversial understanding; such shortcomings might be critical when architecture capabilities are concerned:
Actual entities and their symbolic counterpart.
Actual entities and their roles.
Business logic and business operations
External events and system time.
Architecture Capabilities
As those distinctions set the backbone of functional architectures, languages should be assessed according their ability to express them unambiguously using the least possible set of constructs.
Business objects vs Symbolic Surrogates
As far as symbolic systems are concerned, the primary purpose of models is to distinguish between targets and representations. Hence the first assessment yardstick: modeling languages must support a clear and unambiguous distinction between objects and behaviors of concern on one hand, symbolic system surrogates on the other hand.
A primer on representation: objects of concerns and surrogates
Yet, if objects and behaviors are to be consistently and continuously managed, modeling languages must also provide common constructs mapping identities and structures of actual entities to their symbolic counterpart.
Agents vs Roles
Given that systems are built to support business processes, modeling languages should enable a clear distinction between physical entities able to interact with systems on one hand, roles as defined by enterprise organization on the other hand.
Agents and Roles
In that case the mapping of actual entities to systems representations is not about identities but functionalities: a level of indirection has to be introduced between enterprise organization and system technology because the same roles can be played,simultaneously or successively, by people, devices, or other systems.
Business logic vs Business operations
Just like actual objects are not to be confused with their symbolic description, modeling languages must make a clear distinction between business logic and processes execution, the former defining how to process symbolic objects and flows, the latter with the coupling between process execution and changes in actual contexts. That distinction is of a particular importance if business and organizational decisions are to be made independently of supporting systems technology.
Business logic and operational contingencies
Language constructs must also support the consolidation of functional and operational units, the former being defined by integrity constraints on symbolic flows and roles authorizations on objects and operations, the latter taking into account synchronization constraints between the state of actual contexts and the state of their system symbolic counterpart. And for that purpose languages must support the distinction between external and internal events.
External vs Internal Events
Paraphrasing Albert Einstein, time is what happens between events. As a corollary, external time is what happens between context events, and internal time is what happens between system ones. While both can coincide for single systems and locations, no such assumption should be made for distributed systems set in different locations. In that case modeling language should support a clear distinction between external events signalling changes set in actual locations, and internal events signalling changes affecting system surrogates.
Time scales are set by events and concerns
Along that perspective synchronization is to be achieved through the consolidation of time scales. For single locations that can be done using system clocks, across distributed locations the consolidation will entail dedicated time frames and mechanisms set in reference to some initial external event.
Conclusion: How to share differences across perspectives
Somewhat paradoxically, multiple modeling languages erase differences by paring down shared descriptions to some uniform lump that can be understood by all. Conversely, agreeing on a set of distinctions that should be supported by every language could provide an antidote to the Babel syndrome.
That approach can be especially effective for the alignment of enterprise and systems architectures as the four distinctions listed above are equally meaningful in both perspectives.
Even when code is directly developed from requirements, software engineering can be seen as a process of transformation from a source model (e.g requirements) to a target one (e.g program). More generally, there will be intermediate artifacts with development combining automated operations with tasks involving some decision-making. Given the importance of knowledge management in decision-making, it should also be considered as a primary factor for model transformation.
What has been transformed, added, abstracted ? (Velazquez-Picasso)
Clearing Taxonomy Thickets
Beside purpose, models transformation is often considered with regard to automation or abstraction level.
Classifying transformations with regard to automation is at best redundant, inconsistent and confusing otherwise: on one side of the argument, assuming a “manual transformation” entails some “intelligent design”, it ensues that it cannot be automated; but, on the other side of the argument, if manual operations can be automated, the distinction between manual and automated is pointless. And in any case a critical aspect has been ignored, namely what is the added value of a transformation.
Classifying transformations with regard to abstraction levels is also problematic because, as famously illustrated above, there are too many understandings of what those levels may be. Considering for instance analysis and design models; they are usually meant to deal respectively with system functionalities and implementation. But it doesn’t ensue that the former is more abstract than the latter because system functionalities may describe low-level physical devices and system designs may include high level abstract constructs.
A Taxonomy of Purposes
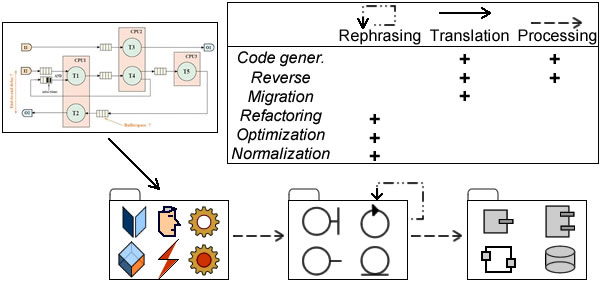
Depending on purpose, model transformation can be set in three main categories:
Translation: source and target models describe the same contents with different languages.
Rephrasing: improvement of the initial descriptions using the same language.
Processing: source and target models describe successive steps along the development process. While they may be expressed with different languages, the objective is to transform model contents.
Translation, Rephrasing, Processing.
Should those different purposes be achieved using common mechanisms, or should they be supported by specific ones ?
A Taxonomy of Knowledge
As already noted, automated transformation is taken as a working assumption and the whole process is meant to be governed by rules. And if purpose is used as primary determinant, those rules should be classified with regard of the knowledge to be considered:
Syntactic knowledge would be needed to rephrase words and constructs without any change in content or language.
Thesaurus and semantics would be employed to translate contents into another language.
Stereotypes, Patterns, and engineering practices would be used to process source models into target ones.
Knowledge with regard to transformation purposes
On that basis, the next step is to consider the functional architecture of transformation, in particular with regard to supporting knowledge.
Procedural vs Declarative KM
Assuming transformation processes devoid of any decision-making, all relevant knowledge can be documented either directly in rules (procedural approach) or indirectly in models (declarative approach).
To begin with, all approaches have to manage knowledge about languages principles (ML) and the modeling languages used for source (MLsrc) and target (MLtrg) models. Depending on language, linguistic knowledge can combine syntactic and semantic layers, or distinguish between them.
Meta-models can be structured along linguistic layers or combine syntax and semantics.
Given exponential growth of complexity, procedural approaches are better suited for the processing of unstructured knowledge, while declarative ones are the option of choice when knowledge is organized along layers.
When applied to model transformation, procedural solutions use tables (MLT) to document the mappings between language constructs, and programs to define and combine transformation rules. Such approaches work well enough for detailed rules targeting specific domains, but fall short when some kind of generalization is needed; moreover, in the absence of distinction at language level (see UML and users’ concerns), any contents differentiation in source models (Msrc) will be blurred in target ones (Mtrg) .
Transformation Policies: Procedural vs Declarative
And filtering out noise appears to be the main challenge of model processing, especially when even localized taints or ambiguities in source models may contaminate the whole of target ones; hence the benefit of setting apart layers of source models according their nature and reliability.
That can be achieved with the modularity of declarative solutions, with transformations carried out separately according the nature of knowledge: syntactic, semantic, or engineering. While declarative solutions also rely on rules, those rules can be managed according to:
Purpose: rephrasing, translation, or development.
Knowledge level: rules about facts, categories, or reasoning.
Robustness: how to deal with incomplete, noisy, or inconsistent models.
Modularity, reusability: how to customize, combine, or generalize transformations.
In principle declarative approaches are generally seen as superior to procedural ones due to the benefits of a clear-cut separation between the different domains of knowledge on one hand, and the programs performing the transformations on the other hand:
The complexity of transformations increases exponentially with the number of rules, independently of the corpus of knowledge.
The ensuing spaghetti syndrome rapidly downgrades transparency, traceability, and reliability of rules which, in procedural approaches, are the only gate to knowledge itself.
Adding specific rules in order to deal with incomplete or inconsistent models significantly degrades modularity and reusability, with the leveraging impact of new rules having to be added for every variant.
In practice the flaws of procedural approaches can be partially curbed providing that:
Rules apply to a closely controlled domain.
Models are built with complete, unambiguous and consistent languages.
Both conditions can be met with domain specific languages (DSLs) and document based ones (e.g XML) targeting design and program models within well-defined business domains.
Compared with the diversity and specificity of procedural solutions, the extent of declarative ones have been checked by their more theoretically demanding requirements, principally met by relational models. Yet, the Model Driven Architecture (MDA) distinction between computation independent (CIMs), platform independent (PIMs), and platform specific (PSMs) models could provide the basis for a generalization of knowledge-based model transformation.
The past is not dead. In fact, it’s not even past. –
William Faulkner
Objective
Retrieving legacy code has something to do with archaeology as both try to retrieve undocumented artifacts and understand their initial context and purpose. The fact that legacy code is still well alive and kicking may help to chart their structures and behaviors, but it may also confuse the rationale of initial designs.
Legacy Artifact: Was the bowl intended for turkeys ? at thanksgiving ? Why the worm ?
Hence the importance of traceability and the benefits of a knowledge based approach to modernization organized along architecture layers (enterprise, systems, platforms), and processes (business, engineering, supporting services).
Model Driven Modernization
Assuming that legacy artifacts under consideration are still operational (otherwise re-engineering would be pointless), modernization will have to:
Pinpoint the deployed components under consideration (a).
Identify the application context of their execution (b).
