“Since words are only names for things, it would be more convenient for all men to carry about them such things as were necessary to express a particular business they are to discourse on.”
Jonathan Swift, Gulliver’s Travels
Objective
Modeling languages are meant to support the description of contexts and concerns from specific standpoints. And because those different perspectives have to be mapped against shared references, language must also provide constructs for ironing out variants and factoring out constants.
Ironing out differences in features and behaviors (Erwitt Elliott)
Yet, while most languages generally agree on basic definitions of objects and behaviors, many distinctions are ignored or subject to controversial understanding; such shortcomings might be critical when architecture capabilities are concerned:
Actual entities and their symbolic counterpart.
Actual entities and their roles.
Business logic and business operations
External events and system time.
Architecture Capabilities
As those distinctions set the backbone of functional architectures, languages should be assessed according their ability to express them unambiguously using the least possible set of constructs.
Business objects vs Symbolic Surrogates
As far as symbolic systems are concerned, the primary purpose of models is to distinguish between targets and representations. Hence the first assessment yardstick: modeling languages must support a clear and unambiguous distinction between objects and behaviors of concern on one hand, symbolic system surrogates on the other hand.
A primer on representation: objects of concerns and surrogates
Yet, if objects and behaviors are to be consistently and continuously managed, modeling languages must also provide common constructs mapping identities and structures of actual entities to their symbolic counterpart.
Agents vs Roles
Given that systems are built to support business processes, modeling languages should enable a clear distinction between physical entities able to interact with systems on one hand, roles as defined by enterprise organization on the other hand.
Agents and Roles
In that case the mapping of actual entities to systems representations is not about identities but functionalities: a level of indirection has to be introduced between enterprise organization and system technology because the same roles can be played,simultaneously or successively, by people, devices, or other systems.
Business logic vs Business operations
Just like actual objects are not to be confused with their symbolic description, modeling languages must make a clear distinction between business logic and processes execution, the former defining how to process symbolic objects and flows, the latter with the coupling between process execution and changes in actual contexts. That distinction is of a particular importance if business and organizational decisions are to be made independently of supporting systems technology.
Business logic and operational contingencies
Language constructs must also support the consolidation of functional and operational units, the former being defined by integrity constraints on symbolic flows and roles authorizations on objects and operations, the latter taking into account synchronization constraints between the state of actual contexts and the state of their system symbolic counterpart. And for that purpose languages must support the distinction between external and internal events.
External vs Internal Events
Paraphrasing Albert Einstein, time is what happens between events. As a corollary, external time is what happens between context events, and internal time is what happens between system ones. While both can coincide for single systems and locations, no such assumption should be made for distributed systems set in different locations. In that case modeling language should support a clear distinction between external events signalling changes set in actual locations, and internal events signalling changes affecting system surrogates.
Time scales are set by events and concerns
Along that perspective synchronization is to be achieved through the consolidation of time scales. For single locations that can be done using system clocks, across distributed locations the consolidation will entail dedicated time frames and mechanisms set in reference to some initial external event.
Conclusion: How to share differences across perspectives
Somewhat paradoxically, multiple modeling languages erase differences by paring down shared descriptions to some uniform lump that can be understood by all. Conversely, agreeing on a set of distinctions that should be supported by every language could provide an antidote to the Babel syndrome.
That approach can be especially effective for the alignment of enterprise and systems architectures as the four distinctions listed above are equally meaningful in both perspectives.
Even when code is directly developed from requirements, software engineering can be seen as a process of transformation from a source model (e.g requirements) to a target one (e.g program). More generally, there will be intermediate artifacts with development combining automated operations with tasks involving some decision-making. Given the importance of knowledge management in decision-making, it should also be considered as a primary factor for model transformation.
What has been transformed, added, abstracted ? (Velazquez-Picasso)
Clearing Taxonomy Thickets
Beside purpose, models transformation is often considered with regard to automation or abstraction level.
Classifying transformations with regard to automation is at best redundant, inconsistent and confusing otherwise: on one side of the argument, assuming a “manual transformation” entails some “intelligent design”, it ensues that it cannot be automated; but, on the other side of the argument, if manual operations can be automated, the distinction between manual and automated is pointless. And in any case a critical aspect has been ignored, namely what is the added value of a transformation.
Classifying transformations with regard to abstraction levels is also problematic because, as famously illustrated above, there are too many understandings of what those levels may be. Considering for instance analysis and design models; they are usually meant to deal respectively with system functionalities and implementation. But it doesn’t ensue that the former is more abstract than the latter because system functionalities may describe low-level physical devices and system designs may include high level abstract constructs.
A Taxonomy of Purposes
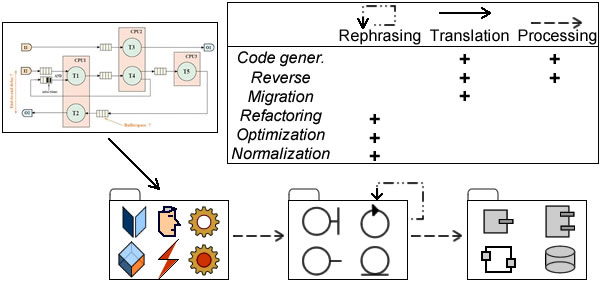
Depending on purpose, model transformation can be set in three main categories:
Translation: source and target models describe the same contents with different languages.
Rephrasing: improvement of the initial descriptions using the same language.
Processing: source and target models describe successive steps along the development process. While they may be expressed with different languages, the objective is to transform model contents.
Translation, Rephrasing, Processing.
Should those different purposes be achieved using common mechanisms, or should they be supported by specific ones ?
A Taxonomy of Knowledge
As already noted, automated transformation is taken as a working assumption and the whole process is meant to be governed by rules. And if purpose is used as primary determinant, those rules should be classified with regard of the knowledge to be considered:
Syntactic knowledge would be needed to rephrase words and constructs without any change in content or language.
Thesaurus and semantics would be employed to translate contents into another language.
Stereotypes, Patterns, and engineering practices would be used to process source models into target ones.
Knowledge with regard to transformation purposes
On that basis, the next step is to consider the functional architecture of transformation, in particular with regard to supporting knowledge.
Procedural vs Declarative KM
Assuming transformation processes devoid of any decision-making, all relevant knowledge can be documented either directly in rules (procedural approach) or indirectly in models (declarative approach).
To begin with, all approaches have to manage knowledge about languages principles (ML) and the modeling languages used for source (MLsrc) and target (MLtrg) models. Depending on language, linguistic knowledge can combine syntactic and semantic layers, or distinguish between them.
Meta-models can be structured along linguistic layers or combine syntax and semantics.
Given exponential growth of complexity, procedural approaches are better suited for the processing of unstructured knowledge, while declarative ones are the option of choice when knowledge is organized along layers.
When applied to model transformation, procedural solutions use tables (MLT) to document the mappings between language constructs, and programs to define and combine transformation rules. Such approaches work well enough for detailed rules targeting specific domains, but fall short when some kind of generalization is needed; moreover, in the absence of distinction at language level (see UML and users’ concerns), any contents differentiation in source models (Msrc) will be blurred in target ones (Mtrg) .
Transformation Policies: Procedural vs Declarative
And filtering out noise appears to be the main challenge of model processing, especially when even localized taints or ambiguities in source models may contaminate the whole of target ones; hence the benefit of setting apart layers of source models according their nature and reliability.
That can be achieved with the modularity of declarative solutions, with transformations carried out separately according the nature of knowledge: syntactic, semantic, or engineering. While declarative solutions also rely on rules, those rules can be managed according to:
Purpose: rephrasing, translation, or development.
Knowledge level: rules about facts, categories, or reasoning.
Robustness: how to deal with incomplete, noisy, or inconsistent models.
Modularity, reusability: how to customize, combine, or generalize transformations.
In principle declarative approaches are generally seen as superior to procedural ones due to the benefits of a clear-cut separation between the different domains of knowledge on one hand, and the programs performing the transformations on the other hand:
The complexity of transformations increases exponentially with the number of rules, independently of the corpus of knowledge.
The ensuing spaghetti syndrome rapidly downgrades transparency, traceability, and reliability of rules which, in procedural approaches, are the only gate to knowledge itself.
Adding specific rules in order to deal with incomplete or inconsistent models significantly degrades modularity and reusability, with the leveraging impact of new rules having to be added for every variant.
In practice the flaws of procedural approaches can be partially curbed providing that:
Rules apply to a closely controlled domain.
Models are built with complete, unambiguous and consistent languages.
Both conditions can be met with domain specific languages (DSLs) and document based ones (e.g XML) targeting design and program models within well-defined business domains.
Compared with the diversity and specificity of procedural solutions, the extent of declarative ones have been checked by their more theoretically demanding requirements, principally met by relational models. Yet, the Model Driven Architecture (MDA) distinction between computation independent (CIMs), platform independent (PIMs), and platform specific (PSMs) models could provide the basis for a generalization of knowledge-based model transformation.
Rules can be seen as the glue holding together business, organization, and systems, and that may be a challenge for enterprise architects when changes are to be managed according to different concerns and different time-scales. Hence the importance of untangling rules upfront when requirements are captured and analysed.
How to outline the architectural footprint of rules (John Devlin)
Primary Taxonomy
As far as enterprise architecture is concerned, rules can be about:
Business and regulatory environments.
Enterprise objectives and organization.
Business processes and supporting systems.
