The primary aim of ontologies is to bring under a single roof three tiers of representations and to ensure both their autonomy and integrated usage:
Thesauruses federate meanings across digital (observations) and business (analysis) environments
Models deal with the integration of digital flows (environments) and symbolic representations (systems)
Ontologies ensure the integration of enterprises’ data, information, and knowledge, enabling a long-term alignment of enterprises’ organization, systems, and business objectives
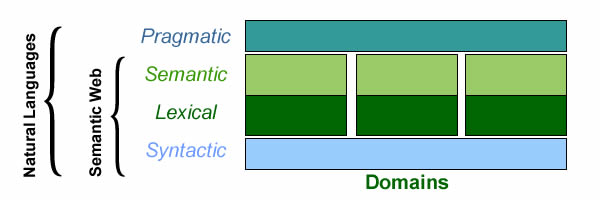
To ensure their interoperability, tiers should be organized according to linguistic capabilities: lexical, syntactic, semantic, pragmatic.
To ensure their conceptual integration, ontologies must maintain an explicit distinction between:
Concepts: pure semantic constructs defined independently of instances or categories
Categories: symbolic descriptions of sets of objects or phenomena: Categories can be associated with actual (descriptive, extensional) or intended (prescriptive, intensional) sets of instances
Facts: observed objects or phenomena
Documents: entries for documents represent the symbolic contents, with instances representing the actual (or physical) documents
As for technical integration, it is can be achieved through graphical neural networks (GNN) and Resource description framework (RDF).
Depending on context and purpose requirements can be understood as customary documents, contents, or work in progress.
Given that requirements are the entry point of engineering processes, nothing should be assumed regarding their form (natural, formal, or specific language), or content (business, functional, non-functional, or technical).
Depending on the language used, requirements can be directly analyzed and engineered, or may have to be first formatted (aka captured).
Requirements taxonomy should be set with regard to processes (business or architecture driven) and stakeholders (business units or enterprise architecture).
Depending on content and context, requirements can be engineered as a whole (agile development models), or set apart as to tally with external dependencies (phased development models).
While processes and activities are often defined together, the primary purpose of processes is to specify how activities are to be carried out if and when activities have to be executed separately.
Given the focus on execution, definitions of processes should be aligned with the classification of events and time, namely the nature of flows and coupling:
No flows (computation).
Information flows between activities.
Actual flows between activities, asynchronous coupling.
Actual flows, synchronous coupling.
That taxonomy could be used to define execution units in line with activities and the states of objects and expectations.
As championed by a brave writer, should we see the Web as a crib for born again narratives, or as a crypt for redundant texts.
Crib or Crypt (Melik Ohanian)
Once Upon A Time
Borrowing from Einstein, “the only reason for time is so that everything doesn’t happen at once.” That befits narratives: whatever the tale or the way it is conveyed, stories take time. Even if nothing happens, a story must be spelt in tempo and can only be listened to or read one step at a time.
In So Many Words
Stories have been told before being written, which is why their fabric is made of words, and their motifs weaved by natural languages. So, even if illustrations may adorn printed narratives, the magic of stories comes from the music of their words.
A Will To Believe
To enjoy a story, listeners or readers are to detach their mind from what they believe about reality, replacing dependable and well-worn representations with new and untested ones, however shaky or preposterous they may be; and that has to be done through an act of will.
Stories are make-beliefs: as with art in general, their magic depends on the suspension of disbelief. But suspension is not abolition; while deeply submerged in stories, listeners and readers maintain some inward track to the beliefs they left before diving; wandering a cognitive fold between surface truths and submarine untruths, they seem to rely on a secure if invisible tether to the reality they know. On that account, the possibility of an alternative reality is to transform a comforting fold into a menacing abyss, dissolving their lifeline to beliefs. That could happen to stories told through the web.
Stories & Medium
Assuming time rendering, stories were not supposed to be affected by medium; that is, until McLuhan’s suggestion of medium taking over messages. Half a century later internet and the Web are bringing that foreboding in earnest by melting texts into multimedia documents.