Chart their footprint in business processes (c).
Define the operational objectives of their modernization (d).
Sketch the conditions of their (re)engineering (e) and the possible integration in the existing functional architecture (f).
Plan the re-engineering project (g).
Modernization Road Map
Those objectives will usually not be achieved in a big bang, wholly and instantly, but progressively by combining increments from all perspectives. Since the different outcomes will have to be managed across organizational units along multiple engineering processes, modernization would clearly benefit from a model based approach, as illustrated by MDA modeling layers:
Platform specific models (PSMs) should be used for collecting legacy artifacts and mapping them to their re-engineered counterparts.
Since platform independent models (PIMs) are meant to describe system functionalities independently of implementations, they should be used to consolidate the functionalities of legacy and re-engineered artifacts.
Since computation independent models (CIMs) are meant to describe business processes independently of supporting systems, they should be used to reinstate, document, and validate re-engineered artifacts within their business context.
Model Driven Modernization
Corresponding phases can be expressed using the archaeology metaphor: field survey and collection (>PSMs), analysis (PSMs/PIMs), and reconstruction (CIMs/PIMs).
Field Survey
The objective of a field survey is to circumscribe the footprint of the modernization and collect artifacts under consideration:
Given targeted business objects or activities, the first step is to collect information about locations, distribution and execution dependencies.
Sites can then be searched and executable files translated into source ones whose structure and dependencies can be documented.
The role of legacy software can then be defined with regard to the application landscape .
Analysis (with regard to presentation, control, persistency, and services)
It must be noted that field survey and collection deal with the identification and restoration of legacy objects without analyzing their contents.
Analysis
The aim of analysis is to characterize legacy components, first with regard to their architectural features, then with regard to functionalities. Basic architectural features take into account components’ sharing and life-cycle.
The analysis of functionalities can be achieved locally or at architecture level:
Local analysis (a) directly map re-factored applications to specific business requirements, by-passing functional architecture. That’s the case when targeted applications can be isolated, e.g by wrapping legacy code.
Global analysis (b) consolidate newly supported applications with existing ones within functional architecture, possibly with new functionalities.
Analysis (with regard to presentation, control, persistency, and services)
It must be noted that the analysis of legacy components, even when carried out at functional architecture level, takes business processes as they are.
Reconstruction
The aim of reconstruction is to set legacy refactoring within the context of enterprise architecture. That should be done from operational and business perspectives:
As the primary rationale of modernization is to deal with operational problems or bottlenecks, its benefits should be fully capitalized at enterprise level.
Re-factored applications usually make room for improvements of users’ experience; that may bring about further changes in organization and business processes.
Reconstruction
Hence, modernization is not complete until potential benefits of re-factored applications are considered, for business processes as well as for functional architecture.
From Workshops to Workflow
As noted above, modernization can seldom be achieved in a big bang and should be planned as a model based engineering process. Taking a leaf from the MDA book, such a process would be organized across four workshops:
Technical architecture (deployment models): that’s where legacy components are collected, sorted, and documented.
Software architecture (platform specific models): where legacy components are put in local context.
Functional architecture (platform independent models): where legacy components are put in shared context.
Enterprise architecture (computation independent models): where legacy components are put into organizational context.
Modernization & MBSE Workshops
Those workshops would be used to manage the outcomes of the modernization workflow:
Collect and organize legacy code; translate into source files.
Document legacy components.
Build PSMs according basic architecture functional patterns.
As long as information was just data files and systems just computers, the respective roles of enterprise and IT architectures could be overlooked; but that has become a hazardous neglect with distributed systems pervading every corner of enterprises, monitoring every motion, and sending axons and dendrites all around to colonize environments.
Enterprise Governance and Separation of Concerns (R.Magritte)
Yet, the overlapping of enterprise and systems footprints doesn’t mean they should be merged, as a matter of fact, that’s the opposite. When the divide between business and technology concerns was clearly set, casual governance was of no consequence; now that turfs are more and more entwined, dedicated policies are required lest decisions be blurred and entropy escalates as a consequence. The need of better focus is best illustrated by the sundry meanings given to “system”, from computers running software to enterprises running businesses, and even school of thought.
Concerns in Perspectives
As far as enterprises are concerned, systems combine human beings, devices, and software components.
From a functional perspective, their capabilities are best defined by their interactions with their environment as well as between their constituents:
Users are supposed to be actual agents granted with organizational status and responsibilities, and possessing symbolic communication capabilities.
Software components and actual devices cannot be granted with organizational status or responsibilities; the former come with symbolic communication capabilities, the latter without.
Assuming that interactions are governed by information, the objective is to understand the contribution of each type of component with regard to information processing and decision-making.
System = Agents + Devices + Symbolic representations
From an engineering perspective, the building of systems is all too often reduced to the development of their software constituents. As a consequence, the complexity of the forest is masked by the singularity of the trees:
The business value of applications is assessed locally instead of being driven by enterprise objectives and organizational constructs.
System models are confused with the programs used to produce software components.
Requirements life cycle, governed by the time-span of business contexts and objectives, is confused with the cycles of reuse of architecture assets.
Since engineering agenda are supposed to support business objectives, their decision-making processes must be aligned yet managed independently. That reasoning also applies to services management whose role is to adjust resources and software releases to operational needs.
Enterprise architectures can then be described as a cross between architecture assets (business objects, organization, technical architecture) on one hand, core processes for business, engineering and services management on the other hand.
EA Artifacts at crossroads between Architectures and Activities
Information is to provide the glue between architecture assets and supported processes.
Information and Architectures Levels
As understood by Cybernetics (see Stafford Beer, “Diagnosing the System for Organizations“), enterprises are viable systems whose success depends on their capacity to countermand entropy, i.e the progressive downgrading of the information used to govern interactions between systems and their environment. And that put knowledge management at the core of systems capabilities.
Knowledge is best defined as information put to use, with information obtained by adding references and sense to data. That blueprint is supposed to be repeated at all architecture levels:
At enterprise level facts pertaining to the conduct of business are captured from environments before being organized into information meant to support enterprise governance.
System level deals with symbolic descriptions of functionalities (information). At this level data is irrelevant, the objective being the consolidation and reuse of shared representations and patterns (knowledge).
The technical level is in charge of operational governance: software components, platforms capabilities, technical resources, communication mechanisms, etc. On one hand contexts are to be monitored and data translated into information; one the other hand operational decisions have to be made (knowledge) and executed which means information translated into data.
Architecture Layers and Processing Capabilities
If architecture levels can be characterized by processing capabilities, their engineering must be aligned to the corresponding objectives and time frames.
System Engineering and Separation of Concerns
As demonstrated time and again by blame games around projects failures, enterprise and technical concerns are poor engineering bedfellows, and with good reasons: different contexts, concerns, skills, and time scales. Faced with the challenge of bringing enterprise and development perspectives under a single governance, engineering approaches generally follow one of two basic options:
Phased projects (P) give precedence to software development, with requirements supposed to be set at inception and acceptance performed at completion.
Agile projects (A) give precedence to business requirements, with development iterations combining specifications, programming, and acceptance.
Phased (P) and Agile (A) development models
While each approach has its merits, agile for complex but well circumscribed projects, phased for large projects with external organizational dependencies, the difficulties each may encounter point to the crux of the matter, namely the separation of concerns between business goals and information technology, bypassed by agile approaches and misplaced by phased ones:
Agile development models are driven by users’ value and based on the implicit assumption that business and technology concerns can be dealt with continuously and simultaneously. That may be difficult when external dependencies cannot be avoided and shared ownership cannot be guaranteed.
Phased development models take a mirror position by assuming that business concerns can be settled upfront, which is clearly a very hazardous policy.
Those pitfalls may be overcome if engineering processes take into account the distinction between knowledge management on one hand, software development on the other hand.
Knowledge management (KM) encompasses all information pertaining to the conduct of business: environment, markets, objectives, organization, and projects. With regard to engineering projects, its role is to define and consolidate the descriptions of symbolic representations to be supported by information systems.
Software development (SD) starts with symbolic descriptions and proceeds with the definition, building and acceptance of the corresponding software artifacts.
Service management (SM) provides the bridge between engineering and operational processes.
Capture of information from data and legacy code can also be achieved respectively by data mining and reverse engineering.
System Engineering = Knowledge (KM) + Software (SD) + Service (SM)
Depending on organizational or technical dependencies, knowledge management and software development will be carried out within integrated development cycles (agile processes), or will have to be phased in order to consolidate the different concerns.
That engineering distinction neatly coincides with the functional divide of architectures: knowledge management supporting enterprise architecture, software development supporting system architecture.
Architectures and Engineering Processes
Business processes are governed by collective representations mixing goals, models and rules, not necessarily formally defined, and subject to change with opportunities. Engineering processes for their part have to be materialized through work units, models, and products, all of them explicitly defined, with limited room for change, and set along constraining schedules. Given that systems’ fate hangs on the hing between business and engineering concerns, the corresponding perspectives must be properly aligned.
That can be achieved if workshops are associated with architecture levels, and work units defined according model layers and development flows:
Knowledge management takes charge of symbolic descriptions pertaining to enterprise concerns. Its objective is to map business and operational requirements with the functionalities of supporting systems. Expressed in MDA parlance, the former would be described by computation independent models (CIMs), the latter by platform independent models (PIMs).