That classification can be mapped to a logical one:
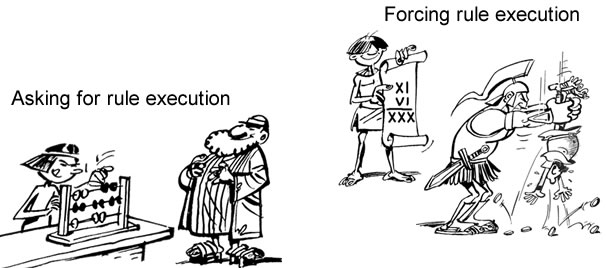
Rules set in business or regulatory environments are said to be deontic as they are to be met independently of enterprise governance. They must be enforced by symbolic representations if enterprise systems are to be aligned with environments.
Rules associated with objectives, organization, processes or systems are said to be alethic (aka modal) as they refer to possible, necessary or contingent conditions as defined by enterprise governance. They are to be directly applied to symbolic representations.
Whereas both are to be supported by systems, the loci will differ: system boundaries for deontic rules (coupling between environment and systems), system components for alethic ones (continuity and consistency of symbolic representations). Given the architectural consequences, rules should be organized depending on triggering (actual or symbolic) and scope (environment or enterprise):
Actual deontic rules are triggered by actual external events that must be processed synchronously.
Symbolic deontic rules are triggered by external events that may be processed asynchronously.
Actual alethic rules are triggered by business processes and must be processed synchronously.
Symbolic alethic rules are triggered by business processes and can be processed asynchronously.
Rules should be classified upfront with regard to triggering (actual or symbolic) and scope (environment or enterprise)
Footprint
The footprint of a rule is made of the categories of facts to be considered (aka rule domain), and categories of facts possibly affected (aka rule co-domain).
As far as systems are concerned, the first thing to do is to distinguish between actual contexts and symbolic representations. A naive understanding would assume rules to belong to either actual or symbolic realms. Given that the objective of modeling is to decide how the former should be represented by the latter, some grey imprints to be expected and dealt with using three categories of rules, one for each realm and the third set across the divide:
Rules targeting actual contexts. They can be checked through sensors or applied by actuators. Since rules enforcement cannot be guaranteed on non symbolic artifacts, some rules will have to monitor infringements and proscribed configurations. Example: “Cars should be checked on return from each rental, and on transfer between branches.”
Rules targeting symbolic representations. Their enforcement is supposedly under the full control of system components. Example: “A car with accumulated mileage greater than 5000 since its last service must be scheduled for service.”
Rules defining how changes in actual contexts should impact symbolic representations: what is to be considered, where it should be observed, when it should be recorded, how it should be processed, who is to be authorized. Example: ” Customers’ requests at branches for cars of particular models should be consolidated every day.”
Rules & Capabilities
That analysis should be carried out as soon as possible because rules set on the divide will determine the impact of requirements on architecture capabilities.
Semantics and Syntax
Rules footprints are charted by domains (what is to be considered) and co-domains (what is to be affected). Since footprints are defined by requirements semantics the outcome shouldn’t be contingent on formats.
From an architecture perspective the critical distinction is between homogeneous and heterogeneous rules, the former with footprint on the same side of the actual/symbolic divide, the latter with a footprint set across.
Homogeneous vs Heterogeneous footprints
Contrary to footprints, the shape given to rules (aka format, aka syntax,) is to affect their execution. Assuming homogeneous footprints, four basic blueprints are available depending on the way domains (categories of instances to be valued) and co-domains (categories of instances possibly affected) are combined:
Partitions are expressions used to classify facts of a given category.
Constraints (backward rules) are conditions to be checked on facts: [domain].
Pull rules (static forward) are expressions used to modify facts: co-domain = [domain].
Push rules (dynamic forward) are expressions used to trigger the modification of facts: [domain] > co-domain.
Pull vs Push Rule Management
Anchors & Granularity
In principle, rules targeting different categories of facts are nothing more than well-formed expressions combining homogeneous ones. In practice, because they mix different kinds of artifacts, the way they are built is bound to significantly bear on architecture capabilities.
Systems are tied to environments by anchors, i.e objects and processes whose identity and consistency must be maintained during their life-cycle. Rules should therefore be attached to anchors’ facets as to obtain as fine-grained footprints as possible:
Anchors’ facets
Features: domain and co-domain are limited to attributes or operations.
Object footprint: domain and co-domain are set within the limit of a uniquely identified instance (#), including composites and aggregates.
Connections: domain and co-domain are set by the connections between instances identified independently.
Collections: domain and co-domain are set between sets of instances and individuals ones, including subsets defined by partitions.
Containers: domain and co-domain are set for whole systems.
While minimizing the scope of simple (homogeneous) rules is arguably a straightforward routine, alternative options may have to be considered for the transformation of joint (heterogeneous) statements, e.g when rules about functional dependencies may be attached either to (1) persistent representation of objects and associations or, (2) business applications.
Heterogeneous (joint) Footprints
Footprints set across different categories will usually leave room for alternative modeling options affecting the way rules will be executed, and therefore bearing differently on architecture capabilities.
Business requirements: rules set at enterprise level that can be managed independently of the architecture.
System functionalities: rules set at system level whose support depends on architecture capabilities.
Quality of service: rules set at system level whose support depends on functional and technical architectures.
Operational constraints: rules set at platform level whose support depends on technical capabilities.
Rules do not necessarily fit into clear requirements taxonomy
While that classification may work fine for homogeneous rules (a), it may fall short for mixed ones, functional (b) or not (c). For instance:
“Gold Customers with requests for cars of particular models should be given an immediate answer.”
“Technical problems affecting security on checked cars must be notified immediately.”
As requirements go, rules interweaving business, functional, and non functional requirements are routine and their transformation should reflect how priorities are to be sorted out.
Moreover, if rule refactoring is to be carried out, there will be more than syntax and semantics to consider because almost every requirement can be expressed as a rule, often with alternative options. As a corollary, the modeling policies governing the making of rules should be set explicitly.
Sorting Out Mixed Rules
Taking into account that functional requirements describe how systems are meant to support business processes, some rules are bound to mix functional and business concerns. When that’s the case, preferences will have to be set with regard to:
Events vs Data: should system behavior be driven by changes in business context (as signaled by events from users, devices, or other systems), or by changes in symbolic representations.
Activities vs Data: should system behavior be governed by planned activities, or by the states of business objects.
Activities vs Events: should system behavior be governed by planned activities, or driven by changes in business context.
Taking the Gold Customer example, a logical rule (right) is not meant to affect the architecture, but expressed at control level (left) it points to communication capabilities.
How to express Gold customers’ rule may or may not point to communication capabilities.
The same questions arise for rules mixing functional requirements, quality of service, and operational constraints, e.g:
How to apportion response time constraints between endpoints, communication architecture, and applications.
How to apportion reliability constraints between application software and resources at location .
How to apportion confidentiality constraints between entry points, communication architecture, and locations.
Those questions often arise with non functional requirements and entail broader architectural issues and the divide between enterprise wide and domain specific capabilities.
The past is not dead. In fact, it’s not even past. –
William Faulkner
Objective
Retrieving legacy code has something to do with archaeology as both try to retrieve undocumented artifacts and understand their initial context and purpose. The fact that legacy code is still well alive and kicking may help to chart their structures and behaviors, but it may also confuse the rationale of initial designs.
Legacy Artifact: Was the bowl intended for turkeys ? at thanksgiving ? Why the worm ?
Hence the importance of traceability and the benefits of a knowledge based approach to modernization organized along architecture layers (enterprise, systems, platforms), and processes (business, engineering, supporting services).
Model Driven Modernization
Assuming that legacy artifacts under consideration are still operational (otherwise re-engineering would be pointless), modernization will have to:
Pinpoint the deployed components under consideration (a).
Identify the application context of their execution (b).
Chart their footprint in business processes (c).
Define the operational objectives of their modernization (d).
Sketch the conditions of their (re)engineering (e) and the possible integration in the existing functional architecture (f).
Plan the re-engineering project (g).
Modernization Road Map
Those objectives will usually not be achieved in a big bang, wholly and instantly, but progressively by combining increments from all perspectives. Since the different outcomes will have to be managed across organizational units along multiple engineering processes, modernization would clearly benefit from a model based approach, as illustrated by MDA modeling layers:
Platform specific models (PSMs) should be used for collecting legacy artifacts and mapping them to their re-engineered counterparts.
Since platform independent models (PIMs) are meant to describe system functionalities independently of implementations, they should be used to consolidate the functionalities of legacy and re-engineered artifacts.
Since computation independent models (CIMs) are meant to describe business processes independently of supporting systems, they should be used to reinstate, document, and validate re-engineered artifacts within their business context.
Model Driven Modernization
Corresponding phases can be expressed using the archaeology metaphor: field survey and collection (>PSMs), analysis (PSMs/PIMs), and reconstruction (CIMs/PIMs).
Field Survey
The objective of a field survey is to circumscribe the footprint of the modernization and collect artifacts under consideration:
Given targeted business objects or activities, the first step is to collect information about locations, distribution and execution dependencies.
Sites can then be searched and executable files translated into source ones whose structure and dependencies can be documented.
The role of legacy software can then be defined with regard to the application landscape .
Analysis (with regard to presentation, control, persistency, and services)
It must be noted that field survey and collection deal with the identification and restoration of legacy objects without analyzing their contents.
Analysis
The aim of analysis is to characterize legacy components, first with regard to their architectural features, then with regard to functionalities. Basic architectural features take into account components’ sharing and life-cycle.
The analysis of functionalities can be achieved locally or at architecture level:
Local analysis (a) directly map re-factored applications to specific business requirements, by-passing functional architecture. That’s the case when targeted applications can be isolated, e.g by wrapping legacy code.
Global analysis (b) consolidate newly supported applications with existing ones within functional architecture, possibly with new functionalities.
Analysis (with regard to presentation, control, persistency, and services)
It must be noted that the analysis of legacy components, even when carried out at functional architecture level, takes business processes as they are.