Tweets and Short Message Services (SMS) offer a perfect illustration of the fading of text-driven communication, evolving from concise (160 characters) text-messaging to video-sharing.
That didn’t happen by chance but reflects the intrinsic visual nature of web contents, with dire consequence for texts: once lording it over entourages of media, they are being overthrown and reduced to simple attachments, just a peg above fac-simile. But then, demoting texts to strings of characters makes natural languages redundant, to be replaced by a web Esperanto.
Web Semantic Silos
With medium taking over messages, and texts downgraded to attachments, natural languages may lose their primacy for stories conveyed through the web, soon to be replaced by the so-called “semantic web”, supposedly a lingua franca encompassing the whole of internet contents.
As epitomized by the Web Ontology Language (OWL), the semantic web is based on a representation scheme made of two kinds of nodes respectively for concepts (squares) and conceptual relations (circles).
Semantic graphs (aka conceptual networks) combine knowledge representation (blue, left) and domain specific semantics (green, center & right)
Concept nodes are meant to represent categories specific to domains (green, right); that tallies with the lexical level of natural languages.
Connection nodes are used to define two types of associations:
Semantically neutral constructs to be applied uniformly across domains; that tallies with the syntactic level of natural languages (blue, left).
Domain specific relationships between concepts; that tallies with the semantic level of natural languages (green, center).
The mingle of generic (syntactic) and specific (semantic) connectors induces a redundant complexity which grows exponentially when different domains are to be combined, due to overlapping semantics. Natural languages typically use pragmatics to deal with the issue, but since pragmatics scale poorly with exponential complexity, they are of limited use for semantic web; that confines its effectiveness to silos of domain specific knowledge.
Natural Language Pragmatics As Bridges Across Domain Specific Silos
But semantic silos are probably not the best nurturing ground for stories.
Stories In Cobwebs
Taking for granted that text, time, and suspension of disbelief are the pillars of stories, their future on the web looks gloomy:
Texts have no status of their own on the web, but only appear as part of documents, a media among others.
Stories can bypass web practice by being retrieved before being read as texts or viewed as movies; but whenever they are “browsed” their intrinsic time-frame and tempo are shattered, and so is their music.
If lying can be seen as an inborn human cognitive ability, it cannot be separated from its role in direct social communication; such interactive background should also account for the transient beliefs in fictional stories. But lies detached from a live context and planted on the web are different beasts, standing on their own and bereft of any truth currency that could separate actual lies from fictional ones.
That depressing perspective is borne out by the tools supposed to give a new edge to text processing:
Hyper-links are part and parcel of internet original text processing. But as far and long as stories go, introducing links (hardwired or generated) is to hand narrative threads over to readers, and by so transforming them into “entertextment” consumers.
Machine learning can do wonders mining explicit and implicit meanings from the whole of past and present written and even spoken discourses. But digging stories out is more about anthropology or literary criticism than about creative writing.
As for the semantic web, it may work as a cobweb: by getting rid of pragmatics, deliberately or otherwise, it disables narratives by disengaging them from their contexts, cutting them out in one stroke from their original meaning, tempo, and social currency.
The Deconstruction of Stories
Curiously, what the web may do to stories seems to reenact a philosophical project which gained some favor in Europe during the second half of the last century. To begin with, the deconstruction philosophy was rooted in literary criticism, and its objective was to break the apparent homogeneity of narratives in order to examine the political, social, or ideological factors at play behind. Soon enough, a core of upholders took aim at broader philosophical ambitions, using deconstruction to deny even the possibility of a truth currency.
With the hindsight on initial and ultimate purposes of the deconstruction project, the web and its semantic cobweb may be seen as the stories nemesis.
The seamless integration of enterprise systems into digital business environments calls for a resetting of value chains with regard to enterprise architectures, and more specifically supporting assets.