Software development deals with software artifacts. That encompasses the consolidation of symbolic descriptions into functional architectures, the design of software components according to platforms specificity (PSMs), and the production of code according to deployment targets (DPMs).
IT Service Management is the counterpart of knowledge management for actual operations and resources. Its objective is to synchronize business and development time-frames and align operational requirements with releases and resources.
Knowledge Management (KM), Software Development (SD), Services Management (SM)
That congruence between architecture divides (enterprise, systems, technology), models layers (CIMs, PIMs, PSMs, DPMs), and engineering concerns (facts or legacy, information, knowledge), provides a reasoned and comprehensive framework for enterprise architectures.
Architecture Capabilities & Separation of Concerns
Architectures describe stocks of shared assets, processes describe flows of changes. Given a hierarchized description of architectures, the objective is to ensure the traceability of concerns and decisions across levels and processes.
Who: enterprise roles, system users, platform entry points.
What: business objects, symbolic representations, objects implementation.
How: business logic, system applications, software components.
When: processes synchronization, communication architecture, communication mechanisms.
Where: business sites, systems locations, platform resources.
The rationale of objectives and decisions (the “Why” of Zachman framework) is expressed by dependency links according to the nature of primary factors:
Deontic dependencies are set by external factors, e.g regulatory context, communication technologies, or legacy systems.
Alethic (aka modal) dependencies are set by internal policies, based on the assessment of options regarding objectives as well as solutions.
Architecture Capabilities and Processes, with deontic (basic) and alethic (dashed) dependencies.
This distinction between dependencies is critical for decision-making and consequently for enterprise governance. Set within time-frames and decorated with time related features, those dependencies can then be consolidated into differentiated strategies for business, engineering and operational processes.
Given that dependencies are usually interwoven, governance must be aligned with the footprints of associated decisions:
Assets: shared decisions affecting different business processes (organization), applications (services), or platforms (purchased software packages).
Users’ Value: streamlined decisions governed by well identified business units providing for straight dependencies from enterprise (business requirements), to systems (functional requirements) and platforms (users’ entry points).
Non functional: shared decisions about scale and performances affecting users’ experience (organization), engineering (technical requirements), or resources (operational requirements).
Separation of Concerns and Requirements Taxonomy
That classification can be used to choose a development model:
Agile approaches should be the option of choice for requirements neatly anchored to users’ value.
Phased approaches should be preferred for projects targeting shared assets across architecture levels. When shared assets are within the same level epic-like variants of agile may also be considered.
Architectures, Processes, and Governance
While there is some consensus about the scope and concerns of Enterprise Architecture as a discipline, some debate remains about the relationship between enterprise and IT governance.
Beyond turf quarrels, arguments are essentially rooted in the distinction between information and supporting systems or, more generally, between organization and IT.
To some extent, those arguments can be ironed out if governance were set with regard to scope, actual or symbolic:
Actual scope deals with current or planned business objects, assets, and processes.
Symbolic scope deals with the design of the corresponding software components.
What is to be governed: actual and symbolic scopes
That distinction matches the divide between enterprise and systems architectures: one set of models deals with enterprise objectives, assets, and organization, the other one deals with system components.
With regard to processes, governance should distinguish between business and engineering:
Business processes are clearly designed at enterprise level, both for their organization and the symbolic description of system representations.
Software engineering ones are under the responsibility of IT governance, from system and software architecture to release and deployment.
Process and architecture perspectives for Governance
While governance could be shared, there is no reason to assume immediate and continuous alignment of perspectives; that could only be achieved through architecture perspective:
Actual architectures encompass business organization (locations, agents, devices) and systems deployments.
Symbolic architectures include systems functionalities and software development.
And, as a mirror achievement, processes take charge of transitions between actual and symbolic architectures:
Processes carry out Architectures alignment (Pb,Pe), Architectures support Processes consistency (As, Ap).
Symbolic architectures provide the mediation between business requirements and software development (As).
Physical architectures do the same between software development and services management (Ap).
Business processes take responsibility for the mapping of enterprise architecture into symbolic representations (Pb).
Engineering processes do the same for the alignment of software and deployment architectures (Pe).
Enterprise and IT governance can then be defined in terms of Knowledge management, with engineering and business processes gathering data from their respective realms, sharing the information through architectures, and putting it to use according their respective concerns.
As illustrated by he Symbolic Systems Program (SSP) at Stanford University, advances in computing and communication technologies bring information and knowledge systems under a single functional roof, namely the processing of symbolic representations.
Information and Knowledge: Acquisition, Use and Reuse (R. Doisneau)
Within that understanding one will expect Knowledge Management to shadow systems architectures and concerns: business contexts and objectives, enterprise organization and operations, systems functionalities and technologies. On the other hand, knowledge being by nature a shared resource of reusable assets, its organization should support the needs of its different users independently of the origin and nature of information. Knowledge Management should therefore bind knowledge of architectures with architecture of knowledge.
Knowledge Representation
In their pivotal article Davis, Shrobe, and Szolovits set five principles for knowledge representation:
Surrogate: KR provides a symbolic counterpart of actual objects, events and relationships.
Ontological commitments: a KR is a set of statements about the categories of things that may exist in the domain under consideration.
Fragmentary theory of intelligent reasoning: a KR is a model of what the things can do or can be done with.
Medium for efficient computation: making knowledge understandable by computers is a necessary step for any learning curve.
Medium for human expression: one the KR prerequisite is to improve the communication between specific domain experts on one hand, generic knowledge managers on the other hand.
Surrogates without Ontological Commitment
That puts information systems as a special case of knowledge ones, as they fulfill the five principles, yet with a functional qualification:
The only difference is about coupling: contrary to knowledge systems, information and control ones play a role in their context, and operations on surrogates are not neutral.
Knowledge Archeology
Knowledge constructs are empty boxes that must be properly filled with facts. But facts are not given but must be observed, which necessarily entails some observer, set on task if not with vested interests, and some apparatus, natural or made on purpose. And if they are to be recorded, even “pure” facts observed through the naked eyes of innocent children will have to be translated into some symbolic representation. Taking wind as an example, wind socks support immediate observation of facts, free of any symbolic meaning. In order to make sense of their behaviors, wanes and anemometers are necessary, respectively for azimuth and speed; but that also requires symbolic frameworks for directions and metrics. Finally, knowledge about the risks of strong winds can be added when such risks must be considered.
Fact, Information, Knowledge
As far as enterprises are concerned, knowledge boxes are to be filled with facts about their business context and processes, organization and applications, and technical platforms. Some of them will be produced internally, others obtained from external sources, but all should be managed independently of specific purposes. Whatever their nature (business, organization or systems), information produced by the enterprises themselves is, from inception, ready to use, i.e organized around identified objects or processes, with defined structures and semantics. That’s not necessarily the case with data reflecting external contexts (markets, regulations, technology, etc) which must be mapped to enterprise concerns and objectives before being of any use. That translation of data into information may be done immediately by mapping data semantics to identified objects and processes; it may also be delayed, with rough data managed as such until being used at a later stage to build information.
From Data to Knowledge
From Data to Information
Information is meaningful, data is not. Even “facts” are not manna from heaven but have to be shaped from phenomena into data and then information, as epitomized by binary, fragmented, or “big” data.
Binary data are direct recording of physical phenomena, e.g sounds or images; even when indexed with key words they remain useless until associated, as non symbolic features, to identified objects or activities.
Contrary to binary data, fragmented data comes in symbolic guise, but as floating nuggets with sub-level granularity; and like their binary cousin, those fine-grained descriptions are meaningless until attached to identified objects or activities.
“Big” data is usually understood in terms of scalability, as it refers to lumps too large to be processed individually. It can also be defined as a generalization of fragmented data, with identified targets regrouped into more meaningful aggregates, moving the targeted granularity up the scale to some “overwhelming” level.
Since knowledge can only be built from symbolic descriptions, data must be first translated into information made of identified and structured units with associated semantics. Faced with “rough” (aka unprocessed) data, knowledge managers can choose between two policies: information can be “mined” from data using statistical means, or the information stage simply bypassed and data directly used (aka interpreted) by “knowledgeable” agents according to their context and concerns.
Non symbolic data can be interpreted by “knowledgeable” agents according to their concerns.
As a matter of fact, both policies rely on knowledgeable agents, the question being who are the “miners” and what they should know. Theoretically, miners could be fully automated tools able to extract patterns of relevant information from rough data without any prior information; practically, such tools will have to be fed with some prior “intelligence” regarding what should be looked for, e.g samples for neuronal networks, or variables for statistical regression. Hence the need of some kind of formats, blueprints or templates that will help to frame rough data into information.
Information Properties
Knowledge must be built from accurate and up-to-date information regarding external and internal state of affairs, and for that purpose information items must be managed according to their source, nature, life-cycle, and relevancy:
Source: Government and administrations, NGO, corporate media, social media, enterprises, systems, etc.
Nature: events, decisions, data, opinions, assessments, etc.
Type of anchor: individual, institution, time, space, etc.
Life-cycle: instant, time-related, final.
Relevancy: traceability with regards to business objectives, business operations, organization and systems management.
