Making Heads or Tails
OMG’s Model Driven Architecture (MDA) is a systems engineering framework set along three model layers:
- Computation Independent Models (CIMs) describe business objects and activities independently of supporting systems.
- Platform Independent Models (PIMs) describe systems functionalities independently of platforms technologies.
- Platform Specific Models (PSMs) describe systems components as implemented by specific technologies.
Since those layers can be mapped respectively to enterprise, functional, and technical architectures, the question is how to make heads or tails of the driving: should architectures be set along model layers or should models organized according architecture levels.

In other words, has some typo reversed the original “architecture driven modeling” (ADM) into “model driven architecture” (MDA) ?
Wrong Spelling, Right Concepts
A confusing spelling should not mask the soundness and relevance of the approach: MDA model layers effectively correspond to a clear hierarchy of problems and solutions:
- Computation Independent Models describe how business processes support enterprise objectives.
- Platform Independent Models describe how systems functionalities support business processes.
- Platform Specific Models describe how platforms implement systems functionalities.

That should leave no room for ambiguity: regardless of the misleading “MDA” moniker, the modeling of systems is meant to be driven by enterprise concerns and therefore to follow architecture divides.
Architectures & Assets Reuse
As it happens, the “MDA” term is doubly confusing as it also blurs the distinction between architectures and processes. And that’s unfortunate because the reuse of architectural assets by development processes is at the core of the MDA framework:
- Business objects and logic (CIM) are defined independently of the functional architectures (PIM) supporting them.
- Functional architectures (PIM) are defined independently of implementation platforms (PSM).
- Technical architecture (PSM) are defined independently of deployment configurations.

Under that perspective the benefits of the “architecture driven” understanding (as opposed to the “model driven” one) appear clearly for both aspects of enterprise governance:
- Systems governance can be explicitly and transparently aligned on enterprise organization and business objectives.
- Business and development processes can be defined, assessed, and optimized with regard to the reuse of architectural assets.
With the relationship between architectures and processes straightened out and architecture reinstated as the primary factor, it’s possible to reexamine the contents of models used as hinges between them.
Languages & Model Purposes
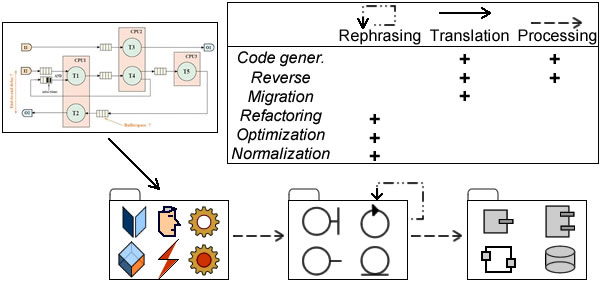
While engineering is not driven by models but by architectures, models do describe architectures. And since models are built with languages, one should expect different options depending on the nature of artifacts being described. Broadly speaking, three basic options can be considered:
- Versatile and general modeling languages like UML can be tailored to different contexts and purposes, along development cycle (requirements, analysis, design) as well as across perspectives (objects, activities, etc) and domains (banking, avionics, etc)
- Non specific business modeling languages like BPM and rules-based languages are meant to be introduced upfront, even if their outcome can be used further down the development cycle.
- Domain specific languages, possibly built with UML, are also meant to be introduced early as to capture domains complexity. Yet, and contrary to languages like BPM, their purpose is to provide an integrated solution covering the whole development cycle.