Value Chains & Support (Daniel Jacoby)
Concerning value chains, the traditional distinction between primary and supporting activities is undermined by the generalization of digital flows, rapid changes in business environments, and the ubiquity of software agents. As for assets, the distinction could even disappear due to the intertwining of tangibles resources with organization, information, and knowledge .
These difficulties could be overcome by bypassing activities and drawing value chains directly between business processes and systems capabilities.
From Activities to Processes
In theory value chains are meant to track down the path of added value across enterprise architectures; in practice their relevancy is contingent on specificity: fine when set along silos, less so if set across business functions. Moreover, value chains tied to static mappings of primary and support activities risk losing their grip when maps are redrawn, which is bound to happen more frequently with digitized business environments.
These shortcomings can be fixed by replacing primary activities by processes and support ones by system capabilities, and redefining value chains accordingly.
Substituting processes and capabilities for primary and support activities
From Processes to Functions & Capabilities
Replacing primary and support activities with processes and functions doesn’t remove value chains primary issue, namely their path along orthogonal dimensions.
That’s not to say that business processes cannot be aligned with self-contained value chains, but insofar as large and complex enterprises are concerned, value chains are to be set across business functions. Thus the benefit of resetting the issue at enterprise architecture level.
Borrowing EA description from the Zachman framework, the mapping of processes to capabilities is meant to be carried out through functions, with business processes on one hand, architectures capabilities on the other hand.
If nothing can be assumed about the number of functions or the number of crossed processes, EA primary capabilities can be clearly identified, and functions classified accordingly, e.g: boundaries, control, entities, computation. That classification (non exclusive, as symbolized by the crossed pentagons) coincides with that nature of adjustments induced by changes in business environments:
Diversity and flexibility are to be expected for interfaces to systems’ clients (users, devices, or other systems) and triggering events, as to tally with channels and changes in business and technology environments.
Continuity is critical for the identification and semantics of business objects whose consistency and integrity have to be maintained along time independently of users and processes.
In between, changes in processes control and business logic should be governed by business opportunities independently of channels or platforms.
Mapping Processes to Architectures Functions & Capabilities
Processes, primary or otherwise, would be sliced according to the nature of supporting capabilities e.g: standalone (a), real-time (b), client-server (c), orchestration service (d), business rules (e), DB access (f).
Value chains could then be attached to business processes along these functional guidelines.
Tying Value Chains to Processes
Bypassing activities is not without consequences for the meaning of value chains as the original static understanding is replaced by a dynamic one: since value chains are now associated to specific operations, they are better understood as changes than absolute level. That semantic shift reflects the new business environment, with manufacturing and physical flows having been replaced by mixed (SW and HW) engineering and digital flows.
Set in a broader economic perspective, the new value chains could be likened to a marginal version of returns on capital (ROC), i.e the delta of some ratio between value and contributing assets.
Digital business environments may also made value chains easier to assess as changes can be directly traced to requirements at enterprise level, and more accurately marked across systems functionalities:
Logical interfaces (users or systems): business value tied to interactions with people or other systems.
Physical interfaces (devices): business value tied to real-time interactions.
Business logic: business value tied to rules and computations.
Information architecture: business value tied to systems information contents.
Processes architecture: business value tied to processes integration.
Platform configurations: business value tied to resources deployed.
Marking Value Chains in terms of changes
The next step is to frame value chains across enterprise architectures in order to map values to contributing assets.
Assets & Organization
Value chains are arguably of limited use without weighting assets contribution. On that account, a major (if underrated) consequence of digital environments is the increasing weight of intangible assets brought about by the merge of actual and information flows and the rising importance of economic intelligence.
For value chains, that shift presents a double challenge: first because of the intrinsic difficulty of measuring intangibles, then because even formerly tangible assets are losing their homogeneity.
Redefining value chains at enterprise architecture level may help with the assessment of intangibles by bringing all assets, tangible or otherwise, into a common frame, reinstating organization as its nexus:
From the business perspective, that framing restates the primacy of organization for the harnessing of IT benefits.