Information must be timely, understandable, and relevant
On that basis, knowledge management will have to map knowledge to its information footprint in terms of reliability (source, accuracy, consistency, obsolescence, etc) and risks.
From Information to Knowledge
Information is meaningful, knowledge is also useful. As information models, knowledge representations must first be anchored to persistency and execution units in order to support the consistency and continuity of surrogates identities (principle #1). Those anchors are to be assigned to domains managed by single organizational units in charge of ontological commitments, and enriched with structures, features, and associations (principle #2). Depending on their scope, structure or feature, semantics are to be managed respectively by persistent or application domains. Likewise, ontologies may target objects or aspects, the former being associated with structural sub-types, the latter with functional ones. Differences between information models and knowledge representation appear with rules and constraints. While the objective of information and control systems is to manage business objects and activities, the purpose of knowledge systems is to manage symbolic contents independently of their actual counterparts (principle #3). Standard rules used in system modelling describe allowed operations on objects, activities and associated information; they can be expressed forward or backward:
Forward (aka push) rules are conditions on when and how operations are to be performed.
Backward (aka pull) rules are constraints on the consistency of symbolic representations or on the execution of operations.
Standard Rules
Assuming a continuity between information and knowledge representations, the inflection point would be marked by the introduction of modalities used to qualified truth values, e.g according temporal and fuzzy logic:
Temporal extensions will put time stamps on truth values of information.
Fuzzy logic put confidence levels on truth values of information.
That is where knowledge systems depart from information and control ones as they introduce a new theory of intelligent reasoning, one based upon the fluidity and volatility of knowledge.
Meanings are in the Hands of Beholders
Seen in a corporate context, knowledge can be understood as information framed by contexts and driven by purposes: how to run a business, how to develop applications, how to manage systems. Hence the dual perspective: on one hand information is governed by enterprise concerns, systems functionalities, and platforms technology; on the other hand knowledge is driven by business processes, systems engineering, and services management.
Knowledge of Architectures, Architecture of Knowledge.
That provides a clear and comprehensive taxonomy of artifacts, to be used to build knowledge from lower layers of information and data:
Business analysts have to know about business domains and activities, organization and applications, and quality of service.
System engineers have to know about projects, systems functionalities and platform implementations.
System managers have to know about locations and operations, services, and platform deployments.
The dual perspective also points to the dynamics of knowledge, with information being pushed by the their sources, and knowledge being pulled by their users.
A Time for Every Purpose
As understood by Cybernetics, enterprises are viable systems whose success depends on their capacity to countermand entropy, i.e the progressive downgrading of the information used to govern interactions both within the organization itself and with its environment. Compared to architecture knowledge, which is organized according to information contents, knowledge architecture is organized according to functional concerns and information lifespan, and its objective is to keep internal and external information in synch:
Planning of business objectives and requirements (internal) relative to markets evolutions and opportunities (external).
Assessment of organizational units and procedures (internal) in line with regulatory and contractual environments (external).
Monitoring of operations and projects (internal) together with sales and supply chains (external).
Knowledge Architecture and Shearing Layers: strategy at leisure, time for plans, real-time operations.
That put meanings (that would be knowledge) in the hands of decision makers, respectively for corporate strategy, organization, and operations. Moreover, enterprises being living entities, lifespan and functional sustainability are meant to coalesce into consistent and homogenous layers:
Enterprise (aka business, aka strategic) time-scales are defined by environments, objectives, and investment decisions.
Organization (aka functional) time-scales are set by availability, versatility, and adaptability of resources
Operational time-scales are determined by process features and constraints.
Such a congruence of time-scales, architectures and purposes into Shearing Layers is arguably a key success factor of Knowledge management.
Search and Stretch
As already noted, knowledge is driven by purposes, and purposes, not being confined to domains or preserves, are bound to stretch knowledge across business contexts and organizational boundaries. That can be achieved through search, logic, and classification.
Searches collect the information relevant to users concerns (1). That may satisfy all the knowledge needs, or provide a backbone for further extension.
Searches can be combined with ontologies (aka classifications) that put the same information under new lights (1b).
Truth-preserving operations using mathematics or formal languages can be applied to produce derived information (2).
Finally, new information with reduced confidence levels can be produced through statistical processing (3,4).
For instance, observed traffic at toll roads (1) is used for accounting purposes (2), to forecast traffic evolution (3), to analyze seasonal trends (1b) and simulate seasonal and variable tolls (4).
Those operations entail clear consequences for knowledge management: As far as computational distances don’t affect confidence levels, truth-preserving operations are neutral with regard to KM. Classifications are symbolic tools designed on purpose; as a consequence all knowledge associated to a classification should remain under the responsibility of its designer. Challenges arise when confidence levels are affected, either directly or through obsolescence. And since decision-making is essentially about risks management, dealing with partial or unreliable information cannot be avoided. Hence the importance of managing knowledge along shearing layers, each with its own information life-cycle, confidence requirements, and decision-making rules.
From Knowledge Architecture to Architecture Capability
Knowledge architecture is the corporate central nervous system, and as such it plays a primary role in the support of operational and managerial processes. That point is partially addressed by Frameworks like Zachman whose matrix organizes Information System Architecture (ISA) along capabilities and design levels. Yet, as illustrated by the design levels, the focus remains on information technology without explicitly addressing the distinction between enterprise, systems, and platforms.
Capabilities can be defined across architecture layers with regard to business, engineering, and operational processes
That distinction is pivotal because it governs the distinction between corresponding processes, namely business processes, systems engineering, and services managements. And once the distinction is properly established knowledge architecture can be aligned with processes assessment.
Yet that will not be enough now that digital environments are invading enterprise systems, blurring the distinction between managed information assets and the continuous flows of big data.
The outer range anchors enterprise architecture and objectives to business environments
That puts the focus on two structural flaws of enterprise architectures:
The confusion between data, information, and knowledge.
The intrinsic discrepancy between systems and knowledge architectures.
Both can be overcame by merging system and knowledge architectures applying the Pagoda blueprint:
Pagoda Architecture Blueprint
The alignment of platforms, systems functionalities, and enterprise organization respectively with data (environments), information (symbolic representations), and knowledge (business intelligence) would greatly enhance the traceability of transformations induced by the immersion of enterprises in digital environments.
Knowledge Representation & Profiled Ontologies
Faced with digital business environments, enterprise must sort relevant and accurate information out of continuous and massive inflows of data. As modeling methods cannot cope with the open range of contexts, concerns, semantics, and formats, looser schemes are needed, that’s precisely what ontologies are meant to do:
Thesaurus: ontologies covering terms and concepts.
Documents: ontologies covering documents with regard to topics.
Business: ontologies of relevant enterprise organization and business objects and activities.
Engineering: symbolic representation of organization and business objects and activities.
Ontologies: Purposes & Targets
Profiled ontologies can then be designed by combining that taxonomy of concerns with contexts, e.g:
Institutional: Regulatory authority, steady, changes subject to established procedures.
Professional: Agreed upon between parties, steady, changes subject to accords.
Corporate: Defined by enterprises, changes subject to internal decision-making.
Social: Defined by usage, volatile, continuous and informal changes.
Personal: Customary, defined by named individuals (e.g research paper).
Last but not least, external (regulatory, businesses, …) and internal (i.e enterprise architecture) ontologies could be integrated, for instance with the Zachman framework:
Ontologies, capabilities (Who,What,How, Where, When), and architectures (enterprise, systems, platforms).
Using profiled ontologies to manage enterprise architecture and corporate knowledge will help to align knowledge management with EA governance by setting apart ontologies defined externally (e.g regulations), from the ones set through decision-making, strategic (e.g plate-form) or tactical (e.g partnerships).
An ontological kernel has been developed as a Proof of Concept using Protégé/OWL 2; a beta version is available for comments on the Stanford/Protégé portal with the link: Caminao Ontological Kernel (CaKe).
From Data Analysis to Deep Learning
Set between all-inclusive onslaught of data on one side, pervasive smart bots on the other side, information systems could lose their identity and purpose. And there is a good reason for that, namely the confusion between data, information, and knowledge.
Knowledge is the ability to make differences
As it happened aeons ago, ontologies have been explicitly though up to deal with that issue.
Reuse of development artifacts can come by design or as an afterthought. While in the latter case artifacts may have been originally devised for specific contexts and purposes, in the former case they would have been originated by shared concerns and designed according architectural constraints and mechanisms.
Reinventing the Wheel ? (Ready-made, M. Duchamp)
Architectures for their part are about stable and sound assets and mechanisms meant to support activities which, by nature, must be adaptable to changing concerns. That is precisely what reusable assets should be looking for, and that may clarify the rationale supporting models and languages:
Why models: to describe shared (i.e reused) artifacts along development processes.
Why non specific languages: to support the sharing of models across business domains and organizational units.
Why model layers: to manage reusable development assets according architectural concerns.
Reuse Perspective: Business Domains vs Development Artifacts
As already noted, software artifacts incorporate contents from two perspectives:
Domain models describe business objects and processes independently of the way they are supported by systems.
Development models describe how to design and implement system components.
Artifacts reflect external as well as development concerns.
As illustrated by agile methods and domain specific languages, that distinction can be ignored when applications are self-contained and projects ownership is shared. In that case reusable assets are managed along business domains, functional architectures are masked, and technical ones are managed by development tools.
