Preamble
Ingrained habits die hard, especially mental ones as they are not weighted down by a mortal envelope. Fear is arguably a primary factor of persistence, if only because being able to repeat something proves that nothing bad has happened before.

Procedures epitomize that human leaning as ordered sequences of predefined activities give confidence in proportion to generality. Compounding the deterministic delusion, procedures seem to suspend time, arguably a primary factor of human anxiety.
Procedures are Dead-ends
From hourglasses to T.S. Elliot’s handful, sand materializes human double bind with time, between will of measurement and fear of ephemerality.
Procedures seem to provide a way out of the dilemma by replacing time with prefabricated frames designed to ensure that things can only happen when required. But with extensive and ubiquitous digital technologies dissolving traditional boundaries, enterprises become directly exposed to competitive environments in continuous mutation; that makes deterministic schemes out of kilter:
- There is no reason to assume the permanence of initial time-frames for the duration of planned procedures.
- The blending of organizations with supporting systems means that architectural changes cannot be carried out top-down lest the whole be paralyzed by the management overheads induced by cross expectations and commitments.
- Unfettered digital exchanges between enterprises and their environment, combined with ubiquitous smart bots in business processes, are to require a fine grained management of changes across artefacts.
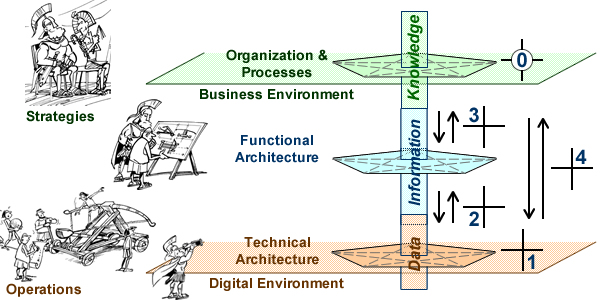
These shifts call for a complete upturn of paradigm: event driven instead of scheduled, bottom-up instead of top-down, model based instead of activity driven.
Declarative frameworks: Non Deterministic, Model Based, Agile
The procedural/declarative distinction has its origin in the imperative/declarative programming one, the principle being to specify necessary and sufficient conditions instead of defining the sequence of operations, letting programs pick the best options depending on circumstances.
Applying the principle to enterprise architecture can help to get out of a basic conundrum, namely how to manage changes across supporting systems without putting a halt to enterprise activities.
Obviously, the preferred option is to circumscribe changes to well identified business needs, and carry on with the agile development model. But that’s not always possible as cross dependencies (business, organizational, or technical) may induce phasing constraints between engineering tasks.
As notoriously illustrated by Waterfall, procedural (if not bureaucratic) schemes have for long be seen as the only way to deal with phasing constraints; that’s not a necessity: with constraints and conditions defined on artifacts, developments can be governed by their status instead of having to be hard-wired into procedures. That’s precisely what model based development is meant to do.
And since iterative development models are by nature declarative, agile and model-based development schemes may be natural bedfellows.
Epigenetics & Emerging architectures
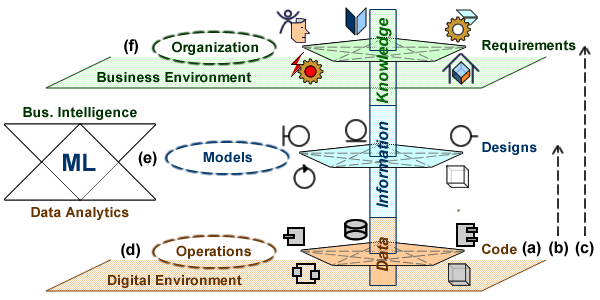
Given their their immersion in digital environments and the primacy of business intelligence, enterprises can be seen as living organisms using information to keep an edge in competitive environments. On that account homeostasis become a critical factor, to be supported by osmosis, architecture versatility and plasticity, and traditional strategic planning.
Set on a broader perspective, the merging of systems and knowledge architectures on one hand, the pervasive surge of machine learning technologies on the other hand, introduce a new dimension in the exchange of information between enterprises and their environment, making room for emerging architectures.
Using epigenetics as a metaphor of the mechanisms at hand, enterprises would be seen as organisms, systems as organs and cells, and models (including source) as genome coded with the DNA.
According to classical genetics, phenotypes (actual forms and capabilities of organisms) inherit through the copy of genotypes and changes between generations can only be carried out through changes in genotypes. Applied to systems, it would entail that changes would only happen intentionally, after being designed and programmed into the systems supporting enterprise organization and processes.

The Extended Evolutionary Synthesis considers the impact of non coded (aka epigenetic) factors on the transmission of the genotype between generations. Applying the same principles to systems would introduce new mechanisms:
- Enterprise organization and their use of supporting systems could be adjusted to changes in environments prior to changes in coded applications.
- Enterprise architects could use data mining and deep-learning technologies to understand those changes and assess their impact on strategies.
- Abstractions would be used to consolidate emerging designs with existing architectures.
- Models would be transformed accordingly.
While applying the epigenetics metaphor to enterprise mutations has obvious limitations, it nonetheless puts a compelling light on two necessary conditions for emerging structures:
- Non-deterministic mechanisms governing the way changes are activated.
- A decrypting mechanism between implicit or latent contents (data from digital environments) to explicit ones (information systems).
The first condition is to be met with agile and model based engineering, the second one with deep-learning.
FURTHER READING
- Digital Transformation & Homeostasis
- Entropy & Homeostasis
- Knowledge-based Models Transformation
- Focus: Data vs Information
- Squaring Software To Value Chains
- Value Chains & EA
- Redeeming Conceptual Debts
- EA Capacity & Maturity
- Feasibility & Capabilities
- Agile Architectures: Versatility meets Plasticity
- EA: Maps & Territories
- Projects Have to Liaise