From the architecture perspective, the centrality of organization appears when assets are ranked according to modality: symbolic (e.g culture), physical (e.g platforms), or a combination of both.
Ranking assets according to modality
On that basis enterprise organization can be characterized by what it supports (above) and how it is supported (below). Given the generalization of digital environments and business flows, one could then take organization and information systems as proxies for the whole of enterprise architecture and draw value chains accordingly.
Value Chains & Assets
Trendy monikers may differ but information architectures have become a key success factor for enterprises competing in digital environments. Their importance comes from their ability to combine three basic functions:
Mining the continuous flows of relevant and up-to-date data.
Analyzing and transforming data, feeding the outcome to information systems
Putting that information to use in operational and strategic decision-making processes.
A twofold momentum is behind that integration: with regard to feasibility, it can be seen as a collateral benefit of the integration of actual and digital flows; with regard to opportunity, it can give a decisive competitive edge when fittingly carried through. That makes information architecture a reference of choice for intangible assets.
Assets Contribution to Value Chains
Insofar as enterprise architecture is concerned, value chains can then be threaded through three categories of assets:
Agile and phased development solutions are meant to solve different problems and therefore differ with artifacts and activities; that can be illustrated by requirements, understood as dialogs for the former, etched statements for the latter.
Running Stories (Kara Walker)
Ignoring that distinction is to make stories stutter from hiccupped iterations, or phases sputter along ripped milestones.
Agile & Phased Tell Different Stories Differently
As illustrated by ill-famed waterfall, assuming that requirements can be fully set upfront often put projects at the hazards of premature commitments; conversely, giving free rein to expectations could put requirements on collision courses.
That apparent dilemma can generally be worked out by setting apart business outlines from users’ stories, the latter to be scripted and coded on the fly (agile), the former analysed and documented as a basis for further developments (phased). To that end project managers must avoid a double slip:
Mission creep: happens when users’ stories are mixed with business models.
Jump to conclusions: happens when enterprise business cases prevail over the specifics of users’ concerns.
Interestingly, the distinction between purposes (users concerns vs business functions) can be set along one between language semantics (natural vs modeling).
Semantics: Capture vs Analysis
Beyond methodological contexts (agile or phased), a clear distinction should be made between requirements capture (c) and modeling (m): contrary to the former which translates sequential specifications from natural to programming (p) languages without breaking syntactic and semantic continuity, the latter carries out a double translation for dimension (sequence vs layout) and language (natural vs modeling.)
Semantic continuity (c>p) and discontinuity (c>m>p)
The continuity between natural and programming languages is at the root of the agile development model, enabling users’ stories to be iteratively captured and developed into code without intermediate translations.
That’s not the case with modeling languages, because abstractions introduce a discontinuity. As a corollary, requirements analysis is to require some intermediate models in order to document translations.
The importance of discontinuity can be neatly demonstrated by the use of specialization and generalization in models: the former taking into account new features to characterize occurrences (semantic continuity), the latter consolidating the meaning of features already defined (semantic discontinuity).
Confusion may arise when users’ stories are understood as a documented basis for further developments; and that confusion between outcomes (coding vs modeling) is often compounded by one between intents (users concerns vs business cases).
Concerns: Users’ Stories vs Business Cases
As noted above, users’ stories can be continuously developed into code because a semantic continuity can be built between natural and programming languages statements. That necessary condition is not a sufficient one because users’ stories have also to stand as complete and exclusive basis for applications.
Such a complete and exclusive mapping to application is de-facto guaranteed by continuous and incremental development, independently of the business value of stories. Not so with intermediate models which, given the semantic discontinuity, may create back-doors for broader concerns, e.g when some features are redefined through generalization. Hence the benefits of a clarity of purpose:
Users’ stories stand for specific requirements meant to be captured and coded by increments. Documentation should be limited to application maintenance and not confused with analysis models.