Otherwise, reusable assets would be meaningless, even counterproductive, without being associated with clearly defined objectives:
Domain models and business processes are meant to deal with business objectives, for instance, how to assess insurance premiums or compute missile trajectory.
System functionalities lend a hand in solving business problems. Use cases are widely used to describe how systems are to support business processes, and system functionalities are combined to realize use cases.
Platform components provide technical solutions as they achieve targeted functionalities for different users, within distributed locations, under economic constraints on performances and resources.
Context and purpose of reusable assets
Whatever the basis, design or afterthought, reusing an artifact comes as a solution to a specific problem: how to support business requirements, how to specify system functionalities, how to implement system components. Describing problems and solutions along architecture layers should therefore be the backbone of reusable assets management.
Model and Architecture Layers
According model driven architecture principles, models should be organized around three layers depending on contents:
Computation independent models (CIMs) describe business objects and processes independently of the way they are supported by system functionalities. Contents are business specific that can be reused when functional architectures are modified (a). Business specific contents (e.g business rules) can also be reused when changes do not affect functional architectures and may therefore be directly applied to platform specific models (c).
Platform independent models (PIMs) describe system functionalities independently of supporting platforms. They are reused to design new supporting platforms (b).
Platform specific models (PSMs) describe software components. They are used to implement software components to be deployed on platforms (d).
Model and Architecture Layers
Not by chance, invariants within model layers can also be associated with corresponding architectures:
Enterprise architecture (as described by CIMs) deals with objectives, assets and organization associated with the continuity of corporate identity and business capabilities within a regulatory and market environment.
Functional architecture (as described by PIMs) deals with the continuity of systems functionalities and mechanisms supporting business processes.
Technical architecture (as described by PSMs) deals with the feasibility, interoperability, efficiency and economics of systems operations.
That makes architecture invariants the candidates of choice for reusable assets.
Enterprise Architecture Assets
Systems context and purposes are set by enterprise architecture. From an engineering perspective reusable assets (aka knowledge) must include domains, business objects, activities, and processes.
Domains are used to describe the format and semantics of elementary features independently of objects and activities.
Business objects identity and consistency must be maintained along time independently of supporting systems. That’s not the case for features and rules which can be modified or extended.
Activities (and associated roles) describe how business objects are to be processed. Semantics and records have to be maintained along time but details of operations can change.
Business processes and events describe how activities are performed.
Enterprise Architecture Assets (anchors and semantic domains)
As far as enterprise architecture is concerned, structure and semantics of reusable assets should be described independently of system modeling methods.
Structures can be unambiguously described with standard connectors for composition, aggregation and reference, and variants by subsets and power-types, both for static and dynamic partitions.
With regard to business activities, semantics are set by targets:
Processing of physical objects.
Processing of notional objects.
Agents decisions.
Processing of events.
Computations.
Control of processes execution.
Regarding business objects, semantics are set by what is represented:
State of physical objects.
State of notional object.
History of roles.
Events.
Computations.
Execution states.
Enterprise Architecture Assets (with variants and stereotypes)
Enterprise assets are managed according identification, structure, and semantics, as defined along a business perspective. When reused as development artifacts the same attributes will have to be mapped to an engineering perspective.
Use Cases: A bridge between Enterprise and System Architectures
Systems are supposed to support the continuity and consistency of business processes independently of platforms technologies. For that purpose two conditions must be fulfilled:
Identification continuity of business domains: objects identities are kept in sync with their system representations all along their life-cycle, independently of changes in business processes.
Semantic continuity of functional architectures: the history of system representations can be traced back to associated business operations.
Hence, it is first necessary to anchor requirements objects and activities to persistency and functional execution units.
Reusing persistency and functional units to anchor new requirements to enterprise architecture.
Once identities and semantics are properly secured, requirements can be analyzed along standard architecture levels: boundaries (transient objects, local execution), controls (transient objects, shared execution), entities (persistent objects, shared execution).
The main objective at this stage is to identify shared functionalities whose specification should be factored out as candidates for reuse. Three criteria are to be considered:
System boundaries: no reusable assets can stand across systems boundaries. For instance, were billing outsourced the corresponding activity would have to be hid behind a role.
Architecture level: no reusable assets can stand across architecture levels. For instance, the shared operations for staff interface will have to be regrouped at boundary level.
Coupling: no reusable asset can support different synchronization constraint. For instance, checking in and out are bound to external events while room updates and billing are not.
Using stereotypes to identify shared functionalities along architecture levels
It’s worth to note that the objectives of requirements analysis do not depend on the specifics of projects or methods:
Requirements are to be anchored to objects identities and activities semantics either through use cases or directly.
Functionalities are to be consolidated either within new requirements and/or with existing applications.
The Cases for Reuse
As noted above, models and non specific languages are pivotal when new requirements are to be fully or partially supported by existing system functionalities. That may be done by simple reuse of current assets or may call for the consolidation of existing and new artifacts. In any case, reusable assets must be managed along system boundaries, architecture levels, and execution coupling.
For instance, a Clean Room use case goes like: the cleaning staff manages a list of rooms to clean, checks details for status, cleans the room (non supported), and updates lists and room status.
Reuse of Functionalities
Its realization entails different kinds of reuse:
Existing persistency functionality, new business feature: providing a cleaning status is added to the Room entity, Check details can be reused directly (a).
Consolidated control functionality and delegation: a generic list manager could be applied to customers and rooms and used by cleaning and reservation use cases (b).
Specialized boundary functionality: staff interfaces can be composed of a mandatory header with optional panels respectively for check I/O and cleaning (c).
Reuse and Consolidation of functionalities
Reuse and Functional Architecture
Once business requirements taken into account, the problem is how to reuse existing system functionalities to support new functional requirements. Beyond the various approaches and terminologies, there is a broad consensus about the three basic functional levels, usually labelled as model, view, controller (aka MVC):
Model: shared and a life-cycle independent of business processes. The continuity and consistency of business objects representation must be guaranteed independently of the applications using them.
Control: shared with a life-cycle set by a business process. The continuity and consistency of representations is managed independently of the persistency of business objects and interactions with external agents or devices.
View: what is not shared with a life-cycle set by user session. The continuity and consistency of representations is managed locally (interactions with external agents or devices independently of targeted applications.
Service: what is shared with no life-cycle.
The Cases for Functional Reuse
Assuming that functional assets are managed along those levels, reuse can be achieved by domains, delegation, specialization, or generalization:
Semantic domains: shared features (addresses, prices, etc) should reuse descriptions set at business level.
Delegation: part of a new functionality (+) can be supported by an existing one (=).
Specialization: a new functionality is introduced as an extension (+) of an existing one (=).
Generalization: a new functionality is introduced (+) and consolidated with existing ones (~) by factoring out shared features (/).
It must be noted that while reuse by delegation operates at instance level and may directly affect coupling constraints on functional architectures, that’s not the case for specialization and generalization which are set at type level and whose impact can be dealt with by technical architectures.
Single-Responsibility Principle (SRP) : software artifacts should have only one reason to change.
Open-Closed Principle (OCP) : software artifacts should be open for extension, but closed for modification.
Liskov Substitution Principle (LSP): Subtypes must be substitutable for their base types. In other words a given set of instances must be equally mapped to types whatever the level of abstraction.
Dependency-Inversion principle (DIP): high level functionalities should not depend on low level ones. Both should depend on abstract interfaces.
Interface-Segregation Principle (ISP): client software artifacts should not be forced to depend on methods that they do not use.
Reuse by Delegation
Delegation should be considered when different responsibilities are mixed that could be set apart. That will clearly foster more cohesive responsibilities and may also bring about abstract (i.e functional) descriptions of low level (i.e technical) operations.
Reuse by Delegation
Reuse may be actual (the targeted asset is already defined) or forthcoming (the targeted asset has to be created). Service Oriented Architectures are the archetypal realization of reuse by delegation.
Since it operates at instance level, reuse by delegation may overlap functional layers and therefore introduce coupling constraints on data or control flows that could not be supported by targeted architectures.
Reuse by Specialization
Specialization is to be considered when a subset of objects has some additional features. Assuming base functionalities are not affected, specialization fulfills the open-closed principle. And being introduced for a subset of the base population it will also guarantee the Liskov substitution principle.
Reuse by Specialization
Reuse may be actual (a base type already exists) or forthcoming (base and subtype are created simultaneously).
Since it operates at type level, reuse by specialization is supposed to be dealt with by technical architectures. As a corollary, it should not overlap functional layers.
Reuse by Generalization
Generalization should be considered when different sets of objects share a subset of features. Contrary to delegation and specialization, it does affect existing functionalities and may therefore introduce adverse outcomes. While pitfalls may be avoided (or their consequences curbed) for boundary artifacts whose execution is self-contained, that’s more difficult for control and persistency ones, which are meant to support multiple execution within shared address spaces.
When artifacts are used to create transient objects run in self-contained contexts, generalization is straightforward and the factoring out of shared features (a) will clearly further artifacts reuse .
Reuse by generalization put open-closed and interface-segregation principles at risk.