Reconstruction
The aim of reconstruction is to set legacy refactoring within the context of enterprise architecture. That should be done from operational and business perspectives:
As the primary rationale of modernization is to deal with operational problems or bottlenecks, its benefits should be fully capitalized at enterprise level.
Re-factored applications usually make room for improvements of users’ experience; that may bring about further changes in organization and business processes.
Reconstruction
Hence, modernization is not complete until potential benefits of re-factored applications are considered, for business processes as well as for functional architecture.
From Workshops to Workflow
As noted above, modernization can seldom be achieved in a big bang and should be planned as a model based engineering process. Taking a leaf from the MDA book, such a process would be organized across four workshops:
Technical architecture (deployment models): that’s where legacy components are collected, sorted, and documented.
Software architecture (platform specific models): where legacy components are put in local context.
Functional architecture (platform independent models): where legacy components are put in shared context.
Enterprise architecture (computation independent models): where legacy components are put into organizational context.
Modernization & MBSE Workshops
Those workshops would be used to manage the outcomes of the modernization workflow:
Collect and organize legacy code; translate into source files.
Document legacy components.
Build PSMs according basic architecture functional patterns.
Contrary to its manufacturing cousin, a long time devotee of preventive policies, software engineering is still ambivalent regarding the benefits of integrating quality management with development itself. That certainly should raise some questions, as one would expect the quality of symbolic artifacts to be much easier to manage than the one of their physical counterparts, if for no other reason than the former has to check symbolic outcomes against symbolic specifications while the latter must also to overcome the contingencies of non symbolic artifacts.
Walking Quality Hall (E. Erwitt)
Thanks to agile approaches, lessons from manufacturing are progressively learned, with lean and just-in-time principles making tentative inroads into software engineering. Taking advantage of the homogeneity of symbolic development flows, agile methods have forsaken phased processes in favor of iterative ones, making a priority of continuous and value driven deliveries to business users. Instead of predefined sequences of dedicated tasks, products are developed through iterations regrouping definition, building, and acceptance into the same cycles. That push differentiated documentation and models on back seats and may also introduce a new paradigm by putting tests on driving ones.
From Phased to Iterative Tests Management
Traditional (aka phased) processes follow a corrective strategy: tests are performed according a Last In First Out (LIFO) framework, for components (unit tests), system (integration), and business (acceptance). As a consequence, faults in functional architecture risk being identified after components completion, and flaws in organization and business processes may not emerge before the integration of system functionalities. In other words, the faults with the more wide-ranging consequences may be the last to be detected.
Phased and Iterative approaches to tests
Iterative approaches follow a preemptive strategy: the sooner artifacts are tested, the better. The downside is that without differentiated and phased objectives, there is a question mark on the kind of specifications against which software products are to be tested; likewise, the question is how results are to be managed across iteration cycles, especially if changing requirements are to be taken into account.
Looking for answers, one should first consider how requirements taxonomy can support tests management.
Requirements Taxonomy and Tests Management
Whatever the methods or forms (users’ stories, use case, functional specifications, etc), requirements are meant to describe what is expected from systems, and as such they have two main purposes: (1) to serve as a reference for architects and engineers in software design and (2) to serve as a reference for tests and acceptance.
With regard to those purposes, phased development models have been providing clearly defined steps (e.g requirements, analysis, design, implementation) and corresponding responsibilities. But when iterative cycles are applied to progressively refined requirements, those “facilities” are no longer available. Nonetheless, since tests and acceptance are still to be performed, a requirements taxonomy may replace phased steps as a testing framework.
Taxonomies being built on purpose, one supporting iterative tests should consider two criteria, one driven by targeted contents, the other by modus operandi:
With regard to contents, requirements must be classified depending on who’s to decide: business and functional requirements are driven by users’ value and directly contribute to business experience; non functional requirements are driven by technical considerations. Overlapping concerns are usually regrouped as quality of service.
Requirements with regard to Acceptance.
That distinction between business and architecture driven requirements is at the root of portfolio management: projects with specific business stakeholders are best developed with the agile development model, architecture driven projects set across business domains may call for phased schemes.
That requirements taxonomy can be directly used to build its testing counterpart. As developed by D. Leffingwell (see selected readings), tests should also be classified with regard to their modus operandi, the distinction being between those that can be performed continuously along development iterations and those that are only relevant once products are set within their technical or business contexts. As it happens, those requirements and tests classifications are congruent:
Units and component tests (Q1) cover technical requirements and can be performed on development artifacts independently of their functionalities.
Functional tests (Q2) deal with system functionalities as expressed by users (e.g with stories or use cases), independently of operational or technical considerations.
System acceptance tests (Q3) verify that those functionalities, when performed at enterprise level, effectively support business processes.
System qualities tests (Q4) verify that those functionalities, when performed at enterprise level, are supported by architecture capabilities.
Tests Matrix for target and MO (adapted from D. Leffingwell).
Besides the specific use of each criterion in deciding who’s to handle tests, and when, combining criteria brings additional answers regarding automation: product acceptance should be performed manually at business level, preferably by tools at system level; tests performed along development iterations can be fully automated for units and components (black-box), but only partially for functionalities (white-box).
That tests classification can be used to distinguish between phased and iterative tests: the organization of tests targeting products and systems from business (Q3) or technology (Q4) perspectives is clearly not supposed to be affected by development models, phased or iterative, even if resources used during development may be reused. That’s not the case for the organization of the tests targeting functionalities (Q2) or components (Q1).
Iterative Tests
Contrary to tests aiming at products and systems (Q3 and Q4), those performed on development artifacts cannot be set on fixed and well-defined specifications: being managed within iteration cycles they must deal with moving targets.
Unit and components tests (Q1) are white-box operations meant to verify the implementation of functionalities; as a consequence:
They can be performed iteratively on software increments.
They must take into account technical requirements.
They must be aligned on the implementation of tested functionalities.
Iterative (aka development) tests for technical (Q1) and functional (Q2) requirements.
Hence, if unit and component tests are to be performed iteratively, (1) they must be set against features and, (2) functional tests must be properly documented and available for reuse.
Functional tests (Q2) are black-box operations meant to validate system behavior with regard to users’ expectations; as a consequence:
They can be performed iteratively on software increments.
They don’t have to take into account technical requirements.
They must be aligned on business requirements (e.g users’ stories or use cases).
Assuming (see previous post) a set of stories (a,b,c,d) identified by alternative paths built from features (f1…5), functional tests (Q2) are to be defined and performed for each story, and then reused to test the implementation of associated features (Q1).
Functional tests are set along stories, units and components tests are set along features.
At that point two questions must be answered:
Given that stories can be changed, expanded or refined along development iterations, how to manage the association between requirements and functional tests.
Given that backlogs can be rearranged along development cycles according to changing priorities, how to update tests, manage traceability, and prevent regression.
With model-driven approaches no longer available, one should consider a mirror alternative, namely test-driven development.
Tests Driven Development
Test driven development can be seen as a mirror image of model driven development, a somewhat logical consequence considering the limited role of models in agile approaches.
The core of agile principles is to put the definition, building and acceptance of software products under shared ownership, direct collaboration, and collective responsibility:
Shared ownership: a project team groups users and developers and its first objective is to consolidate their respective concerns.
Direct collaboration: decisions are taken by team members, without any organizational mediation or external interference.
Collective responsibility: decisions about stories, priorities and refinements are negotiated between team members from both sides of the business/system (or users/developers) divide.
Assuming those principles are effectively put to work, there seems to be little room for organized and persistent documentation, as users’ stories are meant to be developed, and products released, in continuity, and changes introduced as new stories.
With such lean and just-in-time processes, documentation, if any, is by nature transient, falling short as a support of test plans and results, even when problems and corrections are formulated as stories and managed through backlogs. In such circumstances, without specifications or models available as development handrails, could that be achieved by tests ?
Given the ephemeral nature of users’ stories, functional tests should take the lead.
To begin with, users’ stories have to be reconsidered. The distinction between functional tests on one hand, unit and component tests on the other hand, reflects the divide between business and technical concerns. While those concerns may be mixed in users’ stories, they are progressively set apart along iteration cycles. It means that users’ stories are, by nature, transitory, and as a consequence cannot be used to support tests management.
The case for features is different. While they cannot be fully defined up-front, features are not transient: being shared by different stories and bound to system functionalities they are supposed to provide some continuity. Likewise, notwithstanding their changing contents, users’ stories should be soundly identified by solution paths across problems space.
Paths and Features can be identified consistently along iteration cycles.
That can provide a stable framework supporting the management of development tests:
Unit tests are specified from crosses between solution paths (described by stories or scenarii) and features.
Functional tests are defined by solution paths and built from unit tests associated to the corresponding features.
Component tests are defined by features and built by the consolidation of unit tests defined for each targeted feature according to technical constraints.
The margins support continuous and consistent identification of functional and component tests whose contents can be extended or updated through changes made to unit tests.
One step further, and tests can even be used to drive iteration cycles: once features and solution paths soundly identified, there is no need to swell backlogs with detailed stories whose shelf life will be limited. Instead, development processes would get leaner if extensions and refinements could be directly expressed as unit tests.
System Quality and Acceptance Tests
Contrary to development tests which are applied iteratively to programs, system tests are applied to released products and must take into account requirements that cannot be directly or uniquely attached to users stories, either because they cannot be expressed from a business perspective or because they are shared concerns and best described as features. Tests for those requirements will be consolidated with development ones into system quality and acceptance tests:
System Quality Tests deal with performances and resources from the system management perspective. As such they will combine component and functional tests in operational configurations without taking into account their business contents.
System Acceptance Tests deal with the quality of service from the business process perspective. As such they will perform functional tests in operational configurations taking into account business contents and users’ experience.
Development Tests are to be consolidated into Product and System Acceptance Tests.