Use cases should be introduced when stories are to be consolidated or broader concerns factored out , e.g the consolidation of features or business cases.
Sorting out the specifics of users concerns while keeping them in line with business models is at the core of business analysts job description. Since that distinction is seldom directly given in requirements, it could be made easier if aligned on modeling options: stories and specialization for users concerns, models and generalization for business features.
From Stories to Cases
The generalization of digital environments entails structural and operational adjustments within enterprise architectures.
At enterprise level the integration of homogeneous digital flows and heterogeneous symbolic representations can be achieved through enterprise architectures and profiled ontologies. But that undertaking is contingent on the way requirements are first dealt with, namely how the specifics of users’ needs are intertwined with business designs.
As suggested above, modeling schemes could help to distinguish as well as consolidate users narratives and business outlooks, capturing the former with users’ stories and the latter with use cases models.
Use cases describe the part played by systems taking into account all supported stories.
That would neatly align means (part played by supporting systems) with ends (users’ stories vs business cases):
Users’ stories describe specific objectives independently of the part played by supporting systems.
Use cases describe the part played by systems taking into account all supported stories.
It must be stressed that this correspondence is not a coincidence: the consolidation of users’ stories into broader business objectives becomes a necessity when supporting systems are taken into account, which is best done with use cases.
Aligning Stories with Cases
Stories and models are orthogonal descriptions, the former being sequenced, the latter laid out; it ensues that correspondences can only be carried out for individuals uniformly identified (#) at enterprise and systems level, specifically: roles (aka actors), events, business objects, and execution units.
Crossing cases with stories: events, roles, business objects, and execution units must be uniformly and consistently identified (#) .
It must be noted that this principle is supposed to apply independently of the architectures or methodologies considered.
With continuity and consistency of identities achieved at architecture level, the semantic discontinuity between users’ stories and models (classes or use cases) can be managed providing a clear distinction is maintained between:
Modeling abstractions, introduced by requirements analysis and applied to artifacts identified at architecture level.
The semantics of attributes and operations, defined by users’ stories and directly mapped to classes or use cases features.
From Capture to Analysis: Abstractions introduce a semantic discontinuity
Finally, stories and cases need to be anchored to epics and enterprise architecture.
Business Cases & Enterprise Stories
Likening epics to enterprise stories would neatly frame the panoply of solutions:
At process level users’ stories and use cases would be focused respectively on specific business concerns and supporting applications.
At architecture level business stories (aka epics) and business cases (aka plots) would deal respectively with business models and objectives, and supporting systems capabilities.
Cases & Stories
That would provide a simple yet principled basis for enterprise architectures governance.
Frames are meant to bring light on artifacts, not to cover them with veils; on that account, frameworks’ primary justification should be their leverage on engineering practices.
Frames are meant to bring light on artifacts (Y. Levin)
It ensues that enterprises frameworks should only be considered in relation to actual contents (organization, artifacts, processes, …), and their benefits for core governance issues, in particular measurements, processes integration, and economic intelligence.
Prerequisite: Measurements
The heterogeneity of metrics is clearly a major impediment to assessment at enterprise level due to the different yardsticks associated with business value, development costs, and processes maturity.
The least frameworks should do for enterprise architects is to provide common bearings at both application and enterprise levels:
Application level: a consolidated scale for the mapping of value points, function points, and development costs.
Enterprise level: a common basis for a reliable assessment of systems capabilities and processes maturity.
A detailed account of how a framework would support such bearings should therefore be a prerequisite.
Cornerstone: Business & Engineering Processes Integration
Except for the Zachman framework, providers haven’t much to say about how actual business and engineering processes are to be hung to the proposed framework, and more generally about the continuity with existing methods, tools, and practices.
Conversely, being specific about the hinges linking it to processes is to give credence to a framework leveraging impact:
Business: leveraged agility from the harnessing of users’ stories to business functions.
Engineering: leveraged transparency, traceability and reuse from model based systems engineering (MBSE).