Yet, through its side-effects, generalization may also undermine the design of the whole, for instance:
The open-closed principle may be at risk because when part of a given functionality is factored out, its original semantics are meant to be modified in order to be reused by siblings. That would be the case if authorize() was to be modified for initial screen subtypes as a consequence of reusing the base screen for a new manager screen (b).
Reuse by generalization may also conflict with single-responsibility and interface-segregation principles when a specialized functionality is made to reuse a base one designed for its new siblings. For instance, if the standard reservation screen is adjusted to make room for manager screen it may take into account methods specific to managers (c).
Those problems may be compounded when reuse is applied to control and persistency artifacts: when a generic facility handler and the corresponding record are specialized for a new reservation targeting cars, they both reuse instantiation mechanisms and methods supporting multiple execution within shared address spaces; that is not the case for generalization as the new roots for facility handler and reservation cannot be achieved without modifying existing handler and recording of room reservations.
Reuse by Abstraction: Specialization is safer than Generalization
Since reuse through abstraction is based on inheritance mechanisms, that’s where the cases for reuse are to be examined.
Reuse by Inheritance
As noted above, reuse by generalization may undermine the design of boundaries, control, and persistency artifacts. While risks for boundaries are by nature local and limited to static descriptions, at control and persistency layers they affect instantiation mechanisms and shared execution at system level. And those those pitfalls can be circumscribed by a distinction between objects and aspects.
Object types describe set of identified instances. In that case reuse by generalization means that objects targeted by new artifact must be identified and structured according the base descriptions whose reuse is under consideration. From a programming perspective object types will be eventually implemented as concrete classes.
Aspect types describe behaviors or functionalities independently of the objects supporting them. Reuse of aspects can be understood as inheritance or composition. From a programming perspective they will be eventually implemented as interfaces or abstract classes.
Unfettered by programming languages constraints, generalization can be given consistent and unambiguous semantics. As a consequence, reuse by generalization can be introduced selectively to structures and aspects, with single inheritance for the former, multiple for the latter.
Not by chance, that distinction can be directly mapped to the taxonomy of design patterns proposed by the Gang of Four:
Creational designs deal with the instanciation of objects.
Structural designs deal with the building of structures.
Behavioral designs deal with the functionalities supported by objects.
Applied to boundary artifacts, the distinction broadly coincides with the one between main windows (e.g Java Frames) on one hand, other graphical user interface components on the other hand, with the former identifying users sessions. For example, screens will be composed of a common header and specialized with components for managers and staffs. Support for reservation or cleaning activities will be achieved by inheriting corresponding aspects.
Reuse of boundary artifacts through structures and aspects inheritance
Freed from single inheritance constraints, the granularity of functionalities can be set independently of structures. Combined with selective inheritance, that will directly benefit open-closed, single-responsibility and interface-segregation principles.
The distinction between identifying structures on one hand, aspects on the other hand, is still more critical for artifacts supporting control functionalities as they must guarantee multiple execution within shared address spaces. In other words reuse of control artifacts should first and foremost be about managing identities and conflicting behaviors. And that can be best achieved when instantiation, structures, and aspects are designed independently:
Whatever the targeted facility, a session must be created for, and identified by, each user request (#). Yet, since reservations cannot be processed independently, they must be managed under a single control (aka authority) within a single address space.
That’s not the case for the consultation of details which can therefore be supported by artifacts whose identification is not bound to sessions.
Reuse of control artifacts through structures and aspects inheritance
Extensions, e.g for flights, will reuse creation and identification mechanisms along strong (binding) inheritance links; generalization will be safer as it will focus on clearly defined operations. Reuse of aspects will be managed separately along weak (non binding) inheritance links.
Reuse of control artifacts through selective inheritance may be especially useful with regard to dependency-inversion principle as it will facilitate the distinction between policy, mechanism, and utility layers.
Regarding artifacts supporting persistency, the main challenge is about domains consistency, best addressed by the Liskov substitution principle. According to that principle, a given set of instances should be equivalently represented independently of the level of abstraction. For example, the same instances of facilities should be represented identically as such or according their types. Clearly that will not be possible with overlapping subsets as the number of instances will differ depending on the level of abstraction.
But taxonomies being business driven, they usually overlap when the same objects are targeted by different business domains, as could be the case if reservations were targeting transport and lodging services while facility providers were managing actual resources with overlapping services. With selective inheritance it will be possible to reuse aspects without contradicting the substitution principle.
Reuse of persistency artifacts through structures and aspects inheritance
Reuse across Functional Architecture Layers
Contrary to reuse by delegation, which relates to instances, reuse by abstraction relates to types and should not be applied across functional architecture layers lest it would break the separation of concerns. Hence the importance of the distinction between reuse of structures, which may impact on identification, and the reuse of aspects, which doesn’t.
Given that reuse of development artifacts is to be governed along architecture levels (enterprise, system functionalities, platform technologies) on one hand, and functional layers (boundaries, controls, persistency) on the other hand, some principles must be set regarding eligible mechanisms.
Two mechanisms are available for type reuse across architecture levels:
Semantics domains are defined by enterprise architecture and can be directly reused by functionalities.
Design patterns enable the transformation of functional assets into technical ones.
Otherwise reuse policies must follow functional layers:
Base entities are first anchored to business objects (1), with possible subsequent specialization (1b). Generalization must distinguish between structures and aspects lest to break continuity and consistency of representations.
Base controls are anchored to business activities and may reuse entities (2). They may be specialized (2b). Generalization must distinguish between structures and aspects lest to break continuity and consistency of business processes.
Base boundaries are anchored to roles and may reuse controls (3). They may be specialized (3b). Generalization must distinguish between structures and aspects lest to break continuity and consistency of sessions.
Despite its object and unified vocations, the OMG’s UML (Unified Modeling Language) has been sitting uneasily between scopes (e.g requirements, analysis, and design), as well as between concepts (e.g objects, aspects, and domains).
Where to look for AAA issues (Maurizio Cattelan)
Those misgivings probably go a long way to explain the limited, fragmented, and shallow footprint of UML despite its clear merits. Hence the benefits to be expected from a comprehensive and consistent approach of object-oriented modeling based upon two classic distinctions:
Business vs System: assuming that systems are designed to manage symbolic representations of business objects and processes, models should keep the distinction between business and system objects descriptions.
Identity vs behavior: while business objects and their system counterpart must be identified uniformly, that’s not the case for aspects of symbolic representations which can be specified independently.
That two-pronged approach bridges the gap between analysis and design models, bringing about a unified perspective for concepts (objects and aspects) as well as scope (business objects and system counterparts).
Object Oriented Modeling
Object Oriented and Relational approaches are arguably the two main advances of software engineering for the last 50 years. Yet, while the latter is supported by a fully defined theoretical model, the former still mostly stands on the programming languages supporting it. That is somewhat disappointing considering the aims of the Object Management Group (OMG),
UML was born out of the merge of three modeling methods: the Booch method, the Object-modeling technique (OMT) and Object-oriented software engineering (OOSE), all strongly marked by object orientation. Yet, from inception, the semantics of objects were not clearly defined, when not explicitly confused under the label “Object Oriented Analysis and Design” (OOA/D). In other words, the mapping of business contexts to system objects, a critical modeling step if there is any, has been swept under the carpet.
Literal Bird
That’s a lose/lose situation. Downstream, OO approaches, while widely accepted at design level, remain fragmented due to the absence of a consensus regarding object semantics outside programming languages. Upstream, requirements are left estranged from engineering processes, either forcing analysts to a leap of faith over an uncharted no man’s land, or to let business objects being chewed up by programming constructs.
Domains and Images
In mathematics, an image is the outcome of a function mapping its source domain to its target co-domain. Applied to object-oriented modeling, the problem is to translate business objects to their counterpart as system components. For that purpose one needs to:
Define domains as sets of business objects and activities whose semantics and life-cycle are under the authority of a single organizational unit.
Identify the objects and phenomena whose representation has to be managed, as well as the lifespan of those representations.
Define the features (attributes or operations) to be associated to system objects.
Define the software artifacts to be used to manage the representations and implement the features.
From Business Domain to System Image
While some of those objectives can be set on familiar grounds, the four must be reset into a new perspective.
Business Objects are rooted in Concerns
Physical or symbolic, objects and activities are set by concerns. Some may be local to enterprises, some defined by common business activities, and some set along a broader social perspective. The first step is therefore to identify the organizational units responsible for domains, objects identities and semantics:
Domains in charge of identities will govern objects life-cycle (create and delete operations) and identification mechanisms (fetch operations). That would target objects, agents, events and processes identified independently of systems.
Domains in charge of semantics will define objects features (read and update operations). That would target aspects and activities rooted (aka identified) through primary objects or processes.
Context anchors and associated roles and activities
It must be noted that whereas the former are defined as concrete sets of identified instances governed by unique domains, the latter may be defined independently of the objects supporting them, and therefore may be governed by overlapping concerns set by different domains.
Objects and Architectures
Not by chance, the distinction between identities and features has an architectural equivalent. Just like buildings, systems are made of supporting structures and subordinate constructs, the former intrinsic and permanent, the latter contingent and temporary. Common sense should therefore dictate a clear distinction between modeling levels, and put the focus on architectures:
Enterprise architecture deals with objectives, assets and organization associated with the continuity of corporate identity and business capabilities within a given regulatory and market environment. That is where domains, objects and activities are identified and defined.