Requirements set too early and quality checks performed too late are at the root of phased processes predicaments, and that can be fixed with a two-pronged policy: a preemptive policy based upon a requirements taxonomy organizing problem spaces according concerns business value, system functionalities, components designs, platforms configuration; a corrective policy driven by the exploration of solution paths, with developments and releases driven by quality concerns.
Tests & Framework
Insofar as large and complex enterprise architectures are concerned, it’s safe to assume that different development models (agile or phased) and tests policies (unit, system, acceptance, …) will have to be cohabit, and that would not be possible without an architecture framework:
Development or unit tests are defined at platform level and applied to software components.
Integration or system tests are defined at system level and built from tested components.
Acceptance tests are defined at enterprise level and built from tested functionalities.
Development processes start with requirements and wind up in code; in between there isn’t much of a consensus among the software engineering community about how to define the scope (spaces), how to sequence the tasks (paths), and how to time deliveries (paces). On one side of the debate phased approaches hope for fixed spaces and ordered paths but often get entangled in moving lines. On the other side of the debate agile teams try to find their space by increments but risk losing the path while still on their way.
Maze revisited: finding a path while building the space (Ibrahim El-Salahi)
This lack of agreed upon concepts and principles entrusts personal skills and best practices as primary success factors. Conversely, that could explain the rate of failures for software projects, significantly higher than for “hard” engineering ones; given the quasi absence of physical constraints, the opposite would have been expected, which would suggest some critical intrinsic flaw.
With the “benefits” of hindsight and agile assessment of waterfall flaws, the focus has been put on fixed scope and schedule, in particular with regard to requirements and quality management:
Fixed requirements set upfront: since there is an inverse relationship between the level of details and the reliability and stability of requirements, staking the whole project on requirements fully defined at such an early time is arguably a very hazardous policy.
Quality as an afterthought: given that finding defects is not very gratifying when undertaken in isolation, delegating the task will offer few guarantees if not associated with rewards commensurate to findings; moreover, quality as a detached concern may easily turn into a collateral damage when set along mounting costs and scheduling constraints. Alternatively, quality checks may change into a more positive endeavor when conducted as an intrinsic part of development.
Agile answer to those failings has been to conduct specifications, development, and quality assurance into integrated iterations. As a consequence, the definition of scope becomes a byproduct of development cycles, with requirements itemized as features in order to be developed progressively. Moreover, with specifications and schedules managed dynamically, timetables become impracticable and deliveries can only be carried out by shuttles.
The agile “reformation” has open new perspectives and beget many fruitful practices, and the objective here is to see how those approaches of scope and schedule can be reformulated within the perspective of architecture layers. This part examines the congruence between the alternate flows of use cases and the backlog of users’ stories, and considers their complementarity as path-finders. The second part will focus on the role of time-boxes as pace-makers and the benefits for quality assurance.
Architectures and Projects Scope
Whatever the compass, agile or phased, projects footprint can be set across three architecture layers:
Enterprise architectures describe business environments and objectives, resources and regulatory constraints.
System architectures describe enterprises in terms of functional entities of human agents and physical and software assets.
Technical architectures describe the platforms supporting functional entities.
Architecture layers vs Processes
Projects are meant to carry out changes within architectures initiated by business, engineering, or services management processes:
Business processes are defined by business environment and objectives. Changes may have to deal with domains and activities, organization and supported operations, and quality of service as experienced by users.
Engineering processes focus on the development of software systems supporting business processes: business domains and applications, system functionalities, platform implementations.
Services management stand between engineering deliveries and operational concerns: location of assets, access to services, releases deployment, and systems configuration.
While development projects may (and will usually) cross architecture layers, their roots and stakes should nonetheless be clearly positioned if projects are to be planned within the respective time-spans, governed by the relevant authority, and their products accepted by the right stakeholders.
Development Project, from Requirements to Deployments
That put projects governance at crossroads between (a) business objectives set by market opportunities, (b) the deployment of features into functional architectures, and (c) the deployment of releases according to changes in technical architecture. With phased developments, scope and schedules are fixed upfront, which means that the business layer forces its time-frame over the ones of system and technical layers, which may introduce frictions regarding scope as well as quality:
With regard to scope, frictions stem from features and schedules set fully and definitively at enterprise level, independently of any feedback from functional and technical layers.
With regard to quality, frictions stem from tests performed at technical layer when scope and schedules can no longer be revised in case of negative outcomes.
The consequences are all too easy to observe, with business needs partially satisfied and software quality sacrificed. Hence the need of a balanced approach that would consolidate the different maps and time-frames in order to minimize frictions between layers.
Mapping Project Scope
Projects scope can be described along two dimensions, one set by business logic, the other by system functionalities:
First, one have to circumscribe the business variants to be taken into consideration. For that purpose the project footprint, first introduced as users’ stories, will have to be documented by activity or business process diagrams.
Then, the project scope will have to mark out the subset of business requirements to be supported by system functionalities. That will usually be done with use cases describing interactions between system and users.
Complementary descriptions of projects footprints: use cases (interactions between users and system) and activity diagrams (business logic).
That makes those descriptions both orthogonal and complementary: orthogonal because use cases cut across activity diagrams, complementary because use cases are meaningless without targeted activities.
More importantly, they are associated with different architecture layers and governed by different concerns:
At business level (business processes or activities), the perimeter and granularity of requirements must be congruent with the continuity and consistency constraints of business objects and operations.
At functional level (use cases), the span and granularity of interactions between system and users must coincide with execution paths. But the rationale governing users interactions is not the same as the one governing the integrity of business processes. As a consequence, the paths considered for development may pick sequences of operations defined by business processes but should not define them anew based upon interaction constraints.
Finally, assuming that use cases see systems as black-boxes, their footprint should not depend on decisions taken at technical level.
Those concerns can be dealt with separately if projects scope is explored iteratively, e.g using activity diagrams for business logic and use case diagrams for users interactions.
Iterative Mapping of Project Footprint
Iterative development is not just about increments but, first and foremost, about exploring development spaces. That is especially useful when projects overlap architecture layers and cannot rely on fully fledged requirements.
Such projects have to deal with two challenges:
They must identify and manage work units according to the state of requirements and the nature of dependencies (business, organization, or technology, …).
They must carry on with developments based on incomplete specifications while exploring alternatives and deferring decisions until the “last responsible moment” when further delay would limit the options at hand.
Taking a leaf out of the agile book, projects should be driven by users’ value, with requirements first introduced as users’ stories. From that springboard, as informal and incomplete as could be, stories must be fleshed out and organized in order to support the reasoned exploration of project scope.
At inception stories are no more than a user, an objective, and an activity, all set at business level independently of the part played by systems. Scope exploration must therefore begin with activities backbone and be furthered with variants, aka scenarii.
Adding execution paths to project scope
Given a set of business scenarii, the candidates for system support must be ordered and mapped to system features, actual or planned. That should provide a blueprint for development paths. Unfortunately, as variants are added to plots, narratives can easily turn messy, mixing features and capabilities across architecture layers. And that’s where the benefits of use cases are to be found.
Development Paths: From Users’ Stories to Use Cases
Whatever the context, iterations are formal constructs defined by invariants, increments, and exit conditions. When applied to development spaces, iterations are defined by:
Invariants: conditions on architectural assets supporting the scenario under consideration.
Increments: features or variants added to scenarii.
Exit condition: no more features or variants (empty backlog) or time-out.
Applied to architecture layers, invariants provide for reasoned iterations and backlogs:
Enterprise layer are the first to be considered: cycles are set for persistency and execution units and bound by domains (identification mechanisms, integrity constraints, and semantics); within cycles, increments target attributes, operations and variants.
Functional layer come second: cycles are set for interaction units (aka use cases), and bound by the continuity and consistency business objects and activities; increments target transient attributes and operations.
Technical layer come last: cycles are set for platforms and bound by functional units.
But there is a catch: while users’ stories and activity (or business process) diagrams are set at enterprise level, development projects are considered at system level; because systems functionalities are not supposed to appear in users’ stories or activity diagrams, there could be a gap between business and functional requirements. As it happens, use cases provide a bridge: on one hand they focus on the interactions between users and systems, on the other hand their basic and alternate flows can be directly mapped to the paths in activity diagrams.
From alternative flows to Development Paths
That provides a clear and sound basis for the definition of development paths: on one hand alternate flows can be ranked according users’ priorities; on the other hand they determine the sequence of use cases that will have to be developed.
Backlogs and Pathfinders
While the objective of users’ stories is to tie up projects in business value, the objective of use cases is to anchor them in the context of system functionalities. That perspective, and the role of models, may be ignored for standalone projects, but it is necessary when project development paths are to be governed both by business and functional dependencies, described respectively by users’ stories and use cases.
In that case the exploration of development paths should be guided by invariants set along MDA model layers: computation independent (business processes), platform independent (systems functionalities), and platform specific (technology platforms).
Projects are rooted in use cases but development paths are governed by users’ stories.
When projects are rooted in business activities (a), e.g the possibility of upgrading a customer, stories describe execution paths and are ranked according business priorities. Iterations will proceed with development and new cycles added for alternative paths to the basic one.
Depending on context dependencies, development projects can be directly initiated from given sequences of activities (b) or conducted in parallel with users’ stories. Use cases remain the option of choice when the features supporting users’ stories are meant to be shared (e.g checkout). In that case the development paths are governed both by users’ value and functional dependencies. When features are deemed specific (e.g upgrade), use cases can be bypassed and development paths explored simultaneously according users’ and development concerns.
Backlog organization is more complex when development paths cross the divide between functional and technical concerns. Ideally, one would expect a clear separation of concerns, with use cases defined independently of technical options, just like business logic doesn’t depend on system functionalities. But alternatives may be blurred due to the dependencies between interactions design and platform capabilities, the risk being to associate technical options with functional variants, e.g specialized use cases.