As the cornerstone of any enterprise framework, integration is to support their ultimate purpose, namely economic intelligence.
Deal Breaker: Economic Intelligence
Economic intelligence is usually understood as a merge of data analytics, information architecture, business intelligence, and decision-making; as such it can be seen as a primary justification for enterprise architecture frameworks.
As a corollary, one would expect frameworks to be specific with regard to the integration of data analytics, information processing, and knowledge management:
To begin with, no framework should be considered without being explicit about the ways such integration could be achieved.
Then, integration schemes should aim at being neutral with regard to engineering or support environments deployed at architecture level.
When options are considered, that should be taken as a deal breaker.
Conclusion
Assuming that expectations about measurements and processes could be reasonably borne out, decisions would rest on economic intelligence strategies.
Depending on the weight of information systems legacy, full neutrality may deem a too ambitious strategy. In that case an enterprise architecture framework could be built bottom up from MBSE environments.
Given that proviso, a neutral framework designed on purpose would bring much more leverage due to the generalization of well-defined slots and interfaces for business and engineering platforms; that would also facilitate modernization and consolidate quality assurance across enterprise architectures.
Finally, for EA frameworks to ensure consistent metrics, processes integration, and economic intelligence, knowledge management must encompass a wide range of concerns (business, engineering, regulations, …), contexts (environments, enterprise, systems), and resources (texts, models, people, …); that can be best achieved with profiled ontologies.
Turning thoughts into figures faces the intrinsic constraint of dimension: two dimensional representations cannot cope with complexity.
Making his mind about knowledge dimensions: actual world, descriptions, and reproductions (Jan van der Straet)
So, lest they be limited to flat and shallow thinking, mind cartographers have to introduce the cognitive equivalent of geographical layers (nature, demography, communications, economy,…), and archetypes (mountains, rivers, cities, monuments, …)
Nodes: What’s The Map About
Nodes in maps (aka roots, handles, …) are meant to anchor thinking threads. Given that human thinking is based on the processing of symbolic representations, mind mapping is expected to progress wide and deep into the nature of nodes: concepts, topics, actual objects and phenomena, artifacts, partitions, or just terms.
What’s The Map About
It must be noted that these archetypes are introduced to characterize symbolic representations independently of domain semantics.
Connectors: Cognitive Primitives
Nodes in maps can then be connected as children or siblings, the implicit distinction being some kind of refinement for the former, some kind of equivalence for the latter. While such a semantic latitude is clearly a key factor of creativity, it is also behind the poor scaling of maps with complexity.
A way to frame complexity without thwarting creativity would be to define connectors with regard to cognitive primitives, independently of nodes’ semantics:
References connect nodes as terms.
Associations: connect nodes with regard to their structural, functional, or temporal proximity.
Analogies: connect nodes with regard to their structural or functional similarities.
At first, with shallow nodes defined as terms, connections can remain generic; then, with deeper semantic levels introduced, connectors could be refined accordingly for concepts, documentation, actual objects and phenomena, artifacts,…
Connectors are aligned with basic cognitive mechanisms of metonymy (associations) and analogy (similarities)
Semantics: Extensional vs Intensional
Given mapping primitives defined independently of domains semantics, the next step is to take into account mapping purposes:
Extensional semantics deal with categories of actual instances of objects or phenomena.
Intensional semantics deal with specifications of objects or phenomena.
That distinction can be applied to basic semantic archetypes (people, roles, events, …) and used to distinguish actual contexts, symbolic representations, and specifications, e.g:
Extensions (full border) are about categories of instances, intensions (dashed border) are about specifications
Car (object) refers to context, not to be confused with Car (surrogate) which specified the symbolic counterpart: the former is extensional (actual instances), the latter intensional (symbolic representations)
Maintenance Process is extensional (identified phenomena), Operation is intensional (specifications).
Reservation and Driver are symbolic representations (intensional), Person is extensional (identified instances).