Functional architecture deals with the continuity of systems functionalities as they support the continuity of business memory and operations. At this level the focus is not on business objects or activities but on functions supported by the system: communication, control, persistency, and processing.
Technical architecture deals with the feasibility, efficiency and economics of systems operations. That is where the software artifacts supporting the functions are designed .
Objects and Architectures
Objects provide the hinges binding architectural layers, and models should therefore ensure direct and transparent mapping between business objects, functional entities, and system components. That’s not the case for features whose specification and implementation can and should be managed separately.
Confusing business contexts with their system counterparts leads to mistaken equivalence between features respectively supported by business objects and system artifacts:
The state of physical objects may be captured or modified through specific interfaces and persistently recorded by symbolic representations, possibly with associated operations.
Non physical (notional) business objects are identified and persistently recorded as such. Their state may also appear as transient objects associated with execution states and processing rules.
Events have no life-cycle and therefore don’t have to be identified on their own. Their value is obtained through interfaces; associated messages can be used by control or processing functions; values can be recorded persistently. Since the value of past events is not meant to be modified operations are irrelevant except for interfaces.
Actual processes are identified by execution context and timing. There state may be queried through interfaces and recorded, but persistent records cannot be directly modified.
Symbolic processes are identified by footprint independently of actual execution. Their execution may be called through interfaces and the results may be recorded, but persistent records cannot be directly modified.
External roles are identified by the interfaces supporting the interactions. Their activity may be recorded, but persistent records cannot be directly modified.
Fleshing out Aspects
By introducing complementary levels of indirection between business and system objects on one hand, identities and features on the other hand, the proposed approach significantly further object-oriented modeling from requirements analysis to system design. Moreover, this approach provides a robust and effective basis for the federation of business domains, by modeling separately identities and semantic features while bridging across conceptual, logical and physical information models.
Untangling Business Rules
However tangled and poorly formulated, rules provide the substance of requirements as they express the primary constraints, needs and purposes. That jumble can usually be reshaped differently depending on perspective (business or functional requirements), timing constraints (synchronous or asynchronous) or architectural contexts; as a corollary, the way rules are expressed will have a significant impact on the functional architecture of the system under consideration. Hence, if transparency and traceability of functional and technical arbitrages are to be supported, the configuration of rules has to be rationalized from requirements inception. And that can be achieved if rules can be organized depending on their footprint: domains, instances, or attitudes.
From Objects to Artifacts
Requirements analysis is about functional architecture and business semantics, design is about software artifacts used to build system components. The former starts with concrete descriptions and winds up with abstract ones, the latter takes over the abstractions and devise their concrete implementation.
Uphill to functionalities, downhill to implementations
Somewhat counter-intuitively, information processing is very concrete as it is governed by actual concerns set from biased standpoints. Hence, trying to abstract requirements of supporting systems up to some conceptual level is a one way ticket to misunderstandings because information flows are rooted in the “Here and Now” of business concerns. Abstract (aka conceptual) descriptions are the outcome of requirements analysis, introduced when system symbolic representations are consolidated across business domains and processes.
Starting with a concrete description of identified objects and processes, partitions are used to analyze the variants and select those bound to identities. Inheritance hierarchies can organized accordingly, for objects or aspects.
Inheritance of identities vs inheritance of aspects.
While based on well understood concepts, the distinction between identity and aspect inheritance provides a principled object-oriented bridge between requirements and models free of any assumption regarding programming language semantics for abstract classes or inheritance.
Objects, attitudes, and Programming Languages
Because object-oriented approaches often stem from programming languages, their use for analysis and design is hampered by some lack of consensus and a few irrelevant concepts. That is best illustrated by two constructs, abstract classes and interfaces.
Most programming languages define abstract classes as partial descriptions and, as a result, the impossibility to be instantiated. When applied to business objects the argument is turned around, with the consequence, no instance, taken as the definition.
Interfaces are also a common features of object-oriented languages, but not only, as they may be used to describe the behavior of any software component.
Those distinctions can be settled when set within a broader understanding of objects and aspects, the former associated with identified instances with bound structures, eventually implemented as concrete classes, the latter with functionalities, eventually implemented as abstract classes or interfaces.
From Analysis to Design
A pivotal benefit of distinguishing between objects identity and aspects is to open a bridge between analysis and design by unifying respective patterns along object-oriented perspective. Taking a cue from the Gang of Four, system functionalities could be organized along three basic pattern categories:
Creational functionalities deal with the life-cycle (create and delete operations) and identification mechanisms (fetch operations) of business objects whose integrity and consistency has to be persistently maintained independently of activities using them.
Structural functionalities deal with the structure and semantics of transient objects whose integrity and consistency has to be maintained while in use by activities. They will govern features (read and update operations) and target aspects and activities rooted (aka identified) through primary objects or processes.
Behavioral functionalities deal with the ways objects are processed.
Mapping analysis patterns to design ones will greatly enhance models traceability; moreover, taking advantage of the relative maturity of design patterns, it may also boost quality across model layers as well as the whole effectiveness of model driven engineering solutions.
Objects Oriented Modeling and Model Driven Engineering
The double distinction between contexts and systems on one hand, objects and aspects on the other hand, should help to clarify the contents of modeling layers as defined by OMG’s model driven architecture (MDA):
Computation independent models (CIMs) are structured around business objects and processes identified on their own, associated with organizational details for roles and activities.
Platform independent models (PIMs) are organized on two levels, one for functional architectures (boundaries, processes, persistency, services, communication), the other one for associated aspects.
Platform specific models (PSMs) are similarly designed on two levels, one mapping functional architectures, the other one implementing aspects.
MDA with UML#
Using UML#, object-oriented concepts can therefore be applied uniformly from requirements to design without forcing programming semantics into models.
Models are representations and as such they are necessarily set in perspective and marked out by concerns.
Model, Perspective, Concern (R. Doisneau).
Depending on perspective, models will encompass whole contexts (symbolic, mechanic, and human components), information systems (functional components), software (components implementation).
Depending on concerns models will take into account responsibilities (enterprise architecture), functionalities (functional architecture), and operations (technical architecture).
While it may be a sensible aim, perspectives and concerns are not necessarily congruent as responsibilities or functionalities may cross perspectives (e.g support units), and perspectives may mix concerns (e.g legacies and migrations). That conundrum may be resolved by a clear distinction between descriptive and prescriptive models, the former dealing with the problem at hand, the latter with the corresponding solutions, respectively for business, system functionalities, and system implementation.
Models as Knowledge
Assuming that systems are built to manage symbolic representations of business domains and operations, models are best understood as knowledge, as defined by the pivotal article of Davis, Shrobe, and Szolovits:
Surrogate: models provide the description of symbolic objects standing as counterparts of managed business objects and activities.
Ontological commitments: models include statements about the categories of things that may exist in the domain under consideration.
Fragmentary theory of intelligent reasoning: models include statements of what the things can do or can be done with.
Medium for efficient computation: making models understandable by computers is a necessary step for any learning curve.
Medium for human expression: models are meant to improve the communication between specific domain experts on one hand, generic knowledge managers on the other hand.
Surrogates without Ontological Commitment
What You Think Is What You Get
Whereas conventional engineering has to deal with physical artifacts, software engineering has only symbolic ones to consider. As a consequence, design models can be processed into products without any physical impediments: “What You Think Is What You Get.”
Products and Usage are two different things
Yet even well designed products are not necessarily used as expected, especially if organizational and business contexts have changed since requirements capture.
Models and Architectures
Models are partial or complete descriptions of existing or intended systems. Given that systems will eventually be implemented by software components, models and programs may overlap or even be congruent in case of systems made exclusively of software components. Moreover, legacy systems are likely to get along together with models and software components. Such cohabitation calls for some common roof, supported by shared architectures:
Enterprise architecture deals with the continuity of business concerns.
System architecture deals with the continuity of systems functionalities.
Technical architecture deals with the continuity of systems implementations.
That distinction can also be applied to engineering problems and solutions: business (>enterprise), organization (supporting systems), and development (implementations).
Problems and solutions must be set along architecture layers
On that basis the aim of analysis is to define the relationship between business processes and supporting systems, and the aim of design is to do the same between system functionalities and components implementation.
Whatever the terminology (layers or levels), what is at stake is the alignment of two basic scales:
Architectures: enterprise (concepts), systems (functionalities), and platforms (technologies).
If systems could be developed along a “fire and forget” procedure models would be used only once. Since that’s not usually the case bridges between business contexts and supporting systems cannot be burned; models must be built and maintained both for business and system architectures, and the semantics of modeling languages defined accordingly.
Languages, Concerns, Perspectives
Apart for trivial or standalone applications, engineering processes will involve several parties whose collaboration along time will call for sound languages. Programming languages are meant to be executed by symbolic devices, business languages (e.g B.P.M.) are meant to describe business processes, and modeling languages (e.g UML) stand somewhere in-between.
As far as system engineering is concerned, modeling languages have two main purposes: (1) describe what is expected from the system under consideration, and (2) specify how it should be built. Clearly, the former belongs to the business perspective and must be expressed with its specific words, while the latter can use some “unified” language common to system designers.
