Preamble
Rules can be seen as the glue holding together business, organization, and systems, and that may be a challenge for enterprise architects when changes are to be managed according to different concerns and different time-scales. Hence the importance of untangling rules upfront when requirements are captured and analysed.

Primary Taxonomy
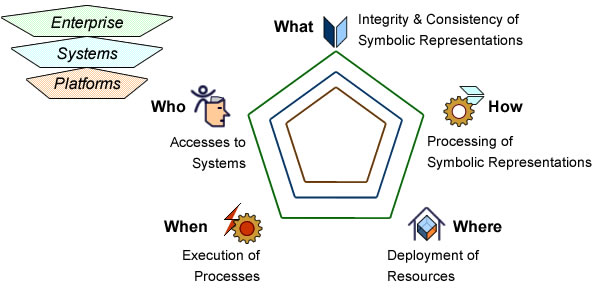
As far as enterprise architecture is concerned, rules can be about:
- Business and regulatory environments.
- Enterprise objectives and organization.
- Business processes and supporting systems.
That classification can be mapped to a logical one:
- Rules set in business or regulatory environments are said to be deontic as they are to be met independently of enterprise governance. They must be enforced by symbolic representations if enterprise systems are to be aligned with environments.
- Rules associated with objectives, organization, processes or systems are said to be alethic (aka modal) as they refer to possible, necessary or contingent conditions as defined by enterprise governance. They are to be directly applied to symbolic representations.
Whereas both are to be supported by systems, the loci will differ: system boundaries for deontic rules (coupling between environment and systems), system components for alethic ones (continuity and consistency of symbolic representations). Given the architectural consequences, rules should be organized depending on triggering (actual or symbolic) and scope (environment or enterprise):
- Actual deontic rules are triggered by actual external events that must be processed synchronously.
- Symbolic deontic rules are triggered by external events that may be processed asynchronously.
- Actual alethic rules are triggered by business processes and must be processed synchronously.
- Symbolic alethic rules are triggered by business processes and can be processed asynchronously.

Footprint
The footprint of a rule is made of the categories of facts to be considered (aka rule domain), and categories of facts possibly affected (aka rule co-domain).
As far as systems are concerned, the first thing to do is to distinguish between actual contexts and symbolic representations. A naive understanding would assume rules to belong to either actual or symbolic realms. Given that the objective of modeling is to decide how the former should be represented by the latter, some grey imprints to be expected and dealt with using three categories of rules, one for each realm and the third set across the divide:
- Rules targeting actual contexts. They can be checked through sensors or applied by actuators. Since rules enforcement cannot be guaranteed on non symbolic artifacts, some rules will have to monitor infringements and proscribed configurations. Example: “Cars should be checked on return from each rental, and on transfer between branches.”
- Rules targeting symbolic representations. Their enforcement is supposedly under the full control of system components. Example: “A car with accumulated mileage greater than 5000 since its last service must be scheduled for service.”
- Rules defining how changes in actual contexts should impact symbolic representations: what is to be considered, where it should be observed, when it should be recorded, how it should be processed, who is to be authorized. Example: ” Customers’ requests at branches for cars of particular models should be consolidated every day.”
That analysis should be carried out as soon as possible because rules set on the divide will determine the impact of requirements on architecture capabilities.
Semantics and Syntax
Rules footprints are charted by domains (what is to be considered) and co-domains (what is to be affected). Since footprints are defined by requirements semantics the outcome shouldn’t be contingent on formats.
From an architecture perspective the critical distinction is between homogeneous and heterogeneous rules, the former with footprint on the same side of the actual/symbolic divide, the latter with a footprint set across.

Contrary to footprints, the shape given to rules (aka format, aka syntax,) is to affect their execution. Assuming homogeneous footprints, four basic blueprints are available depending on the way domains (categories of instances to be valued) and co-domains (categories of instances possibly affected) are combined:
- Partitions are expressions used to classify facts of a given category.
- Constraints (backward rules) are conditions to be checked on facts: [domain].
- Pull rules (static forward) are expressions used to modify facts: co-domain = [domain].
- Push rules (dynamic forward) are expressions used to trigger the modification of facts: [domain] > co-domain.
Anchors & Granularity
In principle, rules targeting different categories of facts are nothing more than well-formed expressions combining homogeneous ones. In practice, because they mix different kinds of artifacts, the way they are built is bound to significantly bear on architecture capabilities.
Systems are tied to environments by anchors, i.e objects and processes whose identity and consistency must be maintained during their life-cycle. Rules should therefore be attached to anchors’ facets as to obtain as fine-grained footprints as possible:

- Features: domain and co-domain are limited to attributes or operations.
- Object footprint: domain and co-domain are set within the limit of a uniquely identified instance (#), including composites and aggregates.
- Connections: domain and co-domain are set by the connections between instances identified independently.
- Collections: domain and co-domain are set between sets of instances and individuals ones, including subsets defined by partitions.
- Containers: domain and co-domain are set for whole systems.
While minimizing the scope of simple (homogeneous) rules is arguably a straightforward routine, alternative options may have to be considered for the transformation of joint (heterogeneous) statements, e.g when rules about functional dependencies may be attached either to (1) persistent representation of objects and associations or, (2) business applications.
Heterogeneous (joint) Footprints
Footprints set across different categories will usually leave room for alternative modeling options affecting the way rules will be executed, and therefore bearing differently on architecture capabilities.
Basic alternatives can be defined according to requirements taxonomy:
- Business requirements: rules set at enterprise level that can be managed independently of the architecture.
- System functionalities: rules set at system level whose support depends on architecture capabilities.
- Quality of service: rules set at system level whose support depends on functional and technical architectures.
- Operational constraints: rules set at platform level whose support depends on technical capabilities.

While that classification may work fine for homogeneous rules (a), it may fall short for mixed ones, functional (b) or not (c). For instance:
- “Gold Customers with requests for cars of particular models should be given an immediate answer.”
- “Technical problems affecting security on checked cars must be notified immediately.”
As requirements go, rules interweaving business, functional, and non functional requirements are routine and their transformation should reflect how priorities are to be sorted out.
Moreover, if rule refactoring is to be carried out, there will be more than syntax and semantics to consider because almost every requirement can be expressed as a rule, often with alternative options. As a corollary, the modeling policies governing the making of rules should be set explicitly.
Sorting Out Mixed Rules
Taking into account that functional requirements describe how systems are meant to support business processes, some rules are bound to mix functional and business concerns. When that’s the case, preferences will have to be set with regard to:
- Events vs Data: should system behavior be driven by changes in business context (as signaled by events from users, devices, or other systems), or by changes in symbolic representations.
- Activities vs Data: should system behavior be governed by planned activities, or by the states of business objects.
- Activities vs Events: should system behavior be governed by planned activities, or driven by changes in business context.
Taking the Gold Customer example, a logical rule (right) is not meant to affect the architecture, but expressed at control level (left) it points to communication capabilities.

The same questions arise for rules mixing functional requirements, quality of service, and operational constraints, e.g:
- How to apportion response time constraints between endpoints, communication architecture, and applications.
- How to apportion reliability constraints between application software and resources at location .
- How to apportion confidentiality constraints between entry points, communication architecture, and locations.
Those questions often arise with non functional requirements and entail broader architectural issues and the divide between enterprise wide and domain specific capabilities.
Further Reading
- Enterprise architecture and Separation of Concerns
- Service Oriented Architectures
- Rules Patterns
- SBVR Case Study







































