It must be reminded that whereas the choice is discretionary and contingent on semantic contexts and modeling purposes (‘as-it-is’ vs ‘as-it-should-be’), consequences are not because the choice is to determine abstraction semantics.
For example, the records for cars, drivers, and reservations are deemed intensional because they are defined by business concerns. Alternatively, instances of persons and companies are defined by contexts and therefore dealt with as extensional descriptions.
Abstractions: Subsets & Sub-types
Thinking can be characterized as a balancing act between making distinctions and managing the ensuing complexity. To that end, human edge over other animal species is the use of symbolic representations for specialization and generalization.
That critical mechanism of human thinking is often overlooked by mind maps due to a confused understanding of inheritance semantics:
Strong inheritance deals with instances: specialization define subsets and generalization is defined by shared structures and identities.
Weak inheritance deals with specifications: specialization define sub-types and generalization is defined by shared features.
Inheritance semantics: shared structures (dark) vs shared features (white)
The combination of nodes (intension/extension) and inheritance (structures/features) semantics gives cartographers two hands: a free one for creative distinctions, and a safe one for the ensuing complexity. e.g:
Intension and weak inheritance: environments (extension) are partitioned according to regulatory constraints (intension); specialization deals with subtypes and generalization is defined by shared features.
Extension and strong inheritance: cars (extension) are grouped according to motorization; specialization deals with subsets and generalization is defined by shared structures and identities.
Intension and strong inheritance: corporate sub-type inherits the identification features of type Reservation (intension).
Mind maps built on these principles could provide a common thesaurus encompassing the whole of enterprise data, information and knowledge.
Intelligence: Data, Information, Knowledge
Considering that mind maps combine intelligence and cartography, they may have some use for enterprise architects, in particular with regard to economic intelligence, i.e the integration of information processing, from data mining to knowledge management and decision-making:
Data provide the raw input, without clear structures or semantics (terms or aspects).
Categories are used to process data into information on one hand (extensional nodes), design production systems on the other hand (intensional nodes).
Abstractions (concepts) makes knowledge from information by putting it to use.
Conclusion
Along that perspective mind maps could serve as front-ends for enterprise architecture ontologies, offering a layered cartography that could be organized according to concerns:
Enterprise architects would look at physical environments, business processes, and functional and technical systems architectures.
Using layered maps to visualize enterprise architectures
Knowledge managers would take a different perspective and organize the maps according to the nature and source of data, information, and knowledge.intelligence w
Using layered maps to build economic intelligence
As demonstrated by geographic information systems, maps built on clear semantics can be combined to serve a wide range of purposes; furthering the analogy with geolocation assistants, layered mind maps could be annotated with punctuation marks (e.g ?, !, …) in order to support problem-solving and decision-making.
All too often choosing a development method is seen as a matter of faith, to be enforced uniformly whatever the problems at hand.
Tools and problems at hand (Jacob Lawrence)
As it happens, this dogmatic approach is not limited to procedural methodologies but also affect some agile factions supposedly immunized against such rigid stances.
A more pragmatic approach should use simple and robust principles to pick and apply methods depending on development problems.
Iterative vs Phased Development
Beyond the variety of methodological dogmas and tools, there are only two basic development patterns, each with its own merits.
Iterative developments are characterized by the same activity (or a group of activities) carried out repetitively by the same organizational unit sharing responsibility, until some exit condition (simple or combined) verified.
Phased developments are characterized by sequencing constraints between differentiated activities that may or may not be carried out by the same organizational units. It must be stressed that phased development models cannot be reduced to fixed-phase processes (e.g waterfall); as a corollary, they can deal with all kinds of dependencies (organizational, functional, technical, …) and be neutral with regard to implementations (procedural or declarative).
A straightforward decision-tree can so be built, with options set by ownership and dependencies:
Shared Ownership: Agile Schemes
A project’s ownership is determined by the organizational entities that are to validate the requirements (stakeholders), and accept the products (users).