The Unified Modeling Language (UML) is the outcome of the collaboration between James Rumbaugh with his Object-modeling technique (OMT), Grady Booch, with his eponymous method, and Ivar Jacobson, creator of the object-oriented software engineering (OOSE) method.
Whereas UML has been accepted as the primary standard since 1995, it’s scope remains limited and its use shallow. Moreover, when UML is effectively used, it is often for the implementation of Domain Specific Languages based upon its stereotype and profile extensions. Given the broadly recognized merits of core UML constructs, and the lack of alternative solutions, such a scant diffusion cannot be fully or even readily explained by subordinate factors. A more likely pivotal factor may be the way UML is used, in particular in the confusion between perspectives and concerns.
Perspectives and Concerns: business, functionalities, implementation
Languages are useless without pragmatics which, for modeling ones means some methodology defining what is to be modeled, how, by who, and when. Like pragmatics, methods are diverse, each bringing its own priorities and background, be it modeling concepts (e.g OOA/D), procedures (e.g RUP), or collaboration agile principles (e.g Scrum). As it happens, none deals explicitly with the pivotal challenges of the modeling process, namely: perspective (what is modeled), and concern (whose purpose).
Processes can be designed, assessed and improved by matching development patterns with development strategies.
Matching Concerns and Perspectives
As famously explained by Douglas Hofstadter’s Eternal Golden Braid, models cannot be proven true, only to be consistent or disproved.
Depending on language, internal consistency can be checked through reviews (natural language) or using automated tools (formal languages).
Refutation for its part entails checks on external consistency, in other words matching models and concerns across perspectives. For that purpose modeling stations must target well defined sets of identified objects or phenomena and use clear and non ambiguous semantics. A simplified (yet versatile), modeling cycle could therefore be exemplified as follows:
Identify a milestone relative to perspective, concern, and architecture.
Select anchors (objects or activities).
Add connectors and features.
Check model for internal consistency.
Check model for external consistency, e.g refutation by counter examples.
Whereas it is based upon well known concepts and accepted standards, the Caminao approach entails a new modeling perspective which calls for change of habits, mostly at requirements level. The objective here is to experiment some Proof of Concept by contriving requirements on-line along the Caminao path.
Collecting Requirements (Jeff Wall)
For that purpose the proposed experiment makes use of four principles:
Crowd-sourcing: except for Caminao stereotypes, understanding do not come from a special expertise or best-practices but is built on collective wisdom.
Iterations: stakeholders and analysts are circling topics until they agree on clear and unambiguous pictures.
Illustrations: requirements begin as expectations, as such they should be best captured through pictures before being analyzed through models.
Assertions: requirements are meant to translate into commitments, hence, associated models should be settled by explicit constraints and expressions.
Requirements loops: from expectations to commitments.
On that basis stakeholders will introduce their requirements as illustrations, analysts will try to translate them into models which, after being accepted by stakeholders, will subsequently be decorated by assertions.
Modus Operandi
Requirements rings are managed through the G+ Caminao Rings page.
In order to submit a project, candidate stakeholders must belong to the circle of fellows.
Fellows stakeholders may submit projects by creating their own G+ pages and circles and identifying them with the Caminao G+. A new page is created for each project, to be matched with the fellow G+ circle.
Fellow analysts propose models capturing all or parts of illustrated requirements.
Stakeholders may accept, reject, or hold back their decision. Refusals can be commented but reservations can only be qualified with additional illustrations.
Once approved models may subsequently be fleshed out with expressions, constraints and rules.
Models
Fellow analysts can propose two types of models:
Horizontal models describe individual artifacts and their connections.
Vertical models are anchored to single artifacts and focus on their partitions and inheritance relationships.
While it’s recommended to walk along basic UML conventions, models may include any kind of artifacts providing they are qualified by Caminao stereotypes for actual or symbolic objects and activities, roles, or events.
Caminao stereotypes for nodes
Stereotypes for containers use the same principle for organizational units (110) physical locations (121), physical executions (141), business domains (120), business activities (140).
The semantics of connectors (association, flow, transition, or channel) can remain implicit and defined by context. They may be stereotyped using standard set operators.
Set-based stereotypes for Connectors
By convention, objects, events and roles are labelled with singular nouns, activities use infinitive verbs, and processes use present progressive ones. Containers are named with plurals.
Who’s in the Loops
Four types of players may appear in requirements loops:
Stakeholders (one by project) set the context and objectives with pictures, photos or drawings. Textual descriptions are not allowed. Stakeholders accept or reject artifacts.
Users and business analysts add to the stakeholder requirements using the same media (no texts); they also may qualify model artifacts with formal expressions, constraints or rules.
System analysts suggest artifacts.
Architects (one by project) accept or reject qualifications on artifacts.
Who’s in the Loop
Mind Your Words
Language and meanings may be baffling bedfellows, as what is said is not necessarily what is meant. As a boost to requirements transparency, a simple gizmo may be used by players to speak their mind, for their interlocutor (talking bubble) or only for the audience (thinking bubble).
Say What You Mean, Mean What You Say
Price Your Words
Assuming clear understanding and good faith, customers and providers must agree on a price, and for that purpose they must align their respective expectations and commitments.
Expecting to take advantage of business opportunities at a given time, customers define system requirement along a black box perspective; in return, providers analyze those requirements along a white box perspective and make an estimate of cost and duration. Their respective expectations are consolidated and commitments made, customers regarding payment, provider regarding delivery.
As far as customers are concerned, success is measured by the return on investment (ROI), which depends on cost, quality, and timely delivery. Providers for their part will design the solution, develop the components, and integrate them into targeted environments. Narrowly defined, their success will be measured by costs. Those concerns may be played along a non-zero sum game:
Customers assess the benefits (a) to be expected from the functionalities under consideration (b).
Providers consider the solutions (a) and estimate their costs (b).
Customers and providers agree on functionalities, costs and schedules (c).
Matching respective expectations and commitments of customers and providers.
Hence, while stakes are clearly conflicting on costs, there is room for collaboration on quality and timing, and that will bring benefits to both customers and providers.
Square the Rings
Even for standalone applications, it’s safe to assume that requirements will have to take into account external factors and constraints. Since those requirements will usually be managed by different organizational units, they must be sorted out upfront:
Non functional constraints deal with performances and resources.
Cross functional requirements deal with system functionalities shared by different business processes.
Application specific requirements deal with system functionalities supporting a single business process.
Squaring requirements rings
Those rings are used to organize projects according the requirements architectural footprint and associated responsibilities.
Caminao aims to chart all worlds of system models, drawing maps with a kernel of the UML, based upon a reasoned conceptual framework.
Set from a comprehensive and objective survey of system functionalities and architectures, using standard notation applied to unambiguous concepts, those maps should provide all-weather guidance to system modellers, whatever their bearings or creed.
Models, Architectures, Perspectives (MAPs)
Of all industrial artifacts, software components are the only ones that can be fully built from models. As a consequence, charting comprehensive and reliable maps should not only be feasible but also highly beneficial.
Caminao maps are built from models, architectures, and perspectives:
Models set the stages, where targeted artifacts are defined depending on concerns.
Topography put objects into perspective as set by stakeholders situation: business objectives, system functionalities, system implementation.
Concerns and perspectives must be put into context as defined by enterprise, functional or technical architectures.
The aim of those maps is to provide reasoned tools for seasoned modellers, helping them in setting milestones, planning journeys, and appraising itineraries.
Milestones are about sequences: they are necessary whenever expectations and commitments are set across different organizational units.
Planning is about projects: once requirements are properly analyzed, maps can be used to sequence goals, set paths, and define tasks gauged according topography metrics.
Appraising is about processes: given sound and objective metrics, tasks traceability to outcomes, and projects built alongside, roadmaps can be turned into development patterns depending on capabilities assessment.
Language
Maps are to be drawn using a standard notation, and for that purpose Caminao uses a kernel of OMG’s Unified Modeling Language.
UML# (for “charpente”, supporting structure in French), is built on a core of UML syntactic constructs, using its stereotyping mechanism to define semantic qualifiers set along functional layers on one hand, OMG’s Model Driven Architecture on the other hand.
UML# objective is therefore not to be a substitute to UML but rather a complement dedicated to requirements and analysis, without affecting continuity with design and implementation models.
Concepts
Neither maps nor languages are meant to convey any guidance about course or discourse. Hence, modeling languages have nothing to say about what is to be represented and how it should be done. For that purpose a reasoned understanding of system functionalities and architecture is required.
Curiously, while core concepts are already at hand, most of methodologies are either aimed at system design, or lean on fallacies about what analysis models represent.
Caminao ultimate objective is therefore to bridge the conceptual gap between functional requirements and system analysis, bringing both semantics under a common roof. To that end, some principles are to be carried through:
Comprehensive scope: concepts must deal with all and every configuration, without assuming any restriction about functional requirements.
Closed set of concepts: all descriptions of system functionalities and architecture must be upheld by a limited and finite number of concepts.
Thorough and reasoned understanding: all stereotypes are to be unambiguously defined using formal expressions built from core concepts.
No expertise or best practices: maps must support all ventures and befit every methodological inclinations. As a consequence concepts and stereotypes must remain neutral and free of any preference or precedence.
Eventually, that should open a new perspective to model driven engineering by consolidating model layers around functional architectures.