As seen above for reuse and enterprise architecture, a revised MDA perspective clarifies the purpose of models and consequently the language options. With developments “driven by models”, code generation is the default option and nothing much is said about what should be shared and reused, and why. But with model contents aligned on architecture levels, purposes become explicit and modeling languages have to be selected accordingly, e.g:
- Domain specific languages for integrated developments (PSM-centered).
- BPM for business specifications to be implemented by software packages (CIM-centered).
- UML for projects set across system functional architecture (PIM-centered).
The revised perspective and reasoned association between languages and architectures can then be used to choose development processes: projects that can be neatly fitted into single boxes can be carried out along a continuous course of action, others will require phased development models.
Enterprise Architecture & Engineering Processes
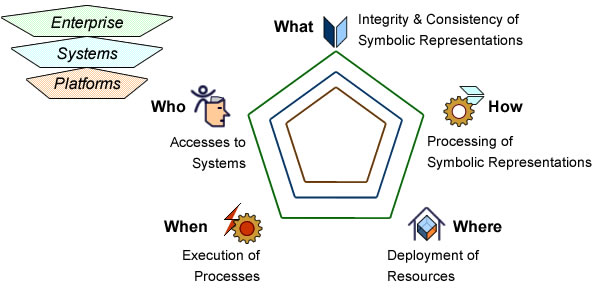
Systems engineering has to meet different kinds of requirements: business goals, system functionalities, quality of service, and platform implementations. In a perfect (model driven engineering) world there would be one stakeholder, one architecture, and one time-frame. Unfortunately, requirements are usually set by different stakeholders, governed by different rationales, and subject to changes along different time-frames. Hence the importance of setting forth the primary factors governing engineering processes:
- Planning: architecture levels (business, systems, platforms) are governed by different time-frames and engineering projects must be orchestrated accordingly.
- Communication: collaboration across organizational units require traceability and transparency.
- Governance: decisions across architecture levels and business units cannot be made upfront and options and policies must be assessed continuously.
Those objectives are best supported when engineering processes are set along architecture levels:

- Requirements: at enterprise level requirements deal with organization and business processes (CIMs). The enterprise requirements process starts with portfolio management, is carried on with systems functionalities, and completed with platforms operational requirements.
- Problems Analysis: at enterprise level analysis deals with symbolic representations of enterprise environment, objectives, and activities (PIMs). The enterprise analysis process starts with the consolidation of symbolic representations for objects (power-types) and activities (scenarii), is carried on with functional architectures, and completed with platforms non-functional features. Contrary to requirements, which are meant to convey changes and bear adaptation (dashed lines), the aim of analysis at enterprise level is to consolidate symbolic representations and guarantee their consistency and continuity. As a corollary, analysis at system level must be aligned with its enterprise counterpart before functional (continuous lines) requirements are taken into account.
- Solutions Design: at enterprise level design deals with operational concerns and resources deployment. The enterprise design process starts with locations and resources, is carried on with systems configurations, and completed with platforms deployments. Part of it is to be supported by systems as designed (PSMs) and implemented as platforms. Yet, as figured by dashed arrows, operational solutions designed at enterprise level bear upon the design of systems architectures and the configuration of their implementation as platforms.
When engineering is driven by architectures, processes can be devised depending on enterprise concerns and engineering contexts. While that could come with various terminologies, the partitioning principles will remain unchanged, e.g:
- Agile processes will combine requirements with development and bypass analysis phases (a).
- Projects meant to be implemented by Commercial-Off-The-Shelf Software (COTS) will start with business requirements, possibly using BPM, then carry on directly to platform implementation, bypassing system analysis and design phases (b).
- Changes in enterprise architecture capabilities will be rooted in analysis of enterprise objectives, possibly but not necessarily with inputs from business and operational requirements, continue with analysis and design of systems functionalities, and implement the corresponding resources at platform level (c).
- Projects dealing with operational concerns will be conducted directly through systems design of and platform implementation (d).

To conclude, when architecture is reinstated as the primary factor, the MDA paradigm becomes a pivotal component of enterprise architecture as it provides a clear understanding of architecture divides and dependencies on one hand, and their relationship with engineering processes on the second hand.
Postscript
MDA illustrates a contrario the straying agenda of the OMG: despite its soundness as a foundation of enterprise architecture as well as its complementarity with the Unified Modeling Language (UML), MDA three-tiers framework has been left unattended, to be replaced by an open-ended (more than two hundred, and counting) hotpotch of amorphous and overlapping meta-models.
Nonetheless, the paradigm is not to be forsaken and can be found behind the Zachman framework and its revamping by Caminao.
https://caminao.blog/wp-content/uploads/2019/01/symbotransfo_pagoda.jpg?w=600
MDA reincarnation as the Pagoda Blueprint
Further Reading
- Model Driven Engineering
- Models, Architectures, perspectives (MAPs)
- Architecture Capabilities
- Enterprise Architecture & Separation of Concerns
- Architecture Driven System Modeling
- The Economics of Reuse
- UML# Manifesto
- Project Management
- Products, Projects, Processes
- Knowledge Based Model Transformation





























































{kind=link}