Entangled development paths: self check out depends on technical platform.
That’s the case when features can only be implemented on specific platforms. If those features are also specific the corresponding development cycle can be managed as a whole. Otherwise the relevant decisions should be factored out. The same principle applies for features supporting different business processes.
Squaring the Circles: From Epics to Releases
Iterations run within boundaries set by invariants, and with regard to projects scope, those invariants are set by architecture capabilities: enterprise on one hand, systems on the other hand.
From the enterprise perspective, development projects (b) are meant to support business objectives (a), not to define them. As a consequence, users’ stories must remain within borders set upfront. That can be achieved by introducing business projects (aka strategies, aka epics) and portfolios of development ones.
Development Paths: Portfolio of business objectives (a), associated backlogs of users’ stories (b), targeted features (c), architectural capabilities (d), and releases (e).
From the system perspective, a clear distinction should be maintained between projects supported by platforms capabilities (b), and projects targeting platforms capabilities (d). Eventually, those different levels of explorations will have to be consolidated as releases (e), and that is where one may find the agile answer to waterfall.
A Time for Every Purpose: Time-boxes as Pace-Makers
As Einstein famously said, “The only reason for time is so that everything doesn’t happen at once.” In other words time is what happens between events, and the use of a single time-frame will put all events under the same rationale.
But architectures are best understood as shearing layers whose events are governed by different rationales, respectively: business opportunities, engineering constraints, or operational needs.
That is arguably the critical flaw of waterfall solutions as they force business, development, and operations under the same set of strictures. And that’s why agile’s solution to components release may be its pivotal innovation as it establishes the autonomy of those three layers and introduces time-boxes as their pace-makers.
As previously noted, embarking for sizable and lengthy project on the assumption that detailed scope and schedules can be set upfront is a very hazardous policy. Alternatively, agile development models carry out specifications, development, and quality assurance into integrated iterations, making room for a progressive exploration of problem spaces and solution paths, and consequently for informed decision-making and better risk management.
Paths & Paces (S.Dali)
Yet, whatever the method, at some point, scope and features will have to be committed; and with targeted features set dynamically, planned schedules are no more an option. Hence the need to reconsider the way time is taken into account.
Dependencies: Playing for Time
Paraphrasing Einstein, one may say that the only reason for processes is so that everything doesn’t happen at once. Why is that ?
First, processes are meant to support informed decisions. If problem spaces and solution paths cannot be settled upfront they must be done progressively. And that will clearly introduce informational dependencies supporting:
Decisions about what is to be done: alternative paths and their priorities
Decisions about how it should be done: supported features and their priorities
Decisions about how it can be done: quality assurance and acceptance.
In that context the objective of development processes is to do as much of definition, building, and acceptance, and to delay decisions in order to gather the most of the relevant information until the “last responsible moment”, i.e without preempting any of the initial set of alternative options.
Assuming informed decisions are supported by architecture knowledge, processes must take into account engineering constraints regarding:
Technical dependencies associated to the nature of development flows and environments.
Functional dependencies associated to products functionalities and supporting systems.
Organizational dependencies associated to business units and localization.
Iterating across architecture layers
While those dependencies are defined within architecture layers, their impact on the organization of work units may have to be consolidated when projects are carried out across layers.
Schedules: Running for Time
Whether development cycles stay within or run across architecture layers, there will be no way to decide about deliveries and schedules at project inception. In other words dependencies will have to be sorted out and planning settled along the road.
Project planning means consolidating overlapping time-frames. That may not be a problem for projects set within single architecture layers (e.g migration), but that should definitively be taken into account when heterogeneous time-frames govern changes across architecture layers. With regard to changes managed at project level (endogenous events), the consolidation may be done within project time-frame; but that will not be possible for changes occurring in non managed environments (exogenous events).
Those events are set in time-frames governed by their own rationale (e.g business, organization, or technology) that cannot be subsumed into the engineering timetable:
At enterprise level, time is set by business context. Both business objectives and business process solutions are meant to be decided with regard to actual (aka exogenous) business opportunities (a).
At system level, time is set by project planning (endogenous events). Given functional requirements (e.g users’ stories or use cases), architects and designers have to decide about the scheduling of systems functionalities and services, and the release of corresponding applications. Since those decisions are not directly exposed to exogenous events, they can be made according to engineering constraints and resources availability (b).
At platform level, time is set by business and operational objectives (endogenous events), and technical contexts (exogenous events). Assuming that risks are evenly set, the problem is to align endogenous (managed by project) with exogenous (anticipated from contexts) events: too early releases may preclude later but more useful ones; too late releases may hamper operations (c).
The texture of time differs across architecture layers (yellow for endogenous, red for exogenous)
Whereas those time-scales are to be synchronized, there is no reason they would be congruent. Hence the need of some mechanism, static (e.g milestones) or dynamic (e.g backlogs) supporting the scheduling of work units.
From Milestones to Backlogs
As considered elsewhere, phased models of development may offer some benefits when dependencies originate from different environments or involve different authorities; yet they may impose still bigger penalties when requirements cannot be fully settled upfront. Conversely, agile approaches are the option of choice when complex problem spaces and solution paths are to be explored and refined progressively; but may prove ineffective in dealing with business, organizational, or technical dependencies set from outside projects. That difference of perspective is reflected by the mechanisms used to manage dependencies: milestones or backlogs.
Sorting out dependencies means consolidating informational and engineering constraints across architecture layers. When problem spaces and solution paths cannot be managed under the same authority (heterogeneous dependencies) phased development models use milestones to consolidate expectations and commitments across layers and time-frames.
Otherwise (homogeneous dependencies) agile development models use backlogs to explore problem spaces and solution paths, whatever the architecture layer and nature of dependencies. With the benefit of shared ownership, business events are propagated all along development paths, governing backlogs of stories (business requirements), features (engineering constraints), and releases (operational requirements).
Backlogs can be used to consolidate organizational, functional, and technical dependencies.
Along that perspective backlogs and milestones can be seen as mirrored solutions of the same problem, namely how to deal with the functional and timing dimension of dependencies: backlogs deal only with the functional dimension as they consider the dependencies between tasks without taking into account their actual timing; milestones look from the opposite direction, anchoring aggregate tasks to timetables before considering dependencies between items. Depending on the point of view:
Backlogs may appear as stacks of stones: the milestones are fragmented and the initial sequence translated into queues.
Milestones may appear as flattened backlogs: dependencies are frozen and stories are ironed out before being merged into heaps.
Milestones can be seen as “flattened” backlogs, or, alternatively, backlogs as stacked milestones
Hence, with regard to the ranking of dependencies, the difference between backlogs and milestones is of granularity, finer for the former, coarser for the latter. But with regard to execution, the difference is of nature: contrary to milestones, backlogs don’t fix any timing.
That distinction between sequence (functional ranking) and schedule (time ranking) may be critical when iterative development has to be combined with heterogeneous dependencies.
Collaboration Levels
As noted above, the planning of work units must take into account three criteria:
The dependencies between tasks, engineering or informational, determine the sequencing independently of actual timing. They are derived from technical or organizational constraints.
The schedules anchor the start and completion of tasks to time-frames. Some time-frames are set within the enterprise (e.g resources availability), others are set from outside (e.g regulations or business opportunities).
Pace determine the elapsed time taken to complete a task. It may be seen as a metronome used to adjust the throughput depending on resources availability on one hand, quality requirements on the other hand.
Milestones and Backlogs Capabilities
At first sight, comparison shows backlogs to outdo milestones on all three accounts: dependencies are managed at finer granularity, which enables dynamic scheduling and releases management; last but not least, due to iteration cycles and time-boxing, development paces can be aligned with resources and quality requirements. Yet, that edge can be misleading if dependencies translate into unmanageable or multiple backlogs.
Collaboration is at the core of iteration cycles, and it can only be achieved through shared and dynamic management of backlogs. Assuming a set of stories, each new cycle has to be preceded by decisions regarding priorities, refinements, and responsibilities; and if informational dependencies have to be taken into account, these decisions must be taken collectively and directly:
Collectively: decisions about priorities and refinements must be negotiated between team members from both sides of the business/system (or users/developers) divide.
Directly: all decisions must be taken by the team itself, without any organizational mediation or external interference.
But those conditions could be thwarted if different projects have to develop stories with shared features implemented on different platforms.
Shared features and cross implementations could thwart collective and direct decision-making.
In that case consolidation mechanisms could bring back fixed scope/schedule configurations:
Different teams, each with its own specific users and developers concerns, will have to commit to agreed features and timetables.
By involving independent organizational units, those decisions will entail some procedural mediation carried out independently of iteration cycles.
Yet, that shouldn’t necessarily be the end of the stories, providing some mechanism could be found to synchronize iteration cycles. And that could be achieved with blackboards.
From Backlogs to Blackboards
Blackboards can be understood as shared backlogs stripped from their ranking mechanism so that items can be consulted and dealt with by different project teams. Alternatively, they can also be seen as timetables stripped from scheduling mechanism. Either way, those views illustrate how blackboards may support shared dependencies without forcing them into time-frames:
Shared features are posted on a single blackboard where their status can be consulted and updated by the teams in charge of the stories concerned.
Development teams post their releases on blackboards according to targeted platforms.
Blackboards are used to manage shared dependencies and differentiated stories’ contents
As it happens, that approach also answers the recurring question of stories’ nature and granularity: with the benefit of blackboards, fine-grained stories can be indexed as business cases, use cases, or new releases and cohabit in backlogs.