Iterative approaches, epitomized by the agile development model, is to be the default option for projects set under the authority of single organizational units, ensuring shared ownership and responsibility by business analysts and software engineers.
Projects set from a business perspective are rooted in business processes, usually through users’ stories or use cases. They are meant to be managed under the shared responsibility of business analysts and software engineers, and carried out independently of changes in architecture capabilities (a,b).
Agile Development & Architecture Capabilities
Projects set from a system perspective potentially affect architectures capabilities. They are meant to be managed under the responsibility of systems architects and carried out independently of business applications (d,b,c).
Transparency and traceability between the two perspectives would be significantly enhanced through the use of normalized capabilities, e.g from the Zachman’s framework:
Who: enterprise roles, system users, platform entry points.
What: business objects, symbolic representations, objects implementation.
How: business logic, system applications, software components.
When: processes synchronization, communication architecture, communication mechanisms.
Where: business sites, systems locations, platform resources.
It must be noted that as far as architecture and business driven cycles don’t have to be synchronized (principle of continuous delivery), the agile development model can be applied uniformly; otherwise phased schemes must be introduced.
Cross Dependencies: Phased Schemes
Cross dependencies mean that, at some point during project life-cycle, decision-making may involve organizational entities from outside the team. Two mechanisms have traditionally been used to cope with the coordination across projects:
Fixed phases processes (e.g Analysis/Design/Implementation) have shown serious shortcomings, as illustrated by notorious waterfall.
Milestones improve on fixed schemes by using check-points on development flows instead of predefined activities. Yet, their benefits remain limited if development flows are still defined with regard to the same top-down and one-fits-all activities.
Model based systems engineering (MBSE) offers a way out of the dilemma by defining flows directly from artifacts. Taking OMG’s model driven architecture (MDA) as example:
Computation Independent Models (CIMs) describe business objects and activities independently of supporting systems.
Platform Independent Models (PIMs) describe systems functionalities independently of platforms technologies.
Platform Specific Models (PSMs) describe systems components as implemented by specific technologies.
Layered Dependencies & Development Cycles with MDA
Projects can then be easily profiled with regard to footprints, dependencies, and iteration patterns (domain, service, platform, or architecture, …).
That understanding puts the light on the complementarity of agile and phased solutions, often known as scaled agile.
Humans often expect concepts to come with innate if vague meanings before being compelled to withstand endless and futile controversies around definitions. Going the other way would be a better option: start with differences, weed out irrelevant ones, and use remaining ones to advance.
How to keep business rolling (Tamar Ettun)
Concerning enterprise, it would start with the difference between business and architecture, and proceed with the wholeness of data, information, and knowledge.
Business Architecture is an Oxymoron
Business being about time and competition, success is not to be found in recipes but would depend on particularities with regard to objectives, use of resources, and timing. These drives are clearly at odds with architectures rationales for shared, persistent, and efficient structures and mechanisms. As a matter of fact, dealing with the conflicting nature of business and architecture concerns can be seen as a key success factor for enterprise architects, with information standing at the nexus.
Data as Resource, Information as Asset, Knowledge as Service
Paradoxically, the need of a seamless integration of data, information, and knowledge means that the distinction between them can no longer be overlooked.
Data is captured through continuous and heterogeneous flows from a wide range of sources.
Information is built by adding identity, structure, and semantics to data. Given its shared and persistent nature it is best understood as asset.
Knowledge is information put to use through decision-making. As such it is best understood as a service.
Ensuring the distinction as well as the integration must be a primary concern of enterprise architects.
Sustainable Success Depends on a Balancing Act
Success in business is an unfolding affair, on one hand challenged by circumstances and competition, on the other hand to be consolidated by experience and lessons learnt. Meeting challenges while warding off growing complexity will depend on business agility and the versatility and plasticity of organizations and systems. That should be the primary objective of enterprise architects.































{kind=link}