Combining backlogs with blackboards provides a collaboration mechanisms supporting external dependencies without impairing teams ownership of iteration cycles. Yet it is not a substitute for schedules as it doesn’t deal with the alignment of cycles with enterprise time-frames.
Time boxes as Pacemakers
Milestones and backlogs are synchronization mechanisms. The former, combined with timetables, coordinate teams along time-spans; the latter, combined with time boxes, coordinate tasks between cycles. Hence, while both aim at the same objective, namely that everything doesn’t happen at once, their understanding of time is very different: timetables are bound to an external measure of time, time boxes are just arbitrarily fixed intervals that can be tethered to any time-frame.
As a consequence, time boxes can be applied at different levels. At system level they are associated to project backlogs and used to set the tempo of iteration cycles. At enterprise level they are associated to business objectives and anchored to strategic plans. Assuming those plans are described by epics, it would be possible to use different tempos depending on level (enterprise or systems) or even applications.
Time boxes can be combined with blackboards to synchronize tempos between enterprise level (T) and interrelated projects (T/x and T/y).
Ideally, differentiated tempos should foster an emerging harmony between melody (users’ stories) and accompaniment (supporting systems) converging into the fulfillment of strategic objectives. Practically, the alignment of releases with epics cannot be taken for granted.
Squaring the Circles: Project Planning
Agile approaches are based upon the dynamic exploration of problem spaces and the iterative development of solution paths, the objective being to maximize the value of functional requirements under the constraints of technical ones. Yet, with spaces and paths defined dynamically, standard exploration procedures like breath or depth-first traversal are useless because the ranking of paths is part of the solution, which means that priorities must be revised at the end of each cycle.
Nonetheless, explorations cannot be everlasting and there must be some end to the story, when stakeholders get what they expect (or accept what they get) and users can begin to reap the benefits. Fixed scope and schedules being ruled out, the problem is to align iterations outcomes (b) with business objectives (a). Solutions can be positioned between two archetypal approaches, one driven by business objectives, the other by development tasks.
How to align tasks (b) with objectives (a)
The first approach would see development teams take commitments with regard to broadly defined objectives: with problem spaces represented by trees progressively refined and explored, commitments can be made collectively on sets of solution paths within still undefined sub-trees (b1). The team will then take responsibility for the details of iteration cycles and will adjust its throughput as to align releases with business objectives.
Alternatively, and providing a finer granularity can be obtained and managed, stories could be broken down into tasks for which commitments will be made individually by team members (b2). Assuming that the tasks workloads can be assessed, iterations could then be planned and releases scheduled on the basis of time boxes parameters.
Commitments can be made collectively with regard to objectives (b1) or individually with regard to tasks (b2).
Not surprisingly, the choice of a planning policy is to be conditioned by the granularity of work units:
Task based planning requires finer grained stories and comes with a phased flavor by reintroducing analysis. That may stretch the intervals between iterations and increase management overheads.
Objective based planning allows for coarser grained stories and is more in line with agile spirit. Yet that may increase the length of iterations and affect their transparency.
All things considered, some feedback loop may be needed when deciding on the size of stories because shorter ones do not necessarily decrease the time to market as they may generate bigger backlogs and exponential overheads in case of complex dependencies.
Balancing Pushes and Pulls: Lean and Just-in-Time Workflows
When push comes to shove project planning turns into conflict management. That may happen with phased development models as well as with agile ones. With the former that will be due to applications forcibly pulled out whatever their value for users and reliability in order to meet unrealistic expectations. With the latter that will be due to requirements forcibly pushed into backlogs disregarding their size and exponential complexity.
The way out of this dilemma is a feedback mechanism between project teams pushing releases and business stakeholders pulling applications. And that is the rationale behind the Kanban development model:
Visualize workflow: up-to-date expectations, constraints, commitments and achievements must be clearly and selectively visible to all concerned. that can be done with backlogs and blackboards.
Limit work in progress: that can be obtained by regulating the selection of solution paths through limits on the size of backlogs and the fragmentation of users’ stories according to their architecture footprint.
Measure and manage flows: metrics and process design can be significantly improved if flows are differentiated depending on architecture layer (business, systems, platforms).
Make process policies explicit: that is already a cornerstone of agile backlog management; those principles should also apply to backboards.
Use models to recognize improvement opportunities: while initially ignored, the benefits of models in agile development is progressively acknowledged. Those benefits have be illustrated in the first part of this article by the use of activity diagrams for the exploration of problems spaces and solutions paths.
Applying those principles will bring about lean processes and just-in-time workflows, improving both users’ value and software quality.
Assuming, for the sake of the argument, that programs are models of implementations, one may also argue that the main challenge of software engineering is to translate requirements into models. But, contrary to programs, nothing can be assumed about requirements apart from being stories told by whoever will need system support for his business process.
Telling Stories with Models
Along that reasoning, one may consider the capture and analysis of requirements under the light of two archetypal motifs of storytelling, the Tower of Babel and the Rashomon effect:
While stakeholders and users may express their requirements using their own dialects, supporting applications will have to be developed under the same roof. Hence the need of some lingua franca to communicate with their builders.
A shared language doesn’t necessary mean common understandings; as requirements usually reflect local and time dependent business opportunities and goals, they may relate to different, if not conflicting, aspects of contexts and concerns that will have to be consolidated, eventually.
From such viewpoints, the alignment of system models to business stories clearly depends on languages and narratives discrepancies.
Business to System Analyst: Your language or mine ?
Stories must be told before being written into models, and that distinction coincides with the one between spoken and written languages or, on a broader perspective, between direct (aka performed) and documented communication.
Direct communication (by voice, signs, or mime) is set by time and location and must convey contexts and concerns instantly; that’s what happens when requirements are first expressed by business analysts with regard to actual and specific goals.
Direct communication requires instant understanding
Written languages and documented communication introduces a mediation, enabling stories to be detached from their native here and now; that’s what happens with requirements when managed independently of their original contexts and concerns.
Documented communication makes room for mediation
The mediation introduced by documented requirements can support two different objectives:
Elicitation: while direct communication calls for instant understanding through a common language, spoken or otherwise, written communication makes room for translation and clarification. As illustrated by Kanji characters, a single written language can support different spoken ones; that would open a communication channel between business and system analysts.
Analysis: since understanding doesn’t mean agreement, mediation is often necessary in order to conciliate, arbitrate or consolidate requirements; for that purpose symbolic representations have to be introduced.
Depending on (1) the languages used to tell the stories and (2) the gamut of concerns behind them, the path from stories to models may be covered in a single step or will have to mark the two steps.
Context and Characters
Direct communication is rooted in actual contexts and points to identified agents, objects or phenomena. Telling a story will therefore begin by introducing characters and objects supposed to retain their identity all along; characters will also be imparted with behavioral capabilities and the concerns supposed to guide them.
Stories start with characters and concerns
With regard to business, stories should therefore be introduced by a role, an activity, and a goal.
Every story is supposed be told from a specific point of view within the organization. That should be materialized by a leading role; and even if other participants are involved, the narrative should reflect this leading view.
If a story is to provide a one-lane bridge between past and future business practices, it must focus on a single activity whose contents can be initially overlooked.
Goals are meant to set specific stories within a broader enterprise perspective.
After being anchored to roles and goals, activities will have to be set within boundaries.
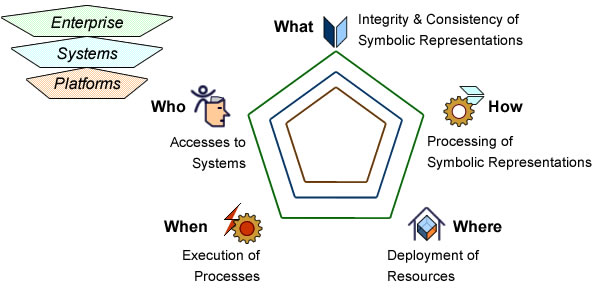
Casings and Splits
Once introduced between roles (Who) and goals (Why), activities must be circumscribed with regard to objects (What), actions (How), places (Where) and timing (When). For that purpose the best approach is to use Aristotle’s three unities for drama:
Unity of action: story units must have one main thread of action introduced at the beginning. Subplots, if any, must return to the main plot after completion.
Unity of place: story units must be located into a single physical space where all activities can be carried out without depending on the outcome of activities performed elsewhere.
Unity of time: story units must be governed by a single clock under which all happenings can be organized sequentially.
Stories, especially when expressed vocally, should remain short and, if they have to be divided, splits should not cross units boundaries:
Action: splits are made to coincide with variants set by agents’ decisions or business rules.
Place: splits are made to coincide with variants in physical contexts.
Time: splits are made to coincide with variants in execution constraints.
When stories refer to systems, those constraints should become more specific and coincide with interaction units triggered by a single event from a leading actor.
Filling the blanks
If business contexts, objectives, and roles can be identified with straightforward semantics set at corporate level, meanings become more complex when stories are to be fleshed out with details defined by the different business units. That difficulty can be managed through iterative development that will add specifics to stories within the casing invariants:
Each story is developed within a single iteration whose invariants are defined by its action, place, and time-scale.
Development proceed by increments whose semantics are defined within the scope set by invariants: operations relative to activities, features relative to objects, events relative to time-scales.
A story is fully documented (i.e an iteration is completed) when no more details can be added without breaking the three units rule or affecting its characters (role and goal) or the semantics of features (attributes and operations).
Iterations: a story is fully fleshed out when nothing can be changed without affecting characters’ features or their semantics.
From Documented Stories to Requirements
Stories must be written down before becoming requirements, further documented by text, model, or code:
Text-based documentation uses natural language, usually with hypertext extensions. When analysts are not familiar with modeling languages it is the default option for elicitation and the delivery of comprehensive, unambiguous and consistent requirements.
Models use dedicated languages targeting domains (specific) or systems (generic). They are a necessary option when requirements from different sources are to be consolidated before being developed into code.
Code (aka execution model) use dedicated languages targeting execution environments. It is the option of choice when requirements are self-contained (i.e not contingent to external dependencies) and expressed with formal languages supporting automated translation.
Whatever their form (user stories, use cases, hypertext, etc), documented requirements must come out as a list of detached items with clearly defined dependencies. Depending on dependencies, requirements can be directly translated into design (or implementation) models or will have to be first consolidated into analysis models.
Telling Models from Stories
Putting aside deployment, development models can be regrouped in two categories:
Analysis models describe problems under scrutiny, the objective being to extract relevant aspects.
Descriptions and specifications look from different perspectives
Seen from the perspective of requirements, the objective of models is therefore to organize the contents of business stories into relevant and useful information, in other words software engineering knowledge.
Following the principles set by Davis, Shrobe, and Szolovits for Knowledge Management (cf readings), such models should meet two groups of criteria, one with regard to communication, the other with regard to symbolic representation.
As already noted, models are introduced to support communication across organizational structures or intervals of time. That includes communication between business and systems analysts as well as development tools. Those aspects are supposed to be supported by development environments.
As for model contents, the ultimate objective is to describe the symbolic representations of the business objects and processes targeted by requirements:
Surrogates: models must describe the symbolic counterparts of actual objects, events and relationships.
Ontological commitments: models must provide sets of statements about the categories of things that may exist in the domain under consideration.
Fragmentary theory of intelligent reasoning: models must define what artifacts can do or can be done with.
The main challenge of analysis is therefore to map the space between requirements (concrete stories) and models (symbolic representations), and for that purpose traditional storytelling may offer some useful cues.
From Fictions to Functions
Just like storytellers use cliches and figures of speech to attach symbolic meanings to stories, analysts may use patterns to anchor business stories to systems models.
Cliches are mental constructs with meanings set in collective memory. With regard to requirements, the equivalent would be to anchor activities to primitives operations (e.g CRUD), and roles to functional stereotypes.
Archetypes can be used to anchor stories to shared understandings
While the role of cliches is to introduce basic items, figures of speech are used to extend and enrich their meanings through analogy or metonymy:
Analogy is used to identify features or behaviors shared by different stories. That will help to consolidate the description of business objects and activities and points to generalizations.
Metonymy is applied when meanings are set by context. That points to aggregate or composite objects or activities.
Primitives, stereotypes, generalization and composition can be employed to map requirements to functional patterns. Those will provide the building blocks of models and help to bridge the gap between business processes and system functionalities.
The value of a model is its fitness to purpose. Missing this simple truth will inevitably trigger a “flight for abstraction” and begets models devoid of any anchor to business relevancy.
Abstraction ladders must be propped up by actual contexts (A. Magnaldo)
Yet, that pitfall can be avoided if requirements and models are put in perspective:
Requirements are meant to describe systems in their business context, models describe system artifacts. They should not be confused because the former are supposed to be rooted in concrete descriptions, while the latter aim at their abstract representation.
Models are built from nodes and associations. Nodes refer to instances which are supposed to be uniformly and consistently identified in both business and system contexts; associations may refer to instances (relationships and flows) or classes (specialization and generalization), the former with consistent semantics for business and system realms, the latter with semantics specific to system artifacts.
Along that perspective, the mapping of requirements into models can be achieved by applying selectively the two faces of abstraction: first removing information from the description of actual contexts, then building symbolic representations according to business concerns.
Business Context and Concerns
Starting with requirements, the challenge is therefore to move up and down the abstraction ladder until one gets the focus right, providing a clear and sharp picture of business context and concerns.
With regard to systems engineering, models’ semantics are unambiguously determined by their target: business environments or systems artifacts:
Models of business environments describe the relevant features of selected objects and behaviors, including supporting systems. Such models are said extensional as they target subsets of actual contexts.
Models of systems artifacts specify the hardware and software components of supporting systems. Such models are said intensional as they define artifacts to be created.
Business analysts figure models from actual contexts and concerns, software architects specify blueprints for artifacts
Climbing up the abstraction ladder, the objective is to align descriptive models of objects and behaviors with prescriptive models of system artifacts. That can be achieved in three steps:
Awareness of contexts: mind the business pie, drop everything else.
Domains of concern: say what features mean.
Symbolic representations: consolidate the descriptions of surrogates.
It is worth to note that the first two levels deal respectively with instances and features of actual objects and activities, while the third deal with artifacts. As a corollary, abstraction at the first two levels should be understood in terms of partitions and subsets, with subtypes introduced only for symbolic representations.
Awareness of Context
As illustrated by sounds (filtering noises) or optics (image point), focusing is a basic perceptual task targeting actual instances of objects, events, or activities. With regard to models, it can be achieved with a pronged move:
Adjust the depth of field to encompass the relevant business context. Large depths of field (aka deep focus) will cover concerns across domains, small ones (aka shallow focus) will support specific business concerns.
Single out image points for identified objects or activities deemed to be pivotal.
Field 1 is too small, field 3 is too large. “Dimensions” has no identity of its own, “Broom” is pointless.
A too shallow focus will capture only some of relevant objects (Piano), activities (Move) or events (Concert). Conversely, extending the focus may go too deep, including irrelevant items (Trumpet, Violinist, Illness, or Repair). Moreover, some image points may depend of others for their identity (Dimensions), or be pointless altogether (Broom).
Domains of Concerns
While business contexts are the same for all, business concerns are by nature specific to domains. The challenge for requirements capture is therefore to anchor specific features to shared objects and activities whose identities are set by business context.
For that purpose concerns are to be organized into domains responsible for the identification of anchors (objects, agents, activities) and the semantics of features:
Shared domains deal with anchors whose continuity and consistency have to be managed across domains, independently of activities.
Specific domains deal with anchors whose continuity and consistency can be managed within a single domain.
At this stage the challenge is to distinguish between identified instances of business objects (piano, concert) and processes (cleaning, moving, playing) on one hand, and the description of roles (mover, cleaner, pianist) and business logic (clean, move, play) on the other hand .
Domains of Concerns and Business Processes
It must be reminded that such models are still at ground level as they describe sets of instances; yet, they can also be seen as the first step up the abstraction ladder, as their objective is to extract relevant features and overlook others.
Symbolic Representations
While business concerns are partial and biased, the symbolic representations managed at system level must be comprehensive and consistent; that’s the objective of requirements analysis.
To start with, symbolic representations are introduced for each set of objects, roles or activities:
Objects surrogates: used to manage the continuity and consistency of business objects independently of business processes (piano, concert).
Process surrogates: used to manage the continuity and consistency of business operations independently of business objects (move, play, clean).
Roles: used to manage the interactions between actual agents and system functionalities (mover, cleaner, pianist). When the continuity and consistency of operations performed by agents are managed (e.g pianist), roles must be associated to surrogates.
Activities: used to describe business logic (move, play, clean).
Business logic and surrogates (#) for objects, processes and pianist .
Those are “flat” descriptions representing ground level instances. In order to be effectively supported by systems, models may have to be expanded downward by specialization, or upward by generalization.
Levels of Abstraction
As already noted, specialization and generalization are not symmetric because, contrary to the former operation, the latter one does modify the semantics of existing artifacts.
The purpose of specialization is to introduce specific descriptions for subsets of instances or features. For instance, assuming requirements are about moving pianos, the representation must climb one step down the abstraction ladder, from concerts to concerts with pianos:
Solo piano concerts are a subset of concerts subject to the same identification mechanisms and integrity constraints (strong inheritance).
The description of moving operations is not used to manage instances and its specialization is only about features (weak inheritance).
Climbing down: specialization of features (Move Piano) and surrogates (Solo Concert)
The purpose of generalization is twofold as it may be limited to features (aka aspect generalization) or targets both identification mechanisms and features (aka object generalization).
Aspect generalization introduces a base artifact for the description for shared features. Such base artifact is said to be abstract because its inheritance is limited to features and it cannot support the instantiation of surrogates, specialized artifacts keeping their own identification mechanisms. As a corollary, the level of abstraction is not modified because the model remains anchored to the same sets of instances. For instance (a), some administrative procedures can be defined uniformly for all maintenance operations otherwise described and executed independently.
Climbing up: generalization of features only (a), and for both features and individuals (b).
That’s not the case with object generalization which redefines the initial sets of surrogates as subsets of newly created super-sets. For instance (b), a cleaning process becomes a maintaining processes without the repair extension. Since maintaining processes can be created as simple cleaning or repairing ones, the model is anchored to different levels of abstraction. And since descriptions should not cross levels, roles must be specialized similarly: maintainers are to be identified as such before being qualified as mechanics, even if their interventions are not managed as such (inheritance of transient identification mechanism).
Getting A Proper Grip
Models are neither true or false and can only be assessed for consistency and effectiveness.
Hence, assuming that (1) systems are meant to handle surrogates of business objects and processes and, (2) those surrogates are designed from models, it ensues that (3) a litmus test of model effectiveness would be the grip it provides on relevant objects and processes.
A grip on context and concerns
And that can only be achieved by pinning models to concrete and identified business objects and processes. That provides a template for modeling grips: concrete descriptions with primary identification in the middle, abstract ones above, aspects or concrete descriptions with inherited identification below.
As long as information was just data files and systems just computers, the respective roles of enterprise and IT architectures could be overlooked; but that has become a hazardous neglect with distributed systems pervading every corner of enterprises, monitoring every motion, and sending axons and dendrites all around to colonize environments.
Enterprise Governance and Separation of Concerns (R.Magritte)
Yet, the overlapping of enterprise and systems footprints doesn’t mean they should be merged, as a matter of fact, that’s the opposite. When the divide between business and technology concerns was clearly set, casual governance was of no consequence; now that turfs are more and more entwined, dedicated policies are required lest decisions be blurred and entropy escalates as a consequence. The need of better focus is best illustrated by the sundry meanings given to “system”, from computers running software to enterprises running businesses, and even school of thought.
Concerns in Perspectives
As far as enterprises are concerned, systems combine human beings, devices, and software components.
From a functional perspective, their capabilities are best defined by their interactions with their environment as well as between their constituents:
Users are supposed to be actual agents granted with organizational status and responsibilities, and possessing symbolic communication capabilities.
Software components and actual devices cannot be granted with organizational status or responsibilities; the former come with symbolic communication capabilities, the latter without.
Assuming that interactions are governed by information, the objective is to understand the contribution of each type of component with regard to information processing and decision-making.
System = Agents + Devices + Symbolic representations
From an engineering perspective, the building of systems is all too often reduced to the development of their software constituents. As a consequence, the complexity of the forest is masked by the singularity of the trees:
The business value of applications is assessed locally instead of being driven by enterprise objectives and organizational constructs.
System models are confused with the programs used to produce software components.
Requirements life cycle, governed by the time-span of business contexts and objectives, is confused with the cycles of reuse of architecture assets.
Since engineering agenda are supposed to support business objectives, their decision-making processes must be aligned yet managed independently. That reasoning also applies to services management whose role is to adjust resources and software releases to operational needs.
Enterprise architectures can then be described as a cross between architecture assets (business objects, organization, technical architecture) on one hand, core processes for business, engineering and services management on the other hand.
EA Artifacts at crossroads between Architectures and Activities
Information is to provide the glue between architecture assets and supported processes.
Information and Architectures Levels
As understood by Cybernetics (see Stafford Beer, “Diagnosing the System for Organizations“), enterprises are viable systems whose success depends on their capacity to countermand entropy, i.e the progressive downgrading of the information used to govern interactions between systems and their environment. And that put knowledge management at the core of systems capabilities.
Knowledge is best defined as information put to use, with information obtained by adding references and sense to data. That blueprint is supposed to be repeated at all architecture levels:
At enterprise level facts pertaining to the conduct of business are captured from environments before being organized into information meant to support enterprise governance.
System level deals with symbolic descriptions of functionalities (information). At this level data is irrelevant, the objective being the consolidation and reuse of shared representations and patterns (knowledge).
The technical level is in charge of operational governance: software components, platforms capabilities, technical resources, communication mechanisms, etc. On one hand contexts are to be monitored and data translated into information; one the other hand operational decisions have to be made (knowledge) and executed which means information translated into data.
Architecture Layers and Processing Capabilities
If architecture levels can be characterized by processing capabilities, their engineering must be aligned to the corresponding objectives and time frames.
System Engineering and Separation of Concerns
As demonstrated time and again by blame games around projects failures, enterprise and technical concerns are poor engineering bedfellows, and with good reasons: different contexts, concerns, skills, and time scales. Faced with the challenge of bringing enterprise and development perspectives under a single governance, engineering approaches generally follow one of two basic options:
Phased projects (P) give precedence to software development, with requirements supposed to be set at inception and acceptance performed at completion.
Agile projects (A) give precedence to business requirements, with development iterations combining specifications, programming, and acceptance.
Phased (P) and Agile (A) development models
While each approach has its merits, agile for complex but well circumscribed projects, phased for large projects with external organizational dependencies, the difficulties each may encounter point to the crux of the matter, namely the separation of concerns between business goals and information technology, bypassed by agile approaches and misplaced by phased ones:
Agile development models are driven by users’ value and based on the implicit assumption that business and technology concerns can be dealt with continuously and simultaneously. That may be difficult when external dependencies cannot be avoided and shared ownership cannot be guaranteed.
Phased development models take a mirror position by assuming that business concerns can be settled upfront, which is clearly a very hazardous policy.
Those pitfalls may be overcome if engineering processes take into account the distinction between knowledge management on one hand, software development on the other hand.
Knowledge management (KM) encompasses all information pertaining to the conduct of business: environment, markets, objectives, organization, and projects. With regard to engineering projects, its role is to define and consolidate the descriptions of symbolic representations to be supported by information systems.
Software development (SD) starts with symbolic descriptions and proceeds with the definition, building and acceptance of the corresponding software artifacts.
Service management (SM) provides the bridge between engineering and operational processes.
Capture of information from data and legacy code can also be achieved respectively by data mining and reverse engineering.
System Engineering = Knowledge (KM) + Software (SD) + Service (SM)
Depending on organizational or technical dependencies, knowledge management and software development will be carried out within integrated development cycles (agile processes), or will have to be phased in order to consolidate the different concerns.
That engineering distinction neatly coincides with the functional divide of architectures: knowledge management supporting enterprise architecture, software development supporting system architecture.
Architectures and Engineering Processes
Business processes are governed by collective representations mixing goals, models and rules, not necessarily formally defined, and subject to change with opportunities. Engineering processes for their part have to be materialized through work units, models, and products, all of them explicitly defined, with limited room for change, and set along constraining schedules. Given that systems’ fate hangs on the hing between business and engineering concerns, the corresponding perspectives must be properly aligned.
That can be achieved if workshops are associated with architecture levels, and work units defined according model layers and development flows:
Knowledge management takes charge of symbolic descriptions pertaining to enterprise concerns. Its objective is to map business and operational requirements with the functionalities of supporting systems. Expressed in MDA parlance, the former would be described by computation independent models (CIMs), the latter by platform independent models (PIMs).
Software development deals with software artifacts. That encompasses the consolidation of symbolic descriptions into functional architectures, the design of software components according to platforms specificity (PSMs), and the production of code according to deployment targets (DPMs).
IT Service Management is the counterpart of knowledge management for actual operations and resources. Its objective is to synchronize business and development time-frames and align operational requirements with releases and resources.
Knowledge Management (KM), Software Development (SD), Services Management (SM)
That congruence between architecture divides (enterprise, systems, technology), models layers (CIMs, PIMs, PSMs, DPMs), and engineering concerns (facts or legacy, information, knowledge), provides a reasoned and comprehensive framework for enterprise architectures.
Architecture Capabilities & Separation of Concerns
Architectures describe stocks of shared assets, processes describe flows of changes. Given a hierarchized description of architectures, the objective is to ensure the traceability of concerns and decisions across levels and processes.
Who: enterprise roles, system users, platform entry points.
What: business objects, symbolic representations, objects implementation.
How: business logic, system applications, software components.
When: processes synchronization, communication architecture, communication mechanisms.
Where: business sites, systems locations, platform resources.
The rationale of objectives and decisions (the “Why” of Zachman framework) is expressed by dependency links according to the nature of primary factors:
Deontic dependencies are set by external factors, e.g regulatory context, communication technologies, or legacy systems.
Alethic (aka modal) dependencies are set by internal policies, based on the assessment of options regarding objectives as well as solutions.
Architecture Capabilities and Processes, with deontic (basic) and alethic (dashed) dependencies.
This distinction between dependencies is critical for decision-making and consequently for enterprise governance. Set within time-frames and decorated with time related features, those dependencies can then be consolidated into differentiated strategies for business, engineering and operational processes.
Given that dependencies are usually interwoven, governance must be aligned with the footprints of associated decisions:
Assets: shared decisions affecting different business processes (organization), applications (services), or platforms (purchased software packages).
Users’ Value: streamlined decisions governed by well identified business units providing for straight dependencies from enterprise (business requirements), to systems (functional requirements) and platforms (users’ entry points).
Non functional: shared decisions about scale and performances affecting users’ experience (organization), engineering (technical requirements), or resources (operational requirements).
Separation of Concerns and Requirements Taxonomy
That classification can be used to choose a development model:
Agile approaches should be the option of choice for requirements neatly anchored to users’ value.
Phased approaches should be preferred for projects targeting shared assets across architecture levels. When shared assets are within the same level epic-like variants of agile may also be considered.
Architectures, Processes, and Governance
While there is some consensus about the scope and concerns of Enterprise Architecture as a discipline, some debate remains about the relationship between enterprise and IT governance.
Beyond turf quarrels, arguments are essentially rooted in the distinction between information and supporting systems or, more generally, between organization and IT.
To some extent, those arguments can be ironed out if governance were set with regard to scope, actual or symbolic:
Actual scope deals with current or planned business objects, assets, and processes.
Symbolic scope deals with the design of the corresponding software components.
What is to be governed: actual and symbolic scopes
That distinction matches the divide between enterprise and systems architectures: one set of models deals with enterprise objectives, assets, and organization, the other one deals with system components.
With regard to processes, governance should distinguish between business and engineering:
Business processes are clearly designed at enterprise level, both for their organization and the symbolic description of system representations.
Software engineering ones are under the responsibility of IT governance, from system and software architecture to release and deployment.
Process and architecture perspectives for Governance
While governance could be shared, there is no reason to assume immediate and continuous alignment of perspectives; that could only be achieved through architecture perspective:
Actual architectures encompass business organization (locations, agents, devices) and systems deployments.
Symbolic architectures include systems functionalities and software development.
And, as a mirror achievement, processes take charge of transitions between actual and symbolic architectures:
Processes carry out Architectures alignment (Pb,Pe), Architectures support Processes consistency (As, Ap).
Symbolic architectures provide the mediation between business requirements and software development (As).
Physical architectures do the same between software development and services management (Ap).
Business processes take responsibility for the mapping of enterprise architecture into symbolic representations (Pb).
Engineering processes do the same for the alignment of software and deployment architectures (Pe).
Enterprise and IT governance can then be defined in terms of Knowledge management, with engineering and business processes gathering data from their respective realms, sharing the information through architectures, and putting it to use according their respective